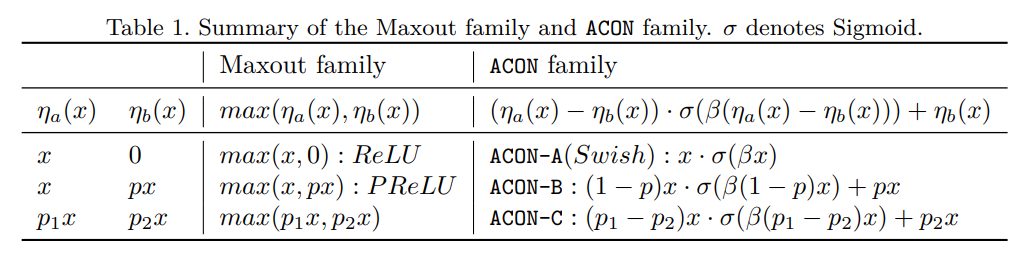
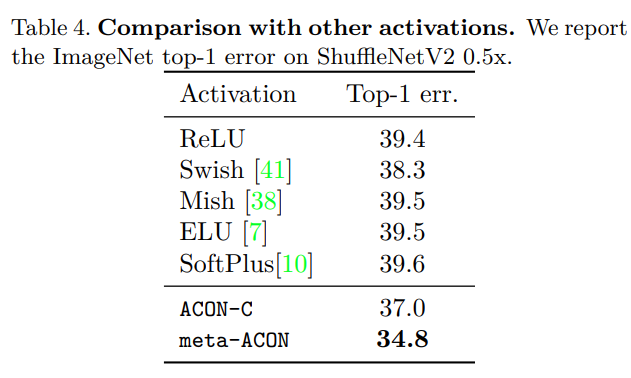
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| import torch
from torch import nn
class AconC(nn.Module):
r"""ACON activation (activate or not).
# AconC: (p1*x-p2*x) * sigmoid(beta*(p1*x-p2*x)) + p2*x, beta is a learnable parameter
# according to "Activate or Not: Learning Customized Activation" <https://arxiv.org/pdf/2009.04759.pdf>.
"""
def __init__(self, width):
super().__init__()
self.p1 = nn.Parameter(torch.randn(1, width, 1, 1))
self.p2 = nn.Parameter(torch.randn(1, width, 1, 1))
self.beta = nn.Parameter(torch.ones(1, width, 1, 1))
def forward(self, x):
return (self.p1 * x - self.p2 * x) * torch.sigmoid(
self.beta * (self.p1 * x - self.p2 * x)
) + self.p2 * x
class MetaAconC(nn.Module):
r"""ACON activation (activate or not).
# MetaAconC: (p1*x-p2*x) * sigmoid(beta*(p1*x-p2*x)) + p2*x, beta is generated by a small network
# according to "Activate or Not: Learning Customized Activation" <https://arxiv.org/pdf/2009.04759.pdf>.
"""
def __init__(self, width, r=16):
super().__init__()
self.fc1 = nn.Conv2d(
width, max(r, width // r), kernel_size=1, stride=1, bias=True
)
self.bn1 = nn.BatchNorm2d(max(r, width // r))
self.fc2 = nn.Conv2d(
max(r, width // r), width, kernel_size=1, stride=1, bias=True
)
self.bn2 = nn.BatchNorm2d(width)
self.p1 = nn.Parameter(torch.randn(1, width, 1, 1))
self.p2 = nn.Parameter(torch.randn(1, width, 1, 1))
def forward(self, x):
beta = torch.sigmoid(
self.bn2(
self.fc2(
self.bn1(
self.fc1(
x.mean(dim=2, keepdims=True).mean(dim=3, keepdims=True)
)
)
)
)
)
return (self.p1 * x - self.p2 * x) * torch.sigmoid(
beta * (self.p1 * x - self.p2 * x)
) + self.p2 * x
|