URL
https://arxiv.org/pdf/1809.02966.pdf
TL;DR
- 提出一种端到端的可训练的优化方法,通过近似 Hessian 优化方法,解决非线性最小二乘法问题
- 从训练数据中隐式的学习正则化与先验信息
- 第一个将可学习的优化器用于单目视觉光度误差估计任务中
Algorithm
背景知识
非线性最小二乘法求解
- 最小二乘法问题: E=21∑jrj2(x), rj(x) 表示 x 第 j 项的 L1 误差
- 常用方法:
Gauss-Newton (GN)、Levenberg-Marquadt (LM)
- 求解过程:
- 对误差进行一阶估计: r(xi+Δxi)=r(xi)+JiΔxi, Ji=dxdr∣x=xi ,J 是雅各比矩阵
- 最优变化量: Δxi=argΔximin21∣∣ri+JiΔxi∣∣2
GN 法获得最优变化量: JiTJiΔxi=−JiTri ,如果 JiTJi 可逆,则最优变化量 Δxi=−(JiTJi)−1JiTriLM 法获得最优变化量(在 GN 的基础上加入超参数—— 阻尼系数 λ): Δxi=−(JiTJi+λ diag(JiTJi))−1JiTri- 本方法:基于
GN 加入了更多的可学习参数,使用梯度下降优化
任务描述
- 输入一段图像序列,输出深度估计(depth)与姿态估计(pose),为了估计较大范围的深度,所以网络实际估计深度的倒数: z=d1
- 所以本任务优化目标函数: E(x)=21∣∣r(x)∣∣2, x=(z,p)
网络结构
网络结构包含 bootstrap network、iterative network、refinement network
bootstrap network: 生成低分辨率( 4H,4W )的粗糙估计(一个简单的包含下采样的CNN)iterative network:重复迭代与细化,本文使用 LSTM (非线性最小二乘法优化也用于此处)refinement network:上采样(双线性插值法)

iterative network 优化过程

- 其中 fθ0 表示
bootstrap network, fθ 表示 Convolutional LSTM Cell
- 由于
J 具体空间局部性,所以这里使用的 LSTM 是 Convolutional LSTM
- [Δxihi+1]=LSTMcell(Φ(Ji,ri),hi,xi;θ), xi+1=xi+Δxi ,这里的 xi 并不是真的输入到 LSTM 中,如
Algorithm 1 所示, xi 用来产生 Ji 从而产生 Φ(Ji,ri)
- 其中雅各比矩阵的变形 Φ(Ji,ri)=[JTJ,r]
- 理论上 Φ(Ji,ri)=[(JTJ)−1J,r] ,但由于求逆会引入较大的计算量,并且不会产生额外的信息量,所以简化 Φ(Ji,ri)=[JTJ,r]
- 由于雅各比矩阵是稀疏的,所以使用了下图的方法对 JTJ 进行了压缩
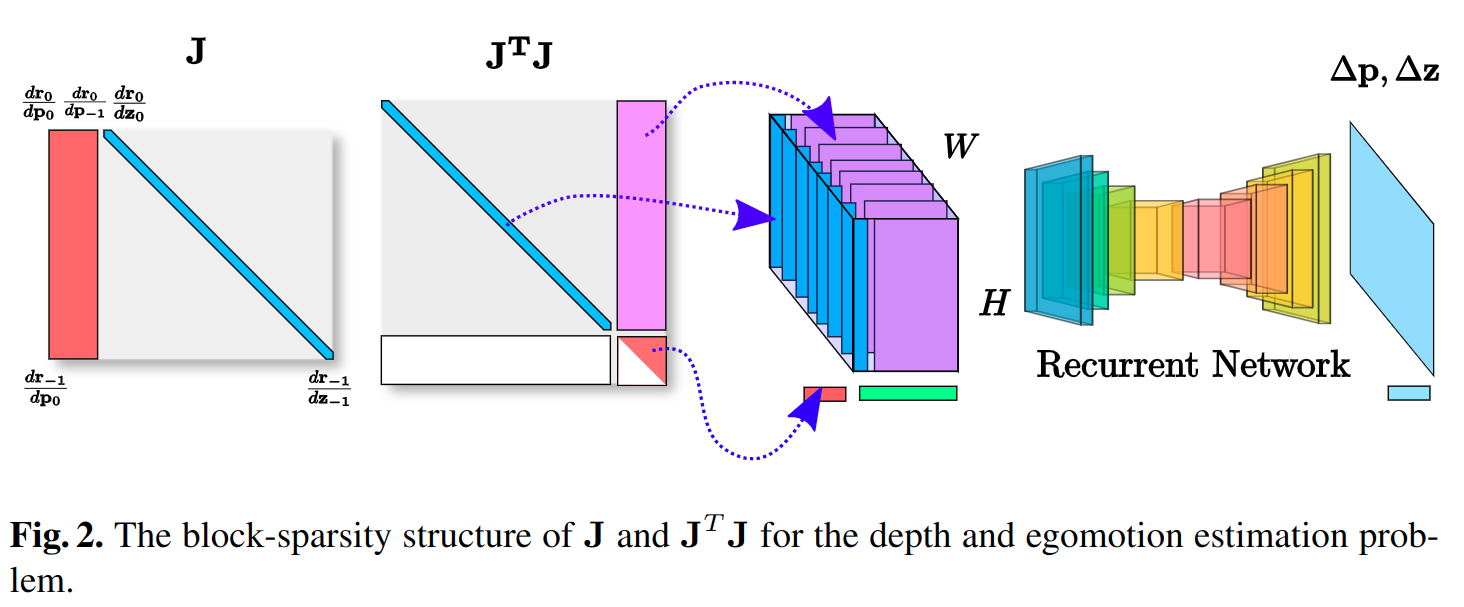
损失函数
Thoughts
- 本文的创新点在于
Convolutional LSTM 中输入的不是 xi ,而是压缩后的二阶雅各比矩阵,用来拟合 Δxi ,可以通过近似 GN 法,产生超一阶优化的效果
GN : Δxi=−(JiTJi)−1JiTri ,本文: Δxi=LSTM(JiTJi,ri) ,即把 [(JiTJi)−1Ji,ri]−−>[JiTJi,ri] 并加入了 LSTM 梯度下降优化- 本文的网络没有官方开源,也找不到民间实现,所以对网络的细节不是特别明白