URL
https://arxiv.org/pdf/2007.00649.pdf
TL;DR
- 传统的集成学习能提高算法效果,但是深度学习多
model集成学习实在是太慢了 - 所以作者提出一种深度学习多
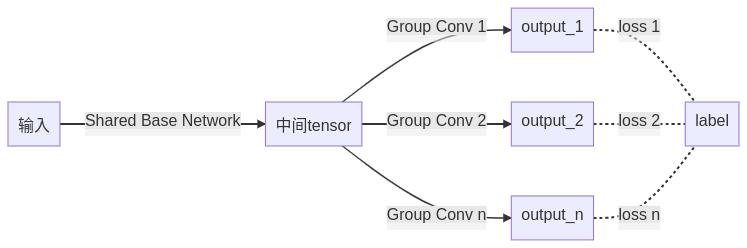
group集成学习,本质是在网络的末尾处使用 分组卷积,分成多路,每一路独立监督,监督得到的loss加权求和 作为总loss,然后反向传播、优化,优点是:理论上不产生额外计算量 - 加权求和的方式一共有三种,分别是
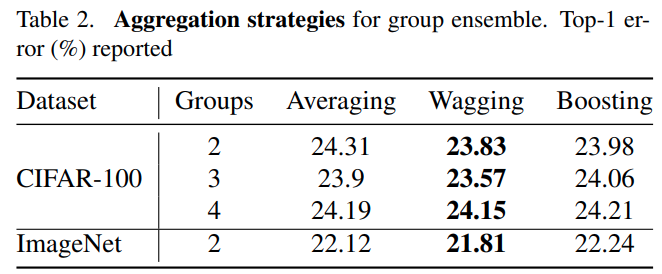
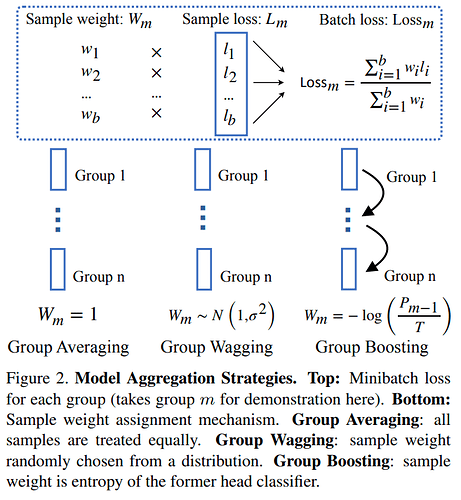
Group Averaging、Group Wagging、Group Boosting
Algorithm
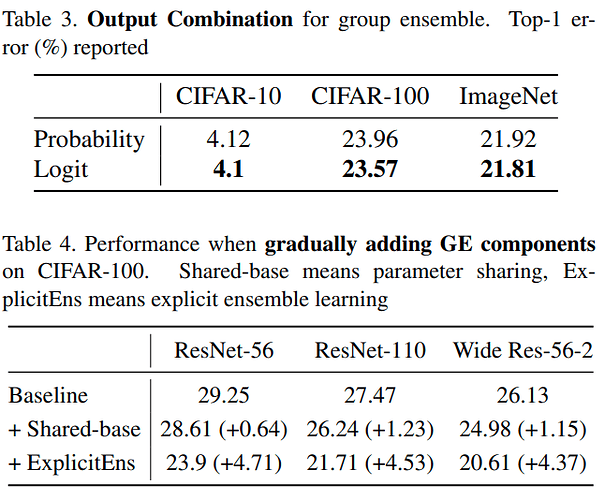
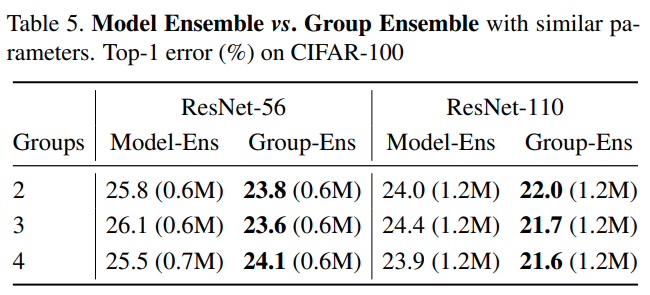
Group Ensemble 与 Model Ensemble 的区别
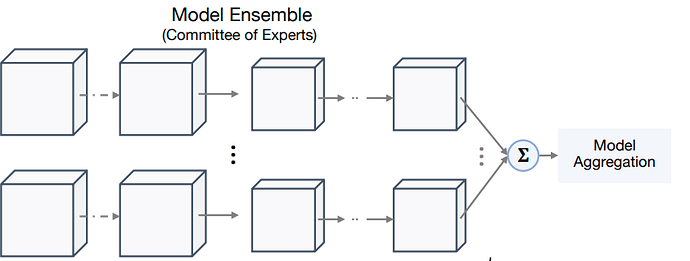
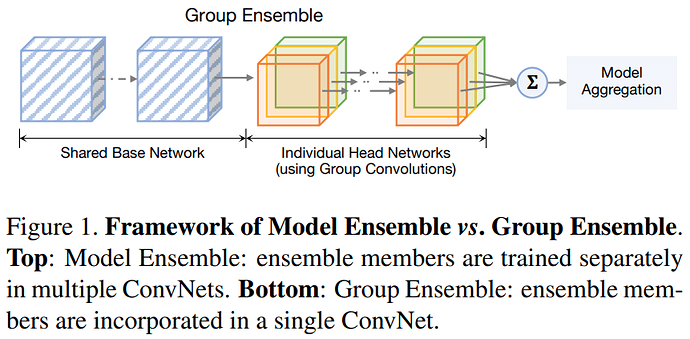
网络结构
加权方式
- , 表示第
i个分支上的损失, 表示对应权重 Group AveragingGroup WaggingGroup Boosting-
- 其中
T表示 温度,类似于模型蒸馏时的蒸馏温度 - 表示上一个分支算对的概率
- 即上一个分支预测的越正确,本分支的权重就越小,这与
boosting还真的有点像
- 其中
-
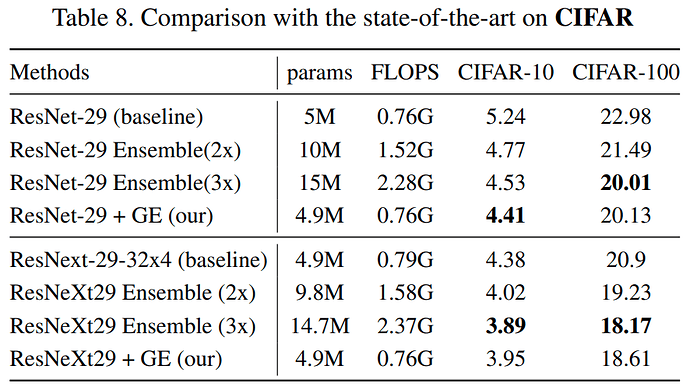
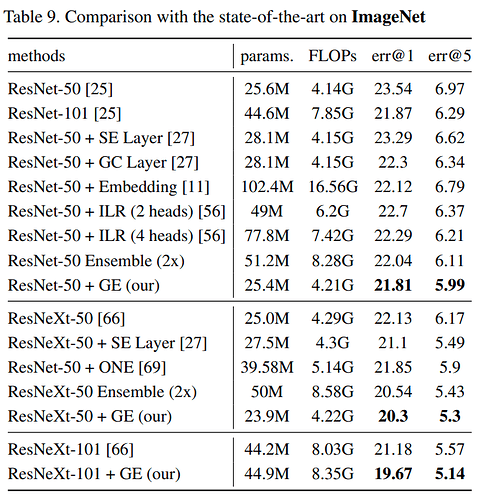
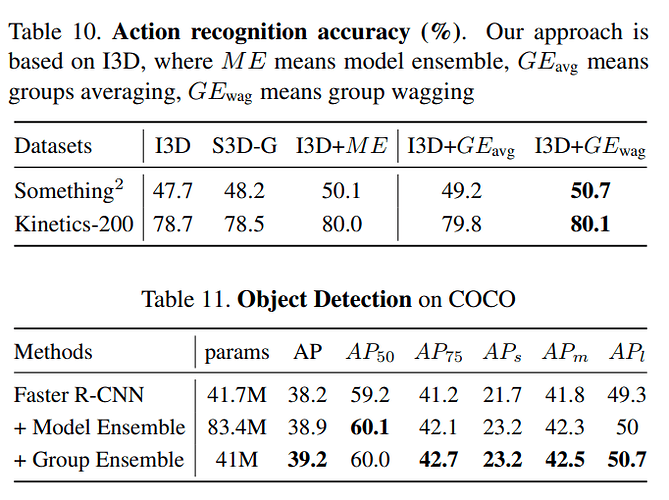
最终效果
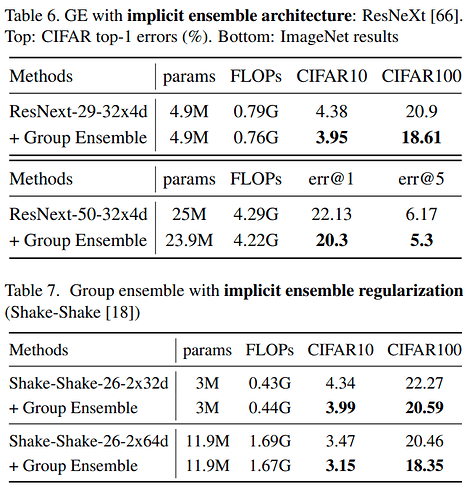
ImageNet数据集上,top-1 error比ResNeXt-50降低了 1.83%- 几乎不改变
Flops和params,在几乎所有网络上使用都会有明显提升 - 在多种任务中都能提高成绩,包括:
- 目标检测
- 动作识别
- 图像识别
Thoughts
Group Boosting这种串行计算loss权重的方法确定在inference阶段不会影响速度?- 为什么在
CIFAR数据集上,Group Wagging这种随机方法反而效果好
对比表格