URL
https://arxiv.org/pdf/2008.01232.pdf
TL;DR
- 本文将 bert 模型结构用于多帧动作识别网络的末尾的时间信息融合部分,在 HMDB51 和 UCF101 两个 Action Recognition 数据集上目前仍是 SOTA
Algorithm
一句话总结本文的主要工作:SOTA - TGAP + BERT = NEW SOTA
之前 Action Recognition 常用的网络结构
1. 3D Conv + TGAP
- 将连续多帧视频一起送入网络,使用 3D Conv 或 C(2 + 1)D 降维时间与空间,升维 Channel
- 使用 TGAP (temporal global average pooling ) (
torch.nn.AdaptiveAvgPool3d) 对时间空间一起全局平均池化到一个 scalar,然后 Channel 维做 FC 分类
2. 3D Conv + GAP + LSTM
- backbone 部分与 1 相似
- 对时空 feature map 使用 GAP,保留时间维度的特征,使用 LSTM 等结构处理时间序列,输出 FC 分类
3. 基于 2D Conv + 时序 等
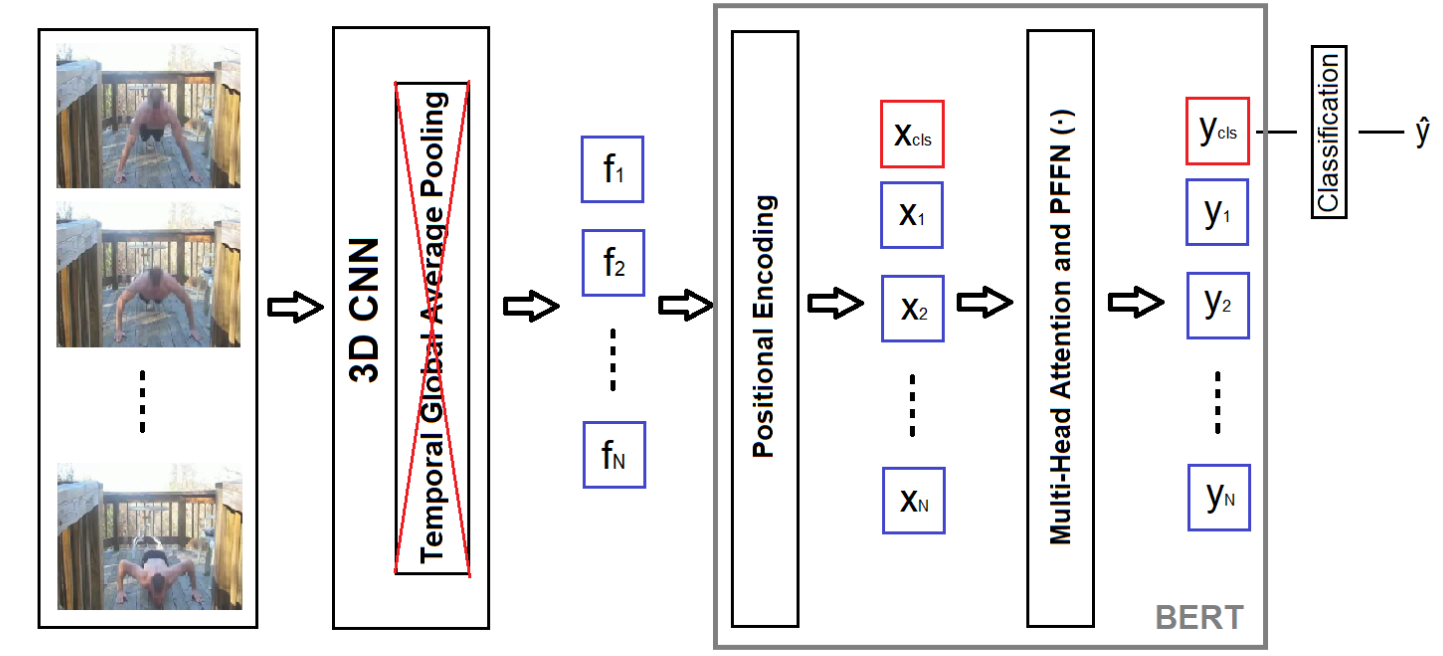
本文网络结构
- 本文认为 TGAP 会丢失很多时序信息,GAP + LSTM 效果也不好
- 在末尾使用 GAP + BERT 是一个较好的选择,并只对 Transformer 的 ClassToken 监督
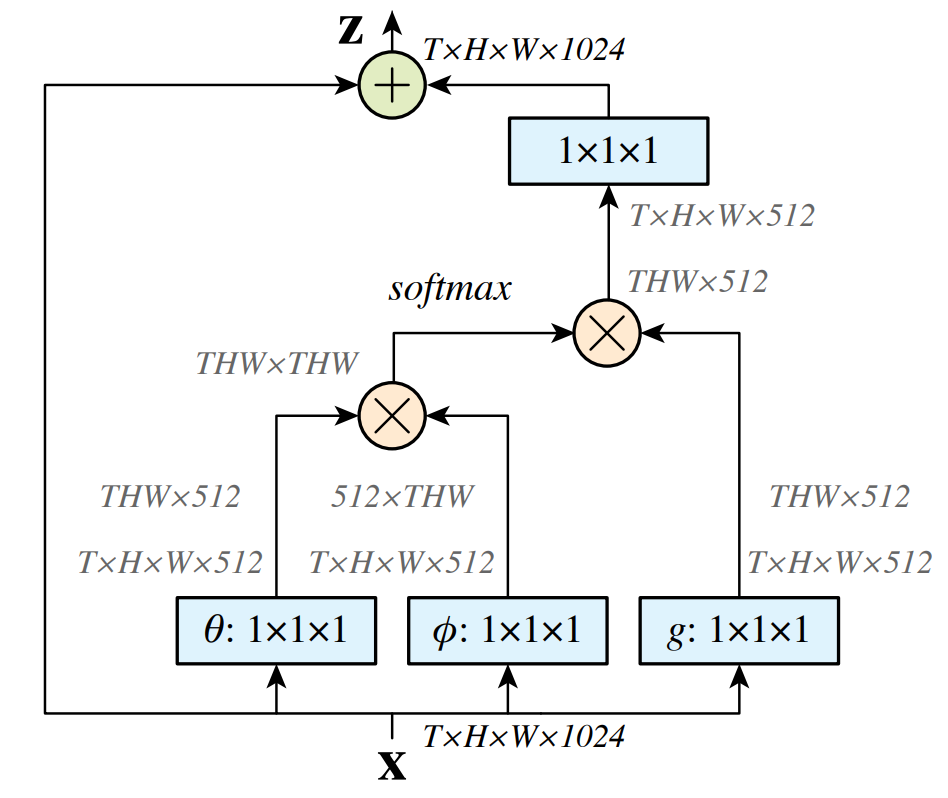
对 Transformer 一个有趣的解释
Transformer 的数学表达式:
其中:
PFFN: Position-wise Feed-forward Networ- ,其中 都是 projection function (FC)
- 如果 都变成 1 × 1 × 1 Conv,那 Transformer 就变成了 non-local ,所以用 BERT 处理图像序列就非常合理了…
baseline
- 本文选取的 baseline 是 Action Recognition 经典的网络结构 R(2 + 1)D 和 SlowFastNet
对 R(2 + 1)D 网络的改进
R(2 + 1)D - TGAP + 1层 BERT = R(2 + 1)D_BERT,目前 HMDB51 和 UCF101 上的 SOTA
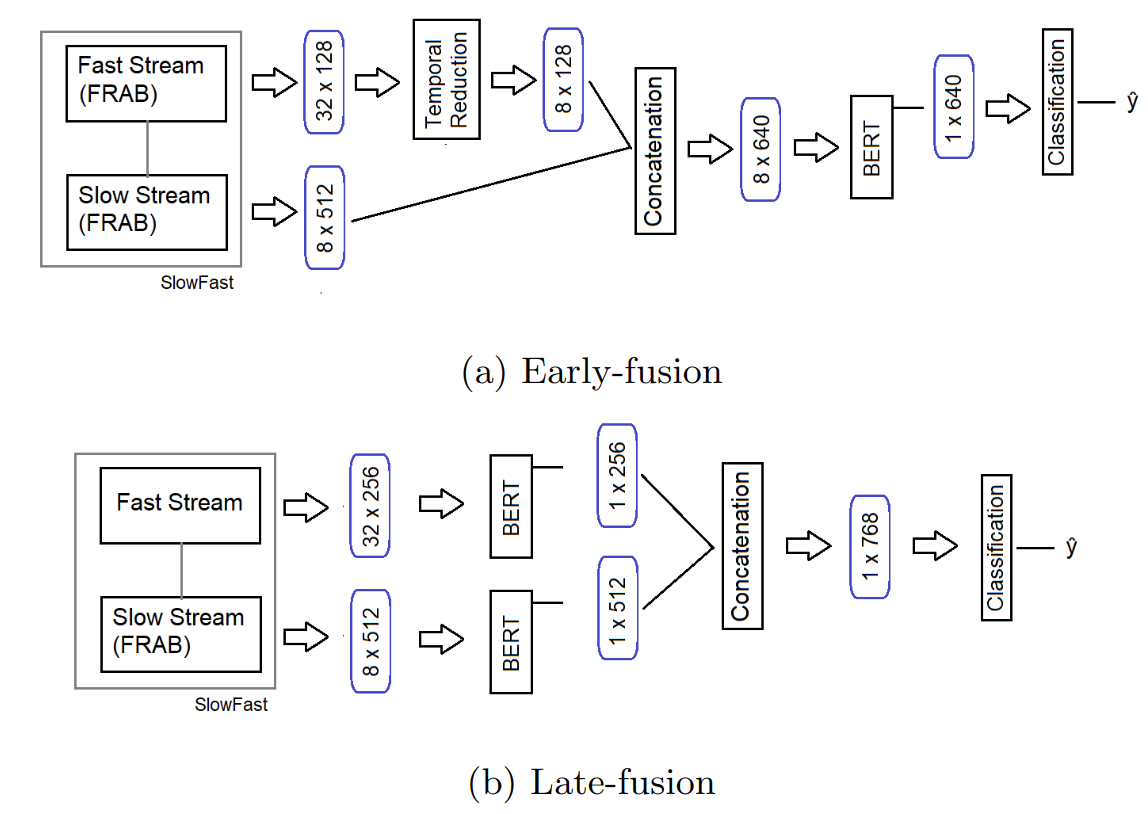
对 SlowFastNet 的改进
- BERT 的后融合实现: SlowFastNet 的两路序列各自经过 BERT 再 Concat 比 Concat 后再 BERT 效果好…
对比实验
- 作者做了非常完善的对比实验,包括是否使用光流信息,是否在backbone尾部降维,Transformer 用几层几个 head 等,详细见 paper
Thoughts
- 关于 BERT 与 Non-local 的关系还是挺有趣的