URL
https://arxiv.org/pdf/2004.02803.pdf
TL;DR
- Deformable 3D 简称 D3D,是 C3D 的 Deformable 版
- 在视频超分中引入了可变形3D卷积,看上去很合理
- 使用的超分网络结构很简单,与 VDSR 有一点相似
Dataset/Algorithm/Model/Experiment Detail
Algorithm
1. D3D:3D 卷积的可变形版本(或者说可变性卷积的3D版)
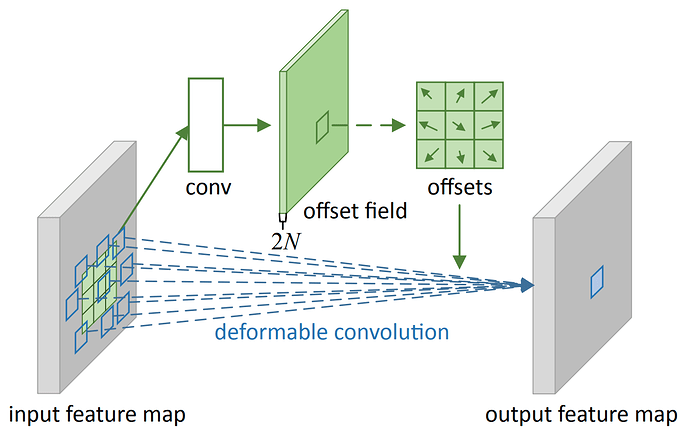
可变形2D卷积全过程(图来自论文Deformable Convolutional Networks)
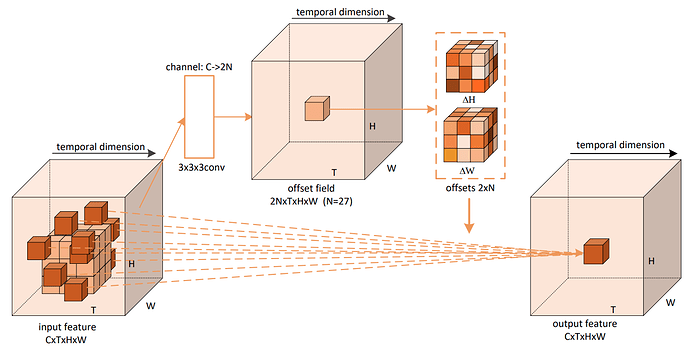
可变形3D卷积全过程 (图来自本论文)您这也太像了吧
C3D计算过程:
其中 表示卷积核中心所在feature上的位置, 表示卷积核到中心偏移,由于是C3D所以, ,
D3D计算过程
表示到卷积核到原始位置的偏移, 表示卷积核到中心偏移
2. 超分网络结构
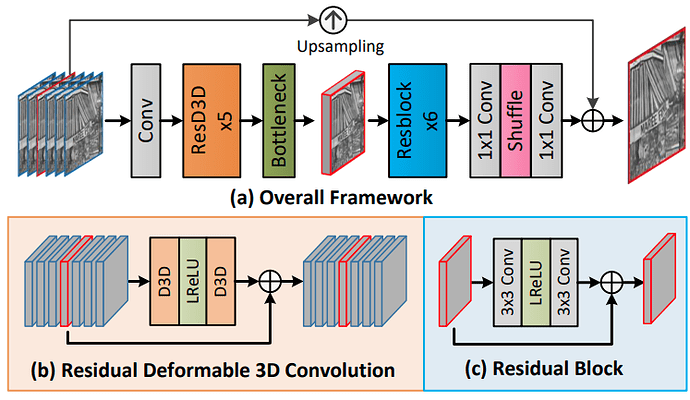
图中’Conv‘表示C3D,3x3 Conv表示2D Conv
输入:连续 3 / 5 / 7 frames
Thoughts
- 对比了C3D和D3D的效果,说明D3D还是有点用的
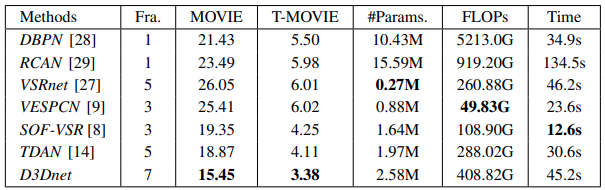
- 与EDVR对比可知,即使D3D单个算子再强大,网络设计也十分重要!
- 速度好慢,flops好大
- 脑补C3D的DConv作者会由衷的说一句:优(jiu)秀(zhe?)
3. 算法效果对比
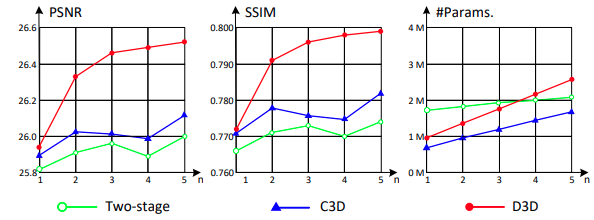

输入帧数与算法效果的关系:
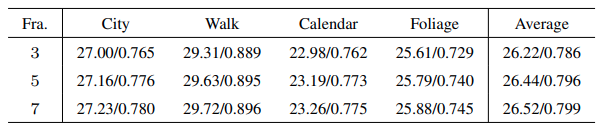

为什么不和paperswithcode里的VSR模型比一比?
Vid4数据集上:

论文中对比结果巧妙的避开了前五(截图于 2020-08-01),优秀