URL
TL;DR
- 一种 用于语义理解的预训练深层双向
transformer,任务相关的 fine-tuning 即可 SOTA BERT全称:Bidirection Encoder Representation from Transformer- 使用 无标签文本 进行预训练,自监督预训练的方法包括:
masked language model:预测被遮挡的词的 token(不需要重建整个句子)next sentence prediction:预测两个句子是否是前后相连的关系(只需预测 是 或者 否)
Algorithm
自监督语义表征方法
- 自监督语义表征方法常用的监督方法有两种:
- feature based:任务相关的预训练
- fine-tuning:在预训练过程中增加任务相关参数,预训练结束后只需要替换这些任务相关参数,在任务数据上有监督 end-to-end fine-tuning 很少 step 即可
- 相较于 GPT 的 left -> right 单向语义结构,双向语义结构对下游任务更友好
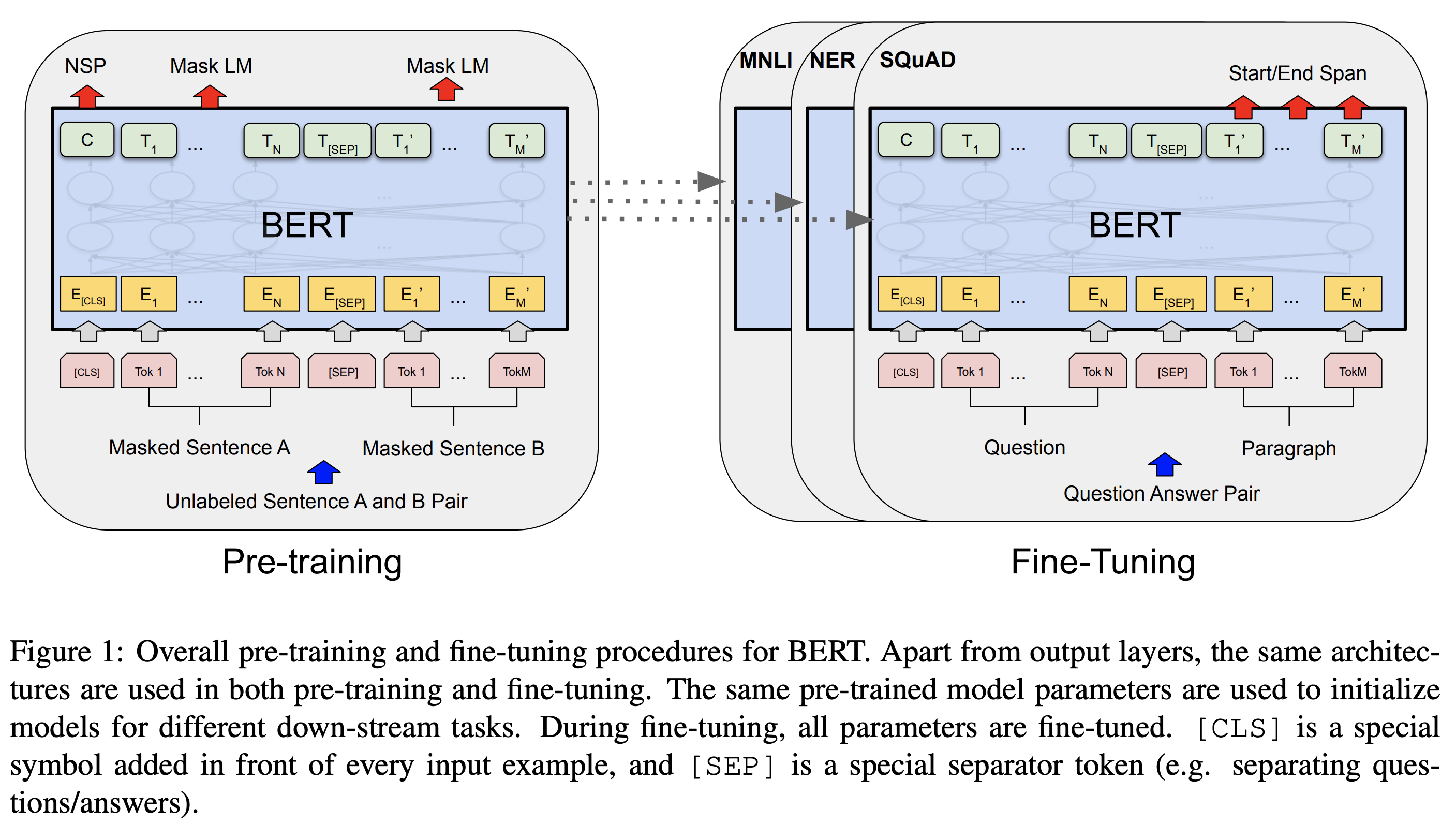
BERT 模型结构
- BERT 参数含义:
- L:transformer layers
- H:hidden size
- A:self-attention heads
BERT 输入输出结构
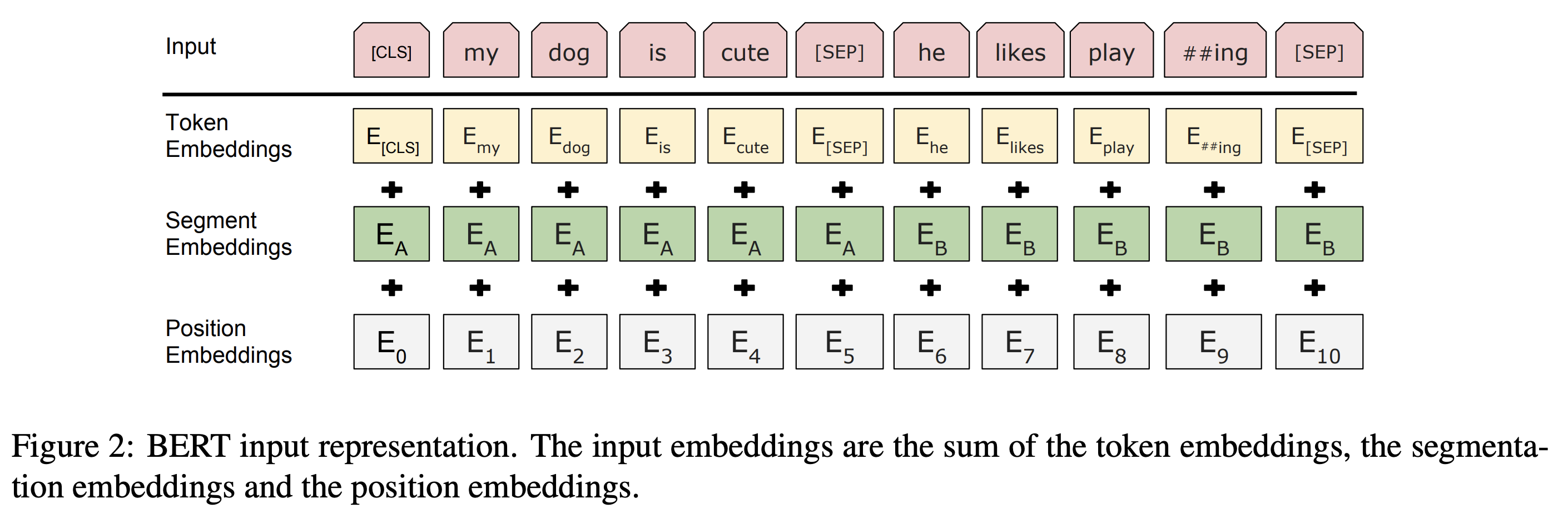
输入
- BERT 输入可以是一个句子,也可以是多个句子的 concat(用特殊分隔符分隔),例如问答数据集中,输入的句子是 <question, answer> concat
- [CLS] 为
Sequence开始标志位 - [SEP] 为
Sentence结束标志位
- [CLS] 为
Token Embeddings是将句子转化成词向量,英文版本 BERT 用的分词器是WordPiece embeddings,词表容量 30,000Segment Embeddings用于指明句子如何分割Position Embedding用于记录原始位置信息(与 CNN 不同,Transformer 中没有位置信息)
输出
其中:
BERT 预训练细节
Masked Language Model
- mask 策略:
- 训练数据随机 mask 15% 的位置
- mask 数据的 80% 使用
[MASK]token 去 mask - mask 数据的 10% 使用随机 token 去 mask
- mask 数据的 10% 什么都不改变
- 计算 loss
- 假如第 个 token 被 mask,那只计算输出 映射到词表空间的 token 分布和真实 token 之间的交叉熵 Loss(本质就是分类)
Next Sentence Prediction
- 数据生成策略:
- 每个样本由两个句子组成,50% 的可能两个句子是前后句的关系,50% 的可能两个句子不是前后句的关系,预测 IsNext OR NotNext
- 计算 loss
- 只用输出
C映射到二分类空间的结果和二分类 label,计算交叉熵损失
- 只用输出
- 在
NSP数据集中,无监督预训练即可达到 97% - 98% 的准确率
BERT fine-tuning
- 对于不同的任务,只需要替换 BERT 之后的网络结构,使用有监督数据 end-to-end fine-tuning 即可
消融实验
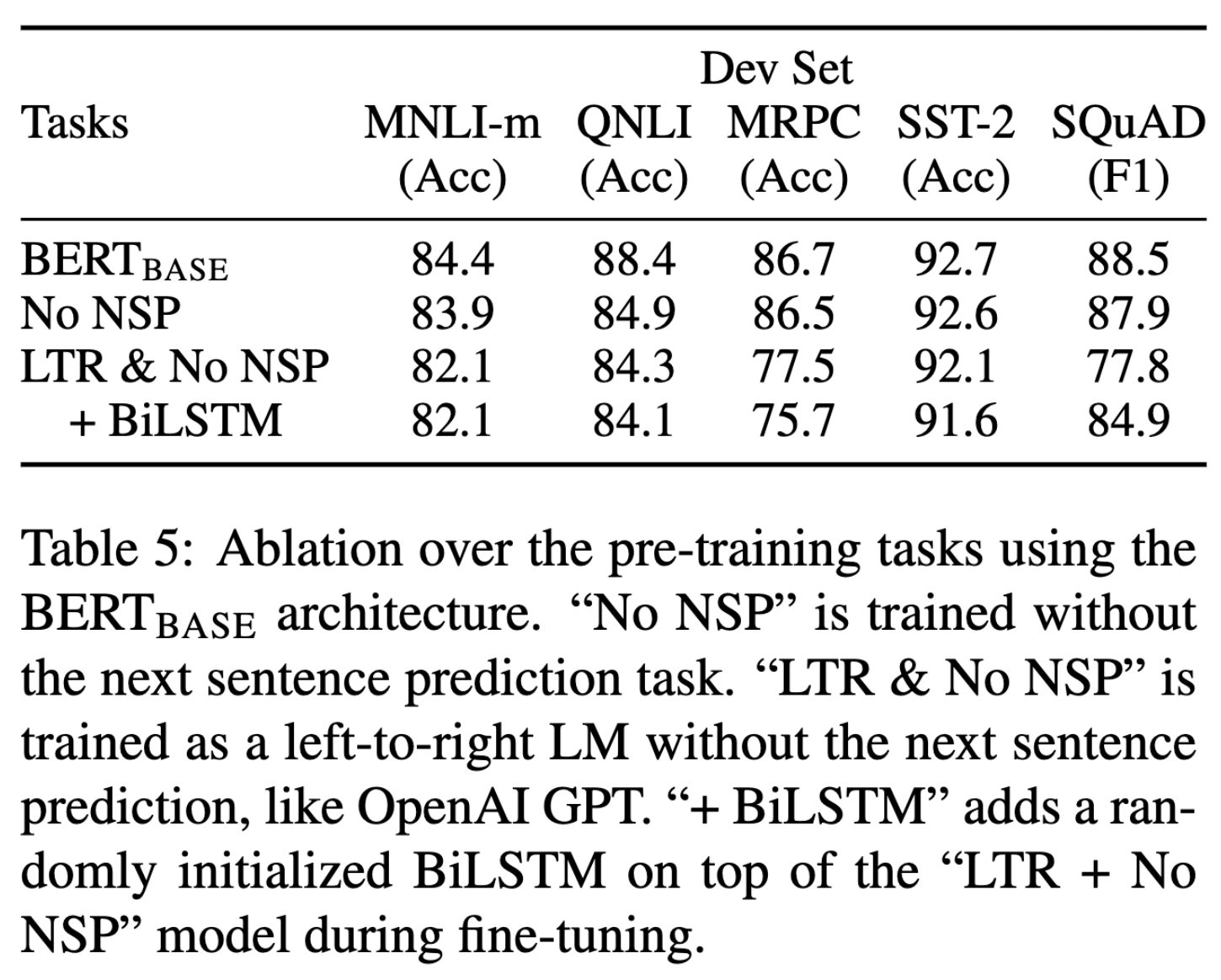
分析了 NSP、双向网络结构等对效果的影响
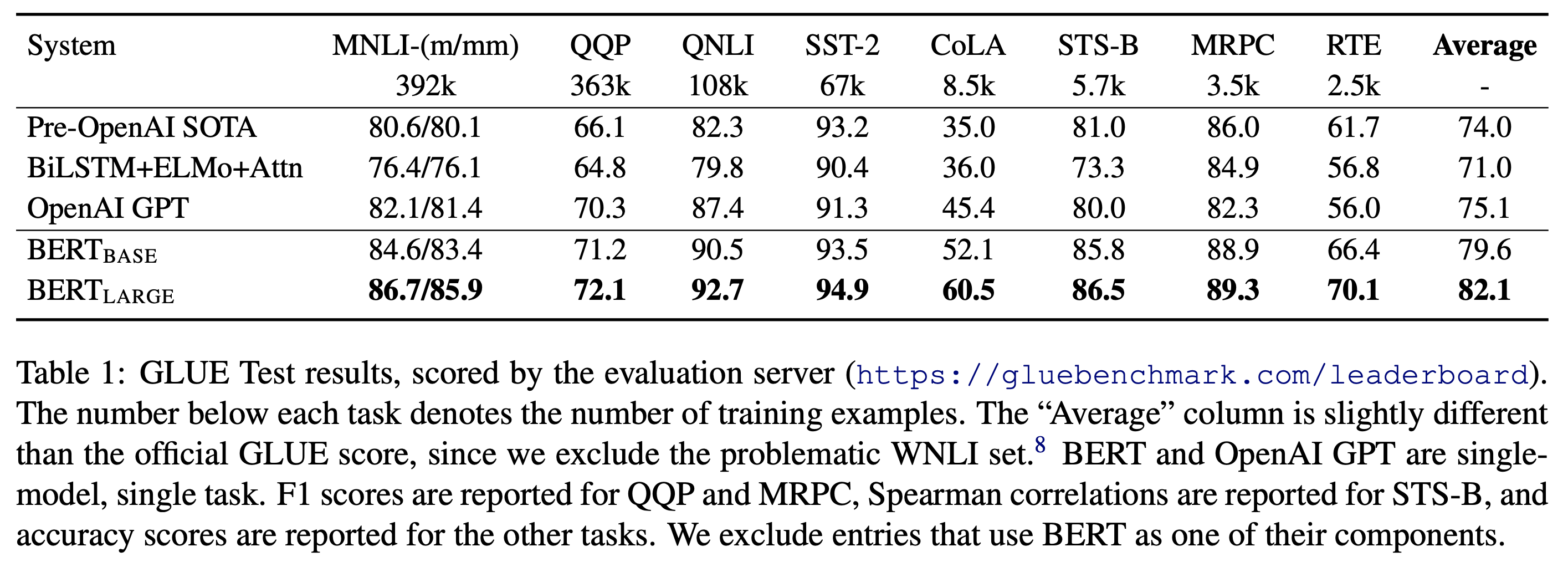
效果对比