URL
TL;DR
- 本文提出一种高效的
Channel Attention算法,与SENet相比,效果更好,参数量与计算量更低
Algorithm
网络结构
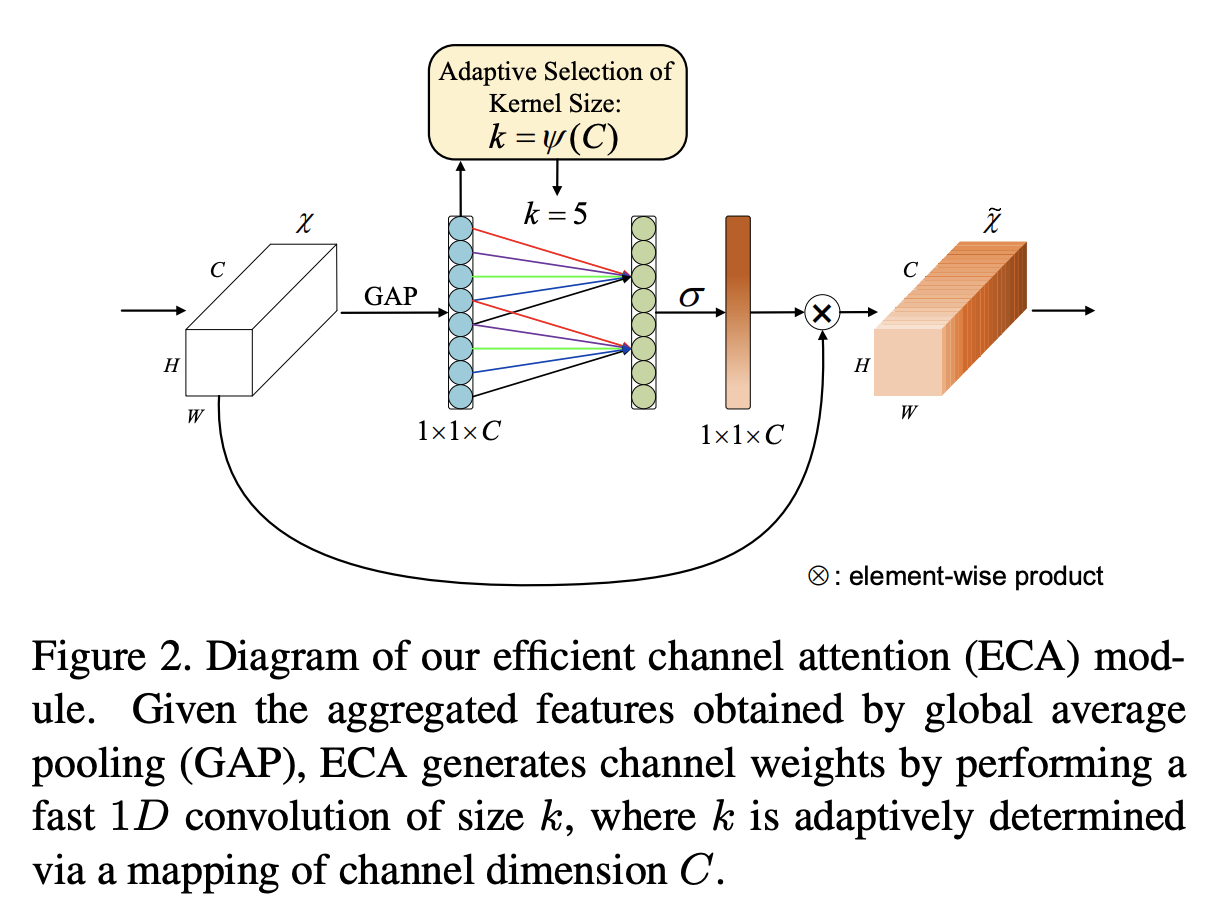
- 与
SENet结构的区别:- 两层 FC 变成一层 FC
- FC 权重稀疏(
kernel_size = k 的 1D Conv)
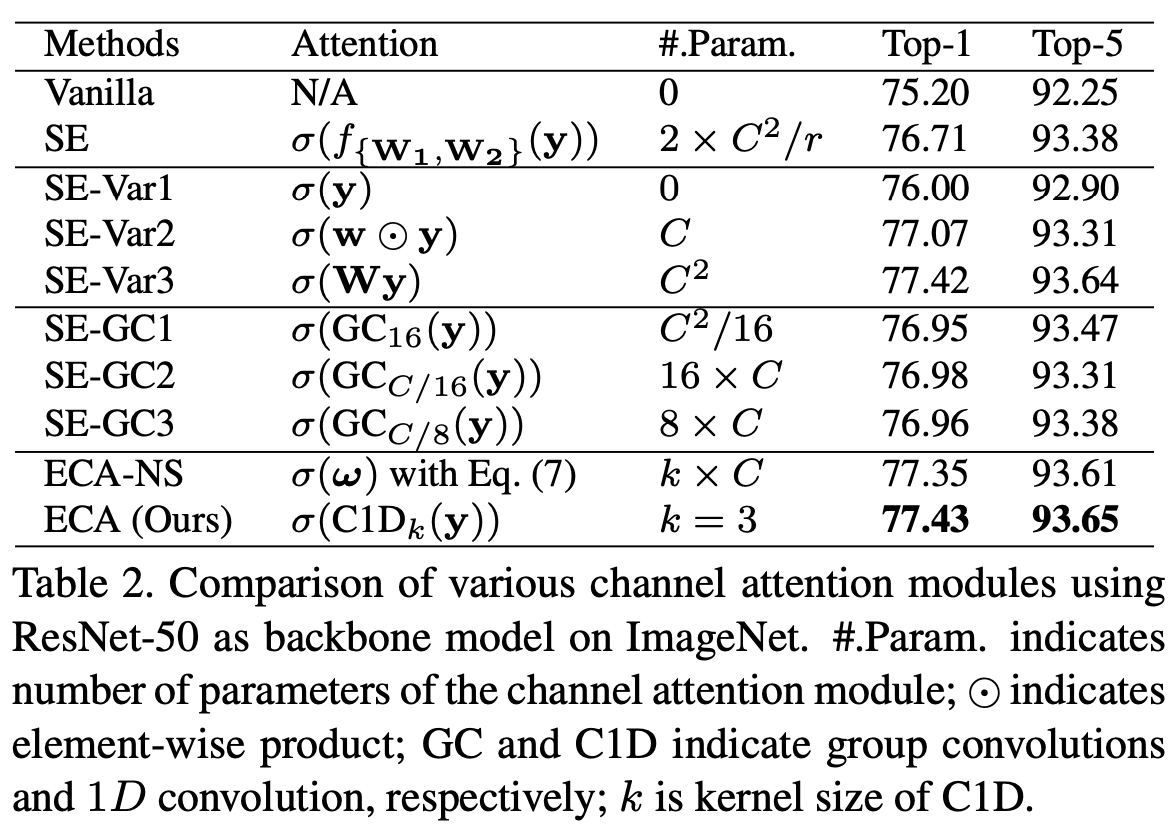
对比实验
- 本文将
ECA-Net与以下Channel Attention Block进行了对比,目的是:如何对 FC 稀疏可以使得模型最终效果最好SENet:Squeeze and Excitation NetworkSE-Var1:SE 变种 1SE-Var2:SE 变种 2SE-Var3:SE 变种 3SE-GC1:SE 通道分组 1SE-GC2:SE 通道分组 2SE-GC3:SE 通道分组 3ECA-NS:ECA-Net 的动态版
- 数学表示
SENet- Channel-wise Attention Weight:,记
- 参数个数:
SE-Var- Channel-wise Attention Weight:
SE-Var1: 是一个 单位矩阵,参数个数:1SE-Var2: 是一个 对角矩阵,参数个数:SE-Var3: 是一个 普通矩阵,参数个数:
SE-GC- 是一个 分块对角矩阵,每个块边长 ,对角线包含 个块,一共包含非零元素(参数个数): 个
SE-GC1和SE-GC2和SE-GC3的区别只是 的取值不同
ECA-NS- 是一个 阶梯状矩阵,每行连续 个非零元素,阶梯状叠加 行,参数个数:
ECA-NetECA-NS中每行元素都一样的特例,参数量:
代码表示

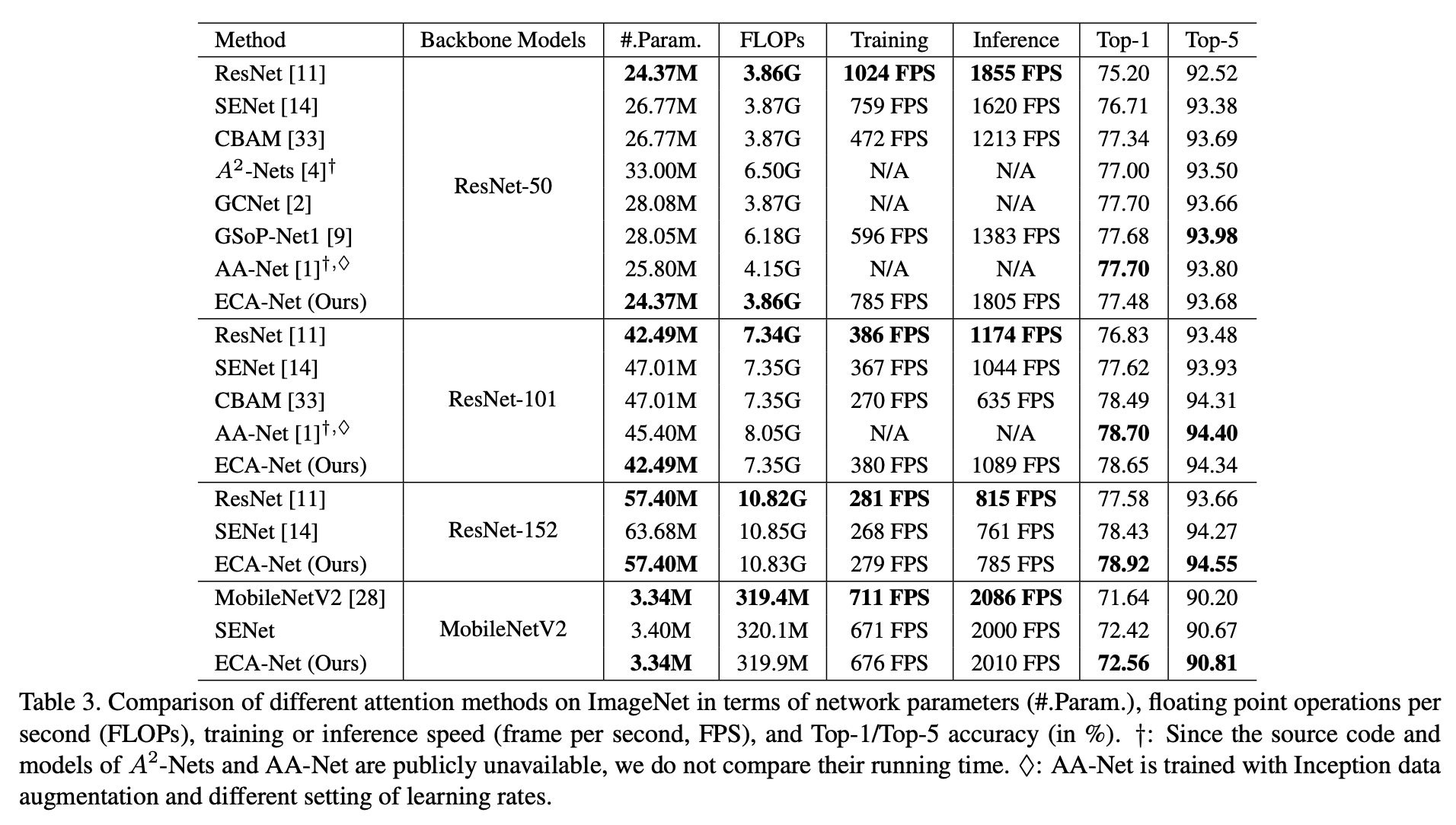
对下游任务的提升
- ImageNet 分类
- COCO 目标检测
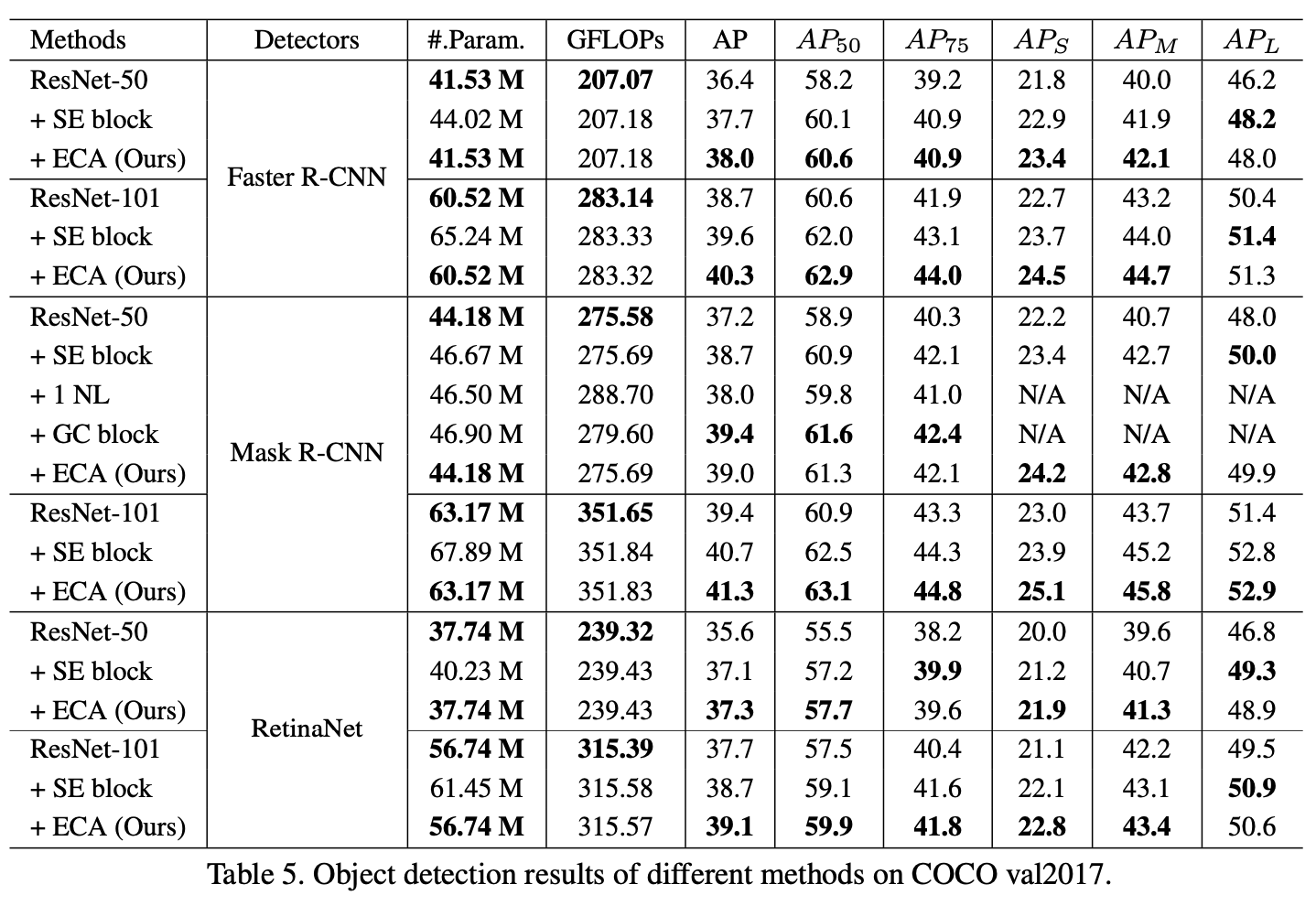
- COCO 实例分割
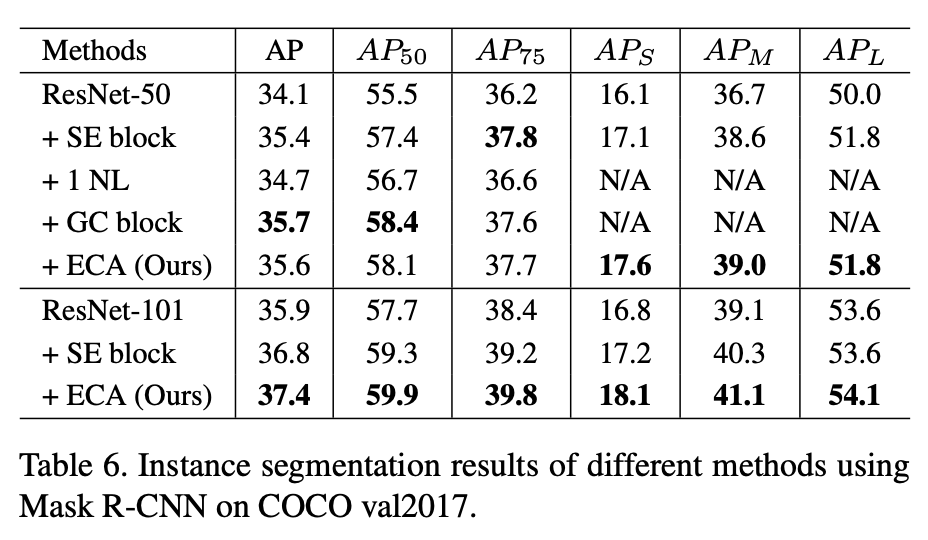
Thought
SE-Net的简化版,但参数量与计算量都更小- 但是性能比
SE-Net更好这个结论感觉不太 make sense