URL
https://arxiv.org/pdf/2105.02358.pdf
TL;DR
- 本文提出一种
Multi-Head External Attention 使用两层全连接层和两个 normalization 层替代 transformer 的 attention 层,以降低计算复杂度
- 提出一种
DoubleNorm 标准化层替代 attention 中的 softmax 层
- 在一些任务中没有超越
transformer 达到 SOTA,只是提出一种关于 attention 的思考
Algorithm
网络结构
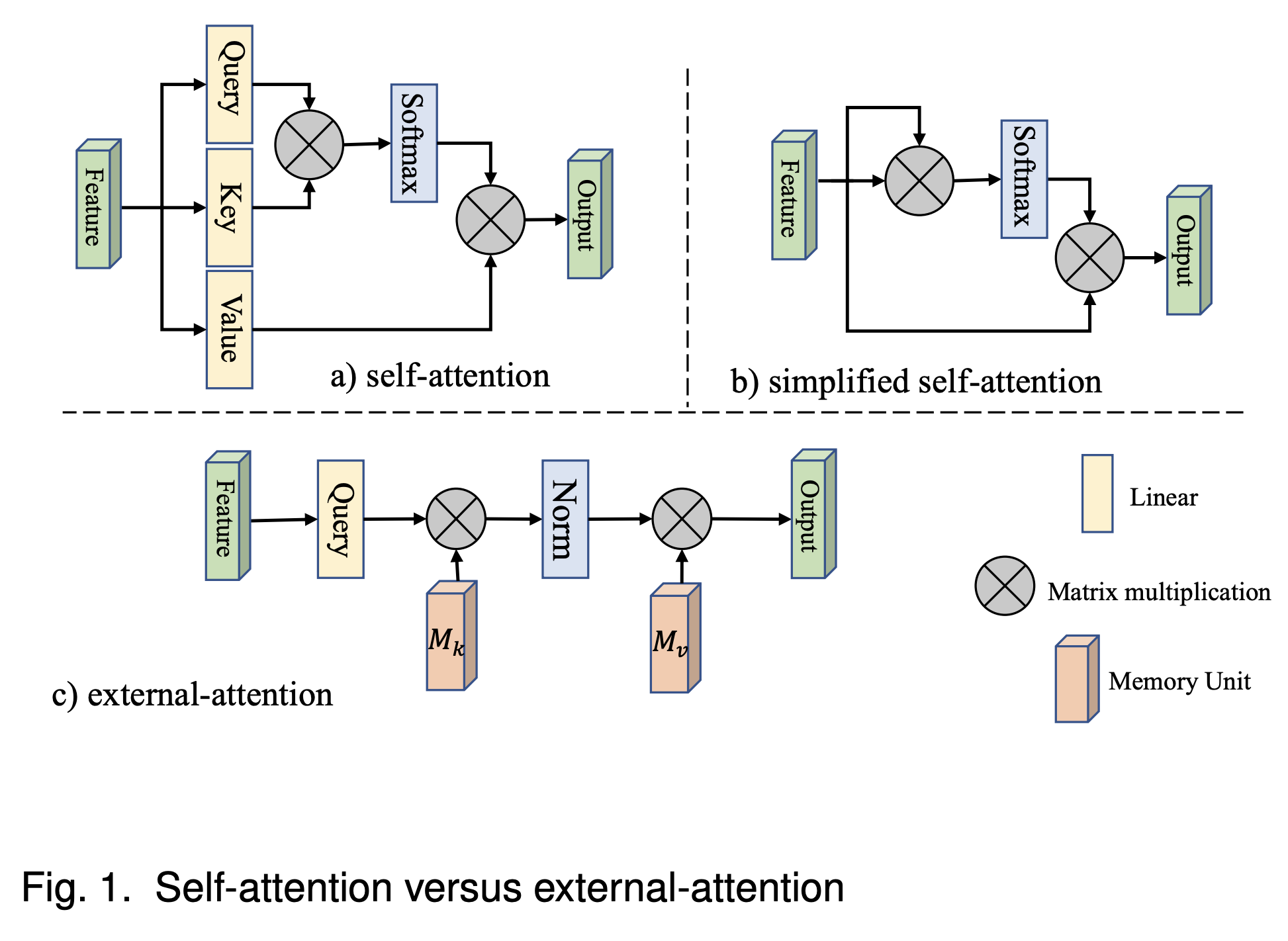
external attention 对比 self attention
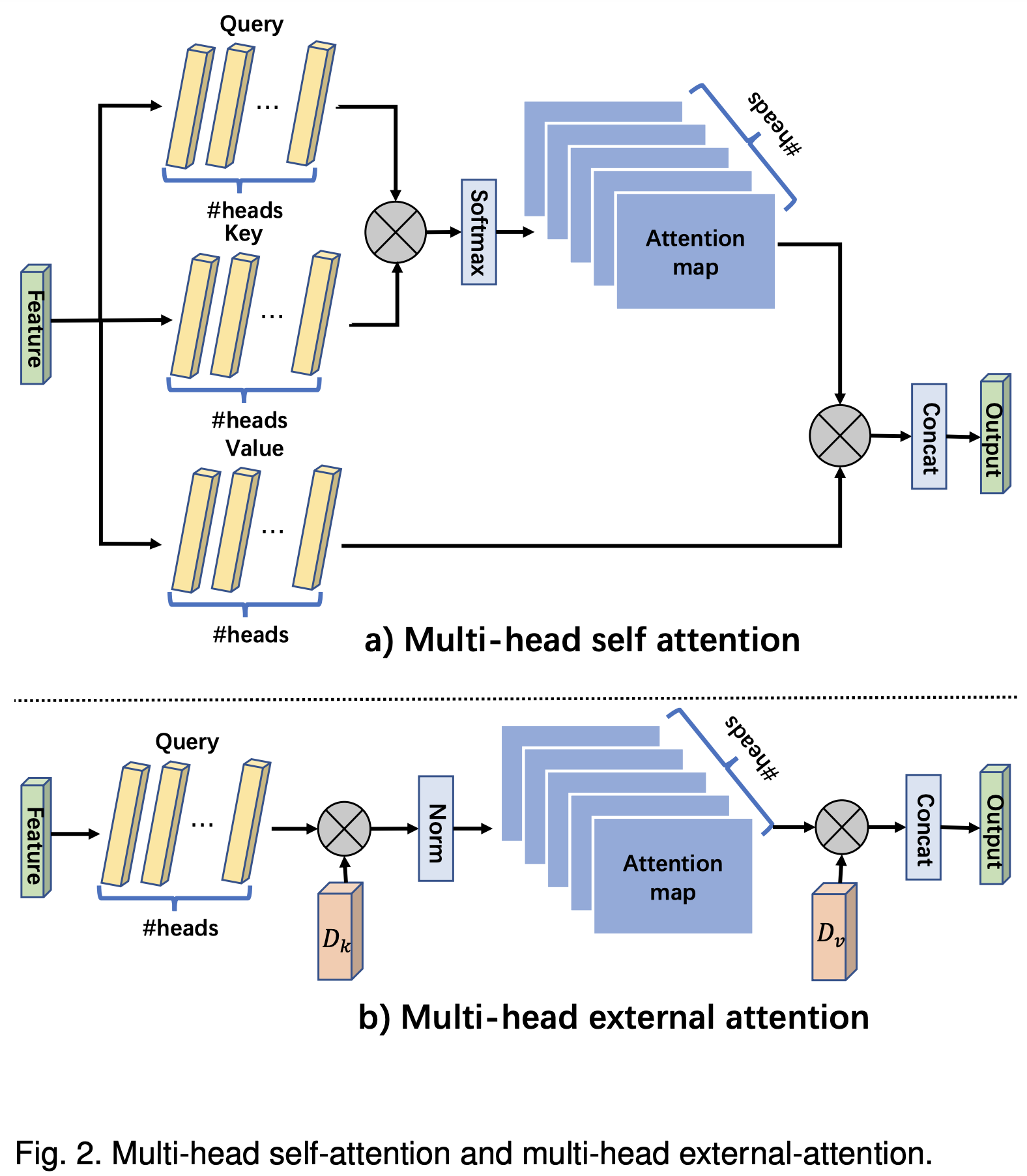
multi-head external attention 对比 multi-head self attention
数学表示与伪代码表示
- self attention
A=(α)i,j=softmax(QKT), (⋅) means matrix
Fout=AV
其中:
F∈RN×d 表示输入,Q=FW1,K=FW1,V=F,W1∈Rd×d′
Q∈RN×d′,K∈RN×d′,A∈RN×N
Fout∈RN×d 表示输出
- 简化 self attention
A=(α)i,j=softmax(FFT)
Fout=AV
- external attention
A=(α)i,j=Norm(FMT)
Fout=AM
以上两步可以共享 MLP 权重,M∈RS×d,也可以不共享,分成 Mk、Mv
计算复杂度 O(dSN)
伪代码表示:

- multi-head external attention
hi=ExternalAttention(Fi,Mk,Mv)
Fout=MultiHead(F,Mk,Mv)=Concat(h1,...,hH)Wo
伪代码表示:

- DoubleNorm
本文提出一种 double-normalization 结构,先在第一维做 softmax,再在第二维做 average
(α~)i,j=FMkT
α^i,j=exp(α~i,j)/∑kexp(α~k,j)
αi,j=α^i,j/∑kα^i,k
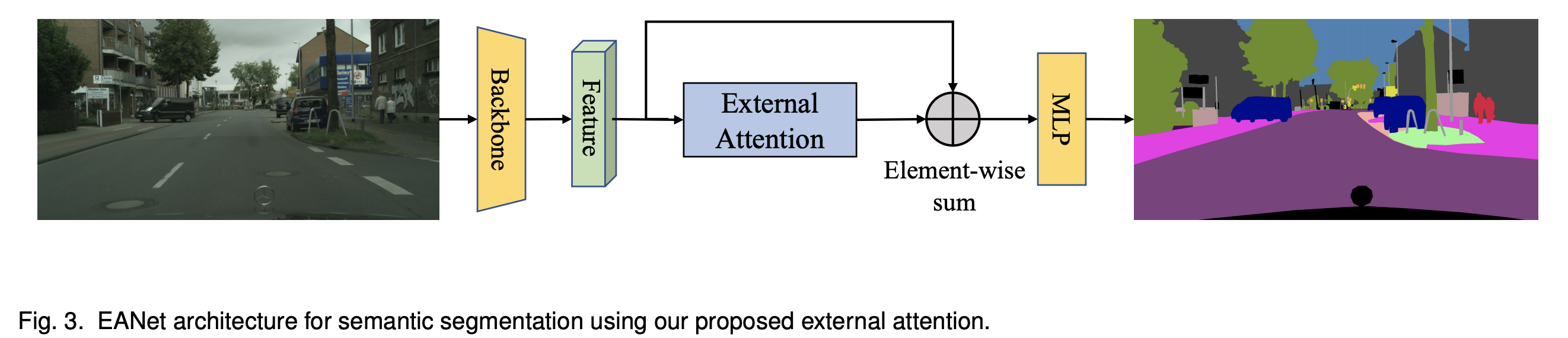
EA 结构用法示例
External Attention 和 DoubleNorm 的消融实验

算法表现
- 本文中对
EANet 与其他网络结构在不同任务上的对比实验做的非常详细,建议去看原文
Thought
- 在一些任务上超越了
self-attention 并不能说明 external attention 结构优于 self-attention 结构
- 在参数量较小的情况下,
external attention 结构可带来较多增益
本文更像是对 《Attention is all you need》 的嘲讽之作