URL
https://arxiv.org/pdf/2006.04768.pdf
TL;DR
- 本方法——
Linformer 使用矩阵的低秩来降低原始 Transformer 的 Multi-HEAD Attention 计算的时空复杂度
- 不同
Transformer 结构的复杂度

Algorithm
headi=Attention(QWiQ,KWiK,VWiV)=softmax[dkQWiQ(KWiK)T]VWiV
其中: K,Q,V∈Rn×dm WiQ,WiK∈Rdm×dk
所以: softmax[dkQWiQ(KWiK)T]∈Rn×n ,n 表示序列长度,所以原始 Transformer 使用的 Multi-HEAD Attention 的时空复杂度为 O(n2)
- 将 KWiK,VWiV∈Rn×dk 投影到 EiKWiK,FiVWiV∈Rk×dk ,其中
k 是一个常数,时空复杂度变成了 O(n) ,其中,E、F 都是可学习的投影矩阵, E,F∈Rk×n
- headiˉ=Attention(QWiQ,EiKWiK,FiVWiV)=softmax[dkQWiQ(EiKWiK)T]FiVWiV
- 投影矩阵
E、F 可共享参数,分为:
- Headwise sharing: Ei=E, Fi=F, for each layer
- Key-value sharing: Ei=E=Fi, for each layer
- Layerwise sharing: E,F, layer sharing
理论依据与结果
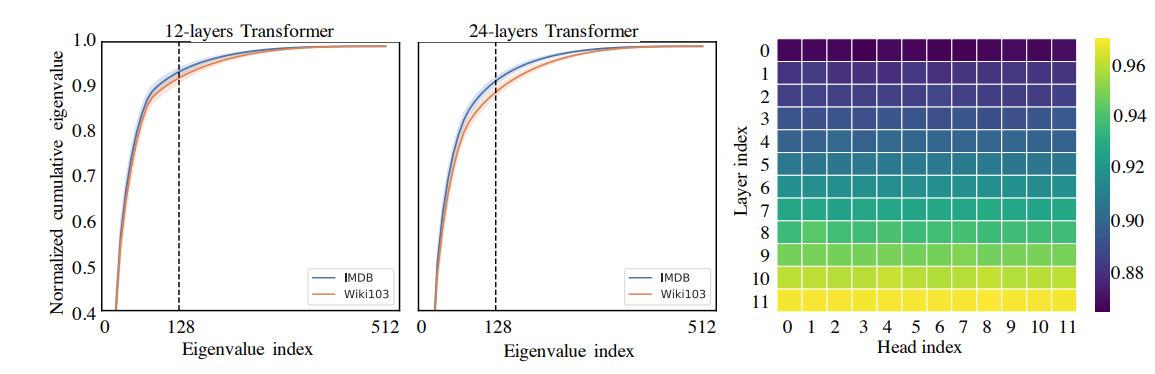
- 特征值的长尾分布
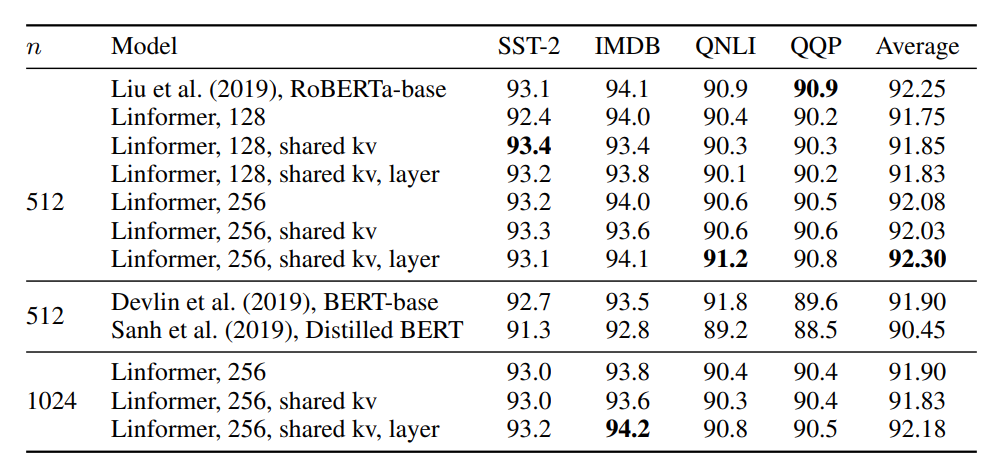
- 效果(与 BERT-base 对比)
Thoughts
- 文中提到不使用奇异值分解来得到低秩矩阵的原因是:奇异值分解会引入额外的计算量,并且无法共享参数
- 代码被打包为了
linformer 的 pip 包,可以在 torch 框架下直接使用