URL
https://arxiv.org/pdf/2105.01883.pdf
TL;DR
- 本文提出一种 MLP 的重参数结构,训练过程中在 MLP 中构建多个 Conv branch,Inference 过程中,将多个 Conv branch 吸收到 MLP 中,不额外增加 MLP 的推理速度
Algorithm
总体结构
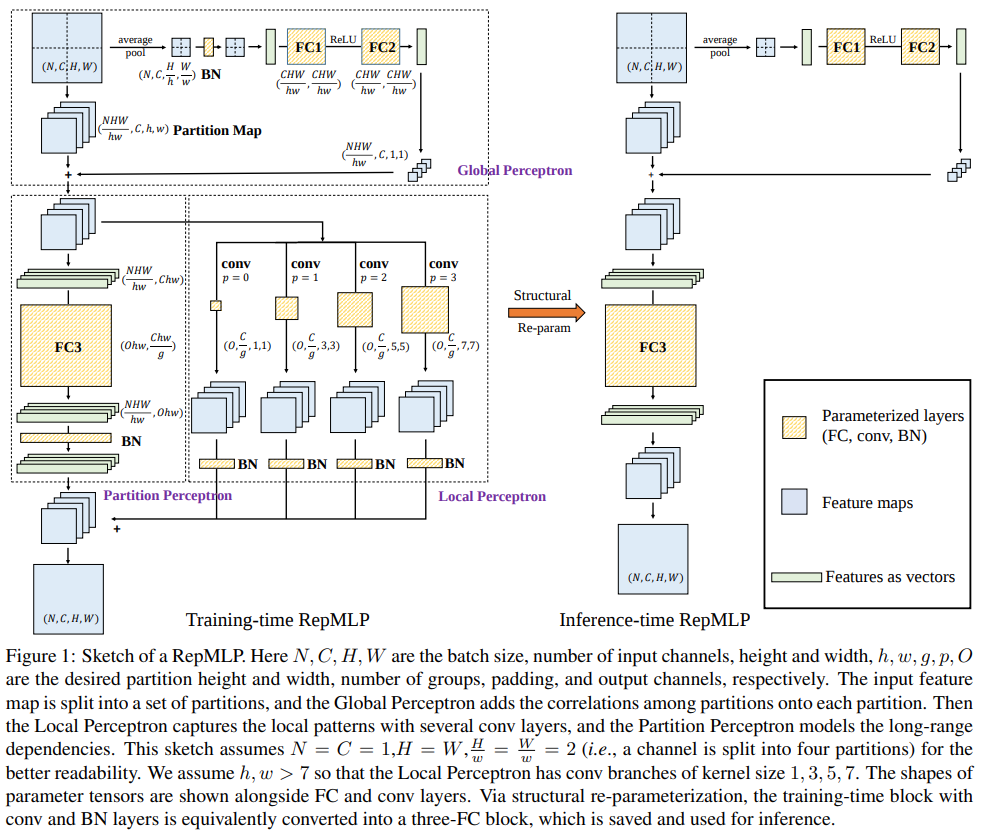
结构分解
Global Perceptron
为了减小 MLP 恐怖的参数量,作者提出将 的 feature map 通过:
这种Reshape -> Transpose -> Reshape的方式缩小分辨率,这种方法的问题在于 patch 之间的关联关系被打破,所以需要一个作用于Global的 patch 权重,类似于 patch 版的SENet,不同之处在于这里没有使用SENet的Per-channel Scale而是只用了Per-channel BiasPartion Perceptron
FC 本体,由于 MLP 的参数过于恐怖,所以这里的 FC 需要二次降参数,做法是Group FCLocal Perceptron
使用了多个 branch 的 Conv,提取Global Perceptron的输出 feature map,目的是局部特征提取,弥补 MLP 局部特征提取的短板,也就是题目的来源
Inference
Inference时,重参数主要是两个方面:- FC 吸 BN
- FC 吸 Conv
结果
- 从消融实验来看,三种
Perceptron中除了Partion Perceptron作为 FC 本体无法消融之外,重要程度:local Perceptron>Global Perceptron - 和 Wide ConvNet 对比 Flops 较小但精度较低,所以需要和 Conv 结合使用,结合方式是:
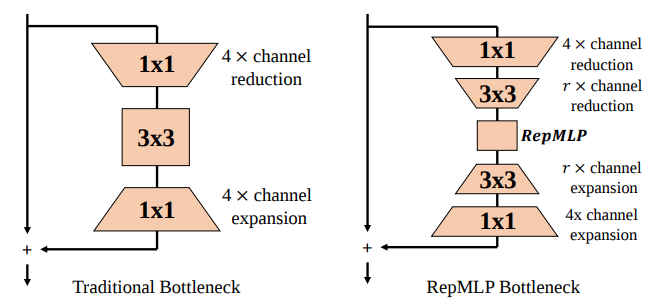
Thoughts
- 重参数过程中
Global Perceptron只吸了一个 BN,感觉有点亏,而且Global Perceptron这个分支的存在让整个RepMLP变得没有像RepVGG一样优雅 - 如果
Global Perceptron的作用是建立 patch 之间的关联,可不可以把 这个过程变成类似 PixelShuffle upscale_factor < 1 的剪 patch 方法(可能效率会比文中方法低),每个 patch 信息分布相似,无需建立 patch 间的全局关系,是否可以省掉Global Perceptron分支,那样的话,Inference 过程就只有一个 FC 了