URL
https://dl.acm.org/doi/pdf/10.1145/3219819.3220007
TL;DR
- 本文提出一种多任务神经网络结构,称为
Multi-gate Mixture-of-Experts简称MMOE - 与传统多任务网络共享 bottom 相比,该结构可以在 任务相关性较弱 的情况下有较好的鲁棒性
MMOE中的Multi-gate本质就是一种Softmax Attention,针对不同的任务给出不同的专家组合
Algorithm
总体网络结构
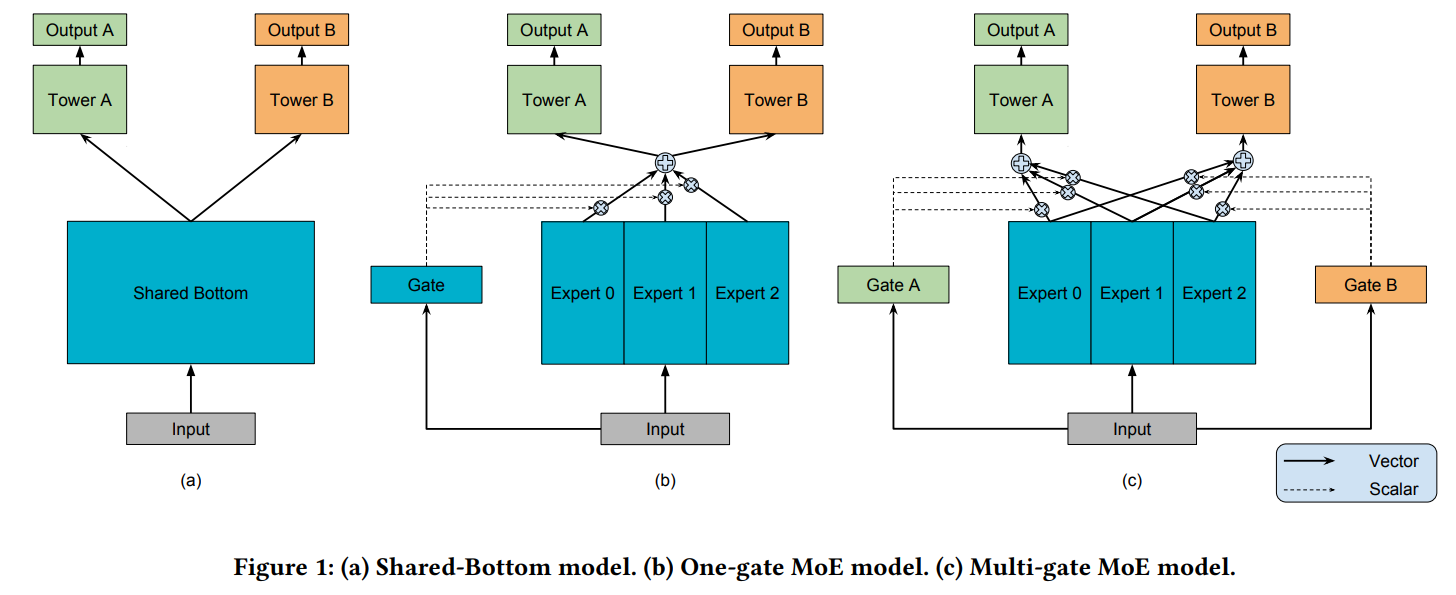
其中
A和B分别表示两个 任务,Tower表示与任务相关的金字塔头部,Expert表示专家 bottom network,Gate表示任务相关的权重生成网络
- 上图 a 表示 Bottom Shared Architecture: 传统共享 bottom network 的多任务结构,共享 bottom network (Backbone) 进行特征提取,将提取到的特征分别送入任务相关头部,缺点是如果任务
A和B之间的相关性较弱,那么共用一个Backbone是危险的 - 上图 b 表示 One-gate Mixture-of-Experts Architecture,有多个
Expert做Backbone进行不同维度的特征提取,只有一个Gate network用于给每个任务生成Expert 权重 - 上图 c 表示 Multi-gate Mixture-of-Experts Architecture,有多个
Expert做Backbone进行不同维度的特征提取,每个任务有单独的Gate network生成唯一的Expert 权重
数学定义
-
Bottom Shared
其中 表示 任务数, 表示 shared bottom, 表示 第 k 个任务的 Tower
-
OMOE
, where
其中 表示 专家数, 表示 Gate network(由于 要经过 Softmax,使得 logits -> prob,所以 ) -
MMOE
, where
,其中
与 OMOE 不同之处在于: 每个任务有单独的 Gate network,不共享
Thoughts
- 是有效的优化,针对任务相关性差的多任务场景,确实能有效涨点
- 本质是一种参数的堆砌,没看到很创新的点
- 除了堆参数之外,还有一个很致命的问题,每个
Gate以及Expert都是独立的,实际实现过程中只能使用for loop依次计算,效率很低,速度很慢
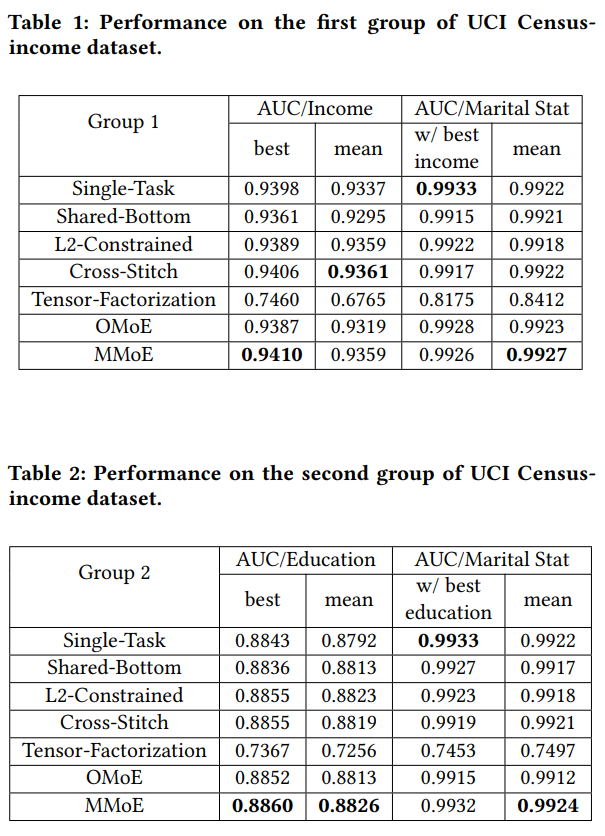
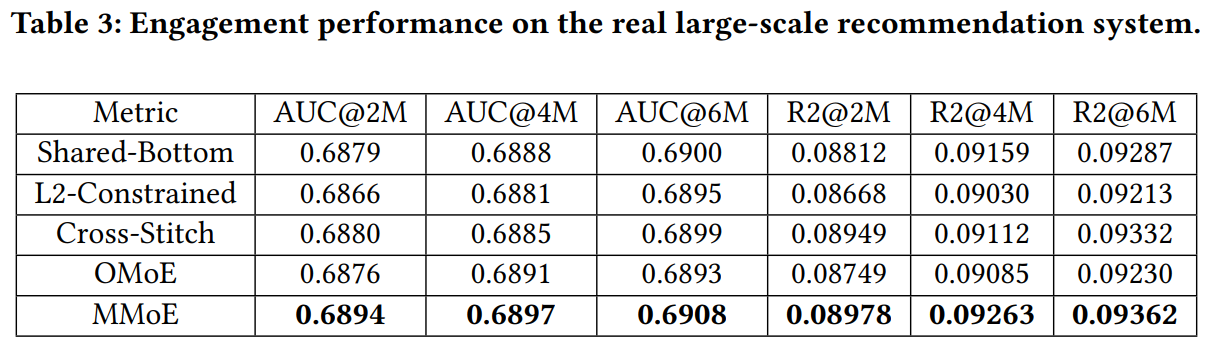
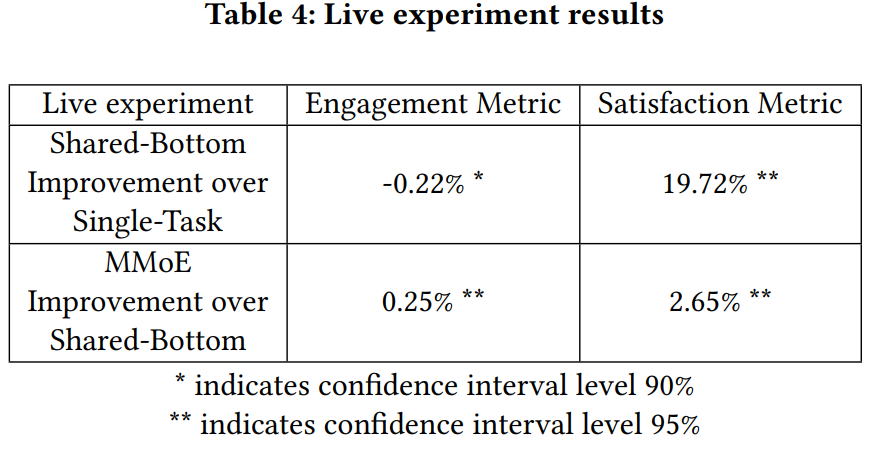
Experiments