URL
https://arxiv.org/pdf/2103.16788.pdf
TL;DR
- 本文提出一种 动态可扩展表征增量学习方法,目前是增量学习的 SOTA
- 提出一种两阶段(表征学习阶段 和 分类学习阶段)的增量学习方法,更好的平衡 stability-plasticity (稳定性与可塑性)
Algorithm
问题定义
- Dt 表是第 t 次增量学习的数据集,Mt 表示第 t 次增量学习前的模型(已隐含前 t-1 次增量学习的所有数据),现可获得的所有数据 D~t=Dt∪Mt,用 D~t 去训练一个新的模型(表征器 + 分类器)
整体结构
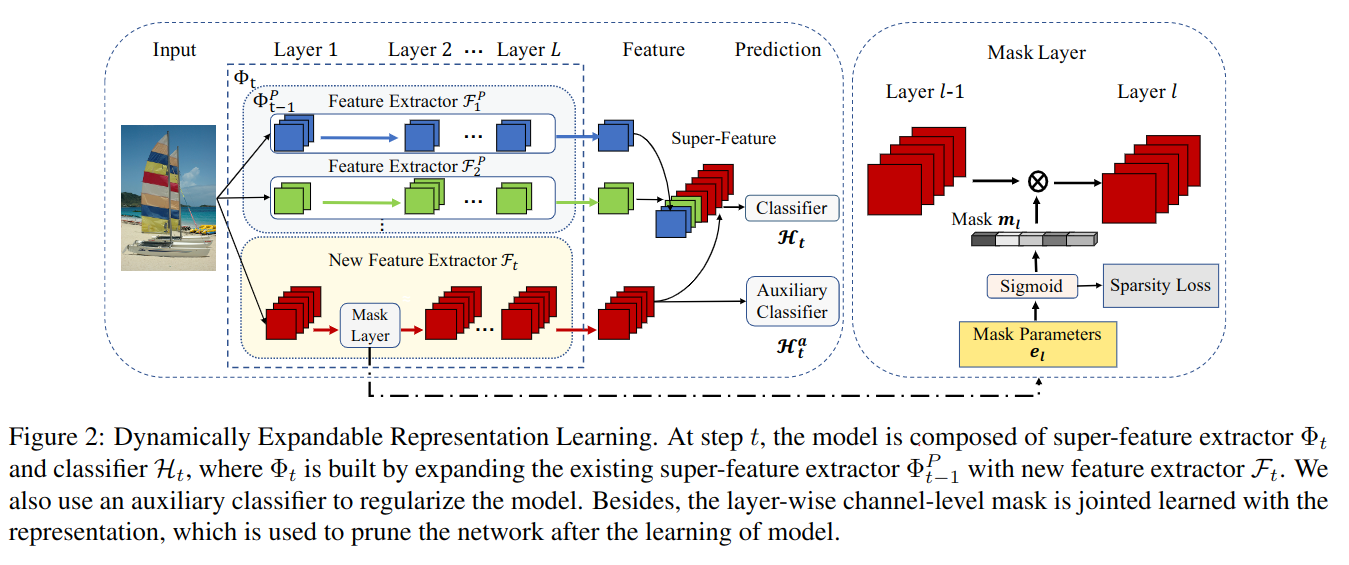
表征学习阶段
- 目的:为 D~t 训练一个表征器(特征提取器)
- 具体做法:冻结(
eval 模式)已有的表征器;为新的增量数据训练一个表征器;两个表征器结果 concat 作为新的表征结果
- u=Φt(x)=[Φt−1(x),Ft(x)],其中,x∈Dt,Φt−1 表示已有的(前 t-1 次增量数据训练的)表征器,Ft 表示为第 t 次增量数据训练的表征器,二者结果
concat 即为新的表征结果 u
分类器学习阶段
- 由于新加入数据 Dt 后,特征 u 的维度和数据分布都发生了变化,所以需要重新训练一个分类器
- y^=argmaxPHtPHt(y∣x)=softmax(Ht(u)),其中 Ht 表示第 t 次增量学习训练的分类器
算法细节
Training Loss
- LHt=−∣D~t∣1∑i=1∣D~t∣log(PHt(y=yi∣xi)),根据新的表征 u 训练
- 辅助 loss:LHta=−∣D~t∣1∑i=1∣D~t∣log(PHta(y=yi∣xi)),只训练新表征器 Ft
- 二者加权相加即为可扩展表征损失函数: LER=LHt+λαLHta
动态扩展
- 加入了
Channel-level Masks
- 加入了稀疏正则化:
Sparsity Loss
- 可扩展表征损失函数加上稀疏正则化即为最终损失函数: LER=LHt+λαLHta+λsLS
表现
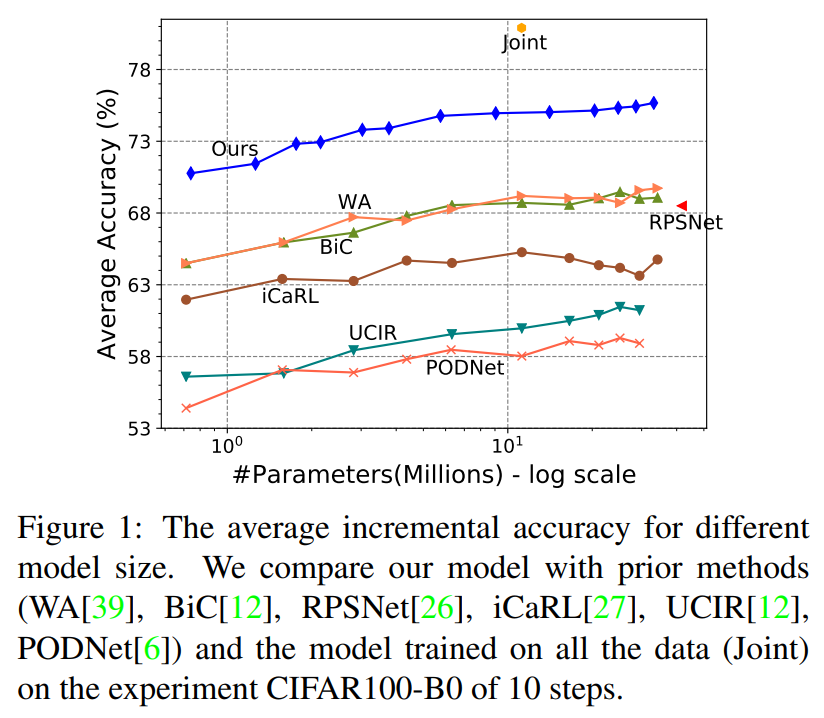
Thought
- 正如题目所说,这种增量学习只适用于类别增量,不适用于数据增量,对于类别固定,数据为流式数据(例如:每日回流的数据)并不适用
- 不适用于流式数据的原因是:这种方法随着增量次数变大,模型会变得越来越大,不适合流式数据这种频繁更新的数据