0%
URL
TL;DR
- 本文提出一种图像自监督预训练方法:
Masked Autoencoders (MAE),通过 mask 很高比例的图像 patch,并使用非对称 encoder-decoder 结构重建整个图进行预训练
- 随机 mask 很大的比例,例如:75% ,一方面提高自监督难度以达到自监督效果,另一方面减小
encoder 大小
- 只将未 mask 的 patch 送入神经网络,重建整张图
- 与
BERT 非常相似,BERT 在自然语言中进行自监督预训练从而使得网络参数量可以达到惊人的一千亿;MAE 也希望通过图像自监督预训练提高网络参数和网络效果
Algorithm
视觉模型 masked autoencoder 与语言模型 masked autoencoder 有何差异
- 视觉模型通常使用 CNN,CNN 无法直接对
mask tokens 和 positional embeddings 等自监督标记进行有效整合;Vision Transformers (ViT) 提出了一种有效的解决方法
- 语言是人生成的经过高度信息聚合的,所以信息冗余较少,mask 很小比例后重建难度就较高;图像有大量信息冗余,所以需要 mask 很大比例才有重建难度,才能起到自监督效果
- 由于语言自监督模型重建的信息维度较高,所以
encoder-decoder 结构中的 decoder 可以非常简单(通常是一个 MLP);但视觉自监督模型重建的信息维度是像素,所以 decoder 结构在网络中扮演一个关键角色
什么是 Autoencoder
Autoencoder 是一种经典的表征学习方法,可以将输入通过 encoder 映射到表征空间,再通过 decoder 解码Denoising autoencoders (DAE) 是将输入破坏,再通过 decoder 重建出破坏前的原始输入,Masked Autoencoder 就是一种 DAE
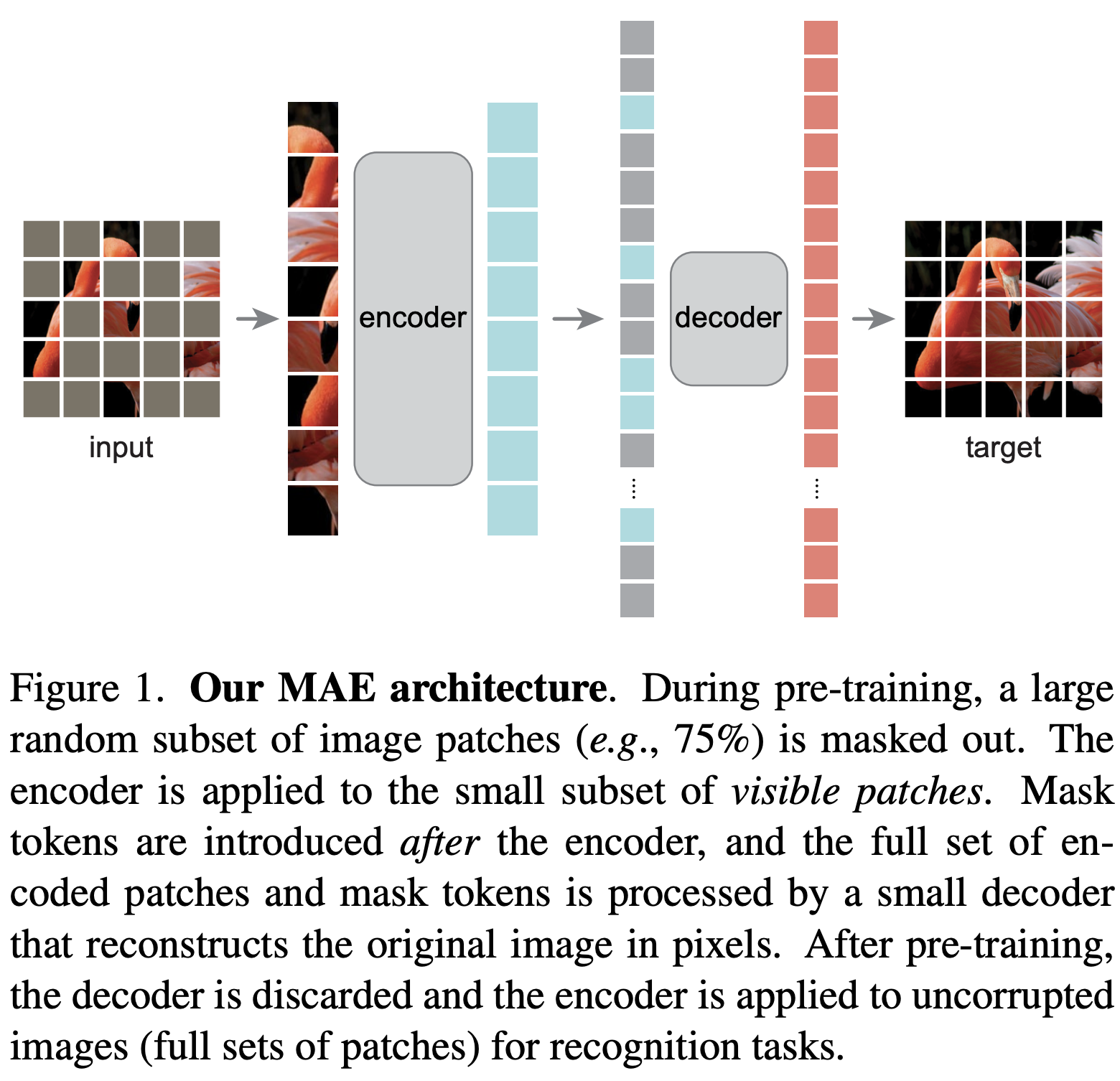
Architecture
MAE 的 encoder 部分与 ViT 的 encoder 相同,输入为 未 mask 的图像 patchMAE 的 decoder 部分输入包含两部分:
encoder 部分对 未 mask 的图像 patch encoder 后的表征(输入 decoder 的浅蓝色方块)mask tokens(输入 decoder 的灰色方块)
decoder 的结构更浅更窄,每个 token 的计算量只有 encoder 的 10%- 只在 mask patch 上计算 loss,损失函数就是简单的
mean squared error(MSE)
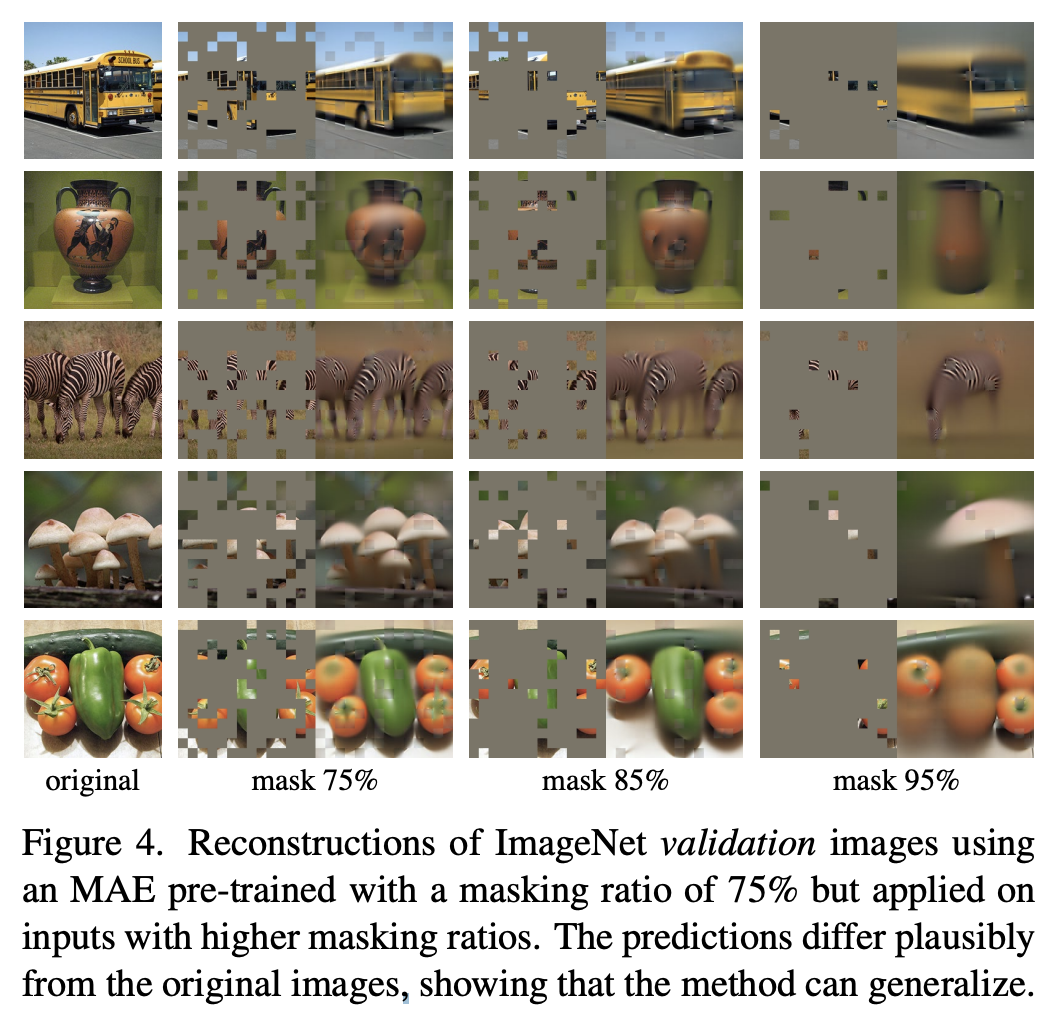
自监督重建效果

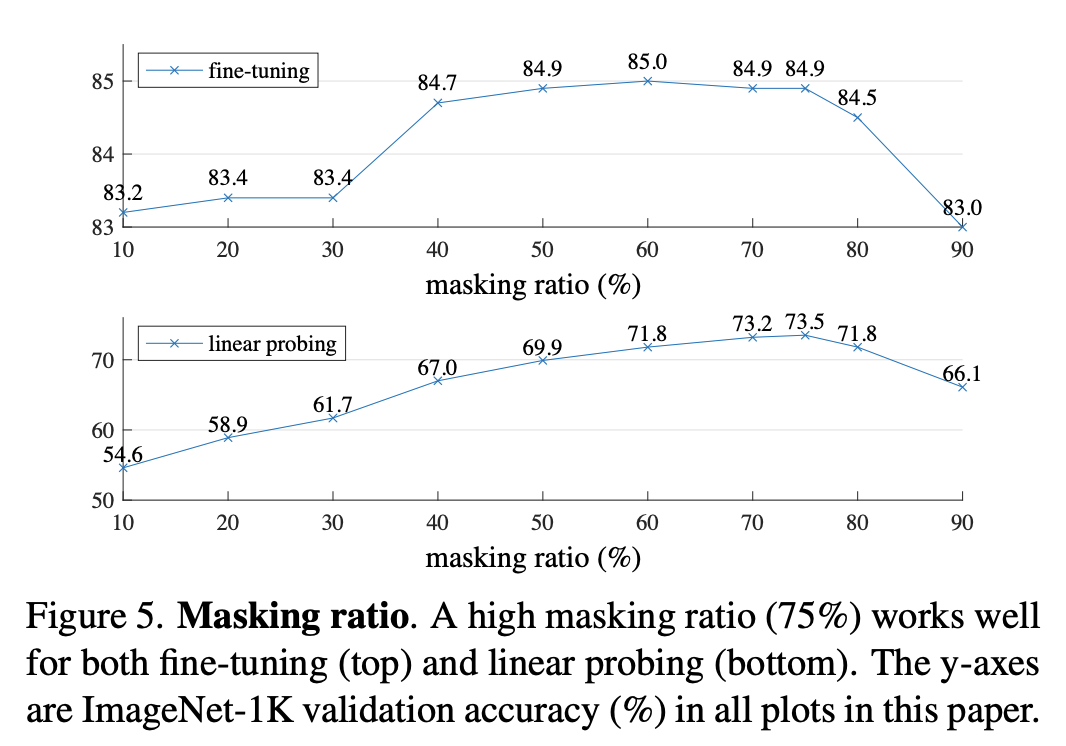
不同 mask 比例下的自监督效果对比
寻找最合适的 mask 比例
Though
- 将 Masked Language Model 优雅地应用在图像自监督中,简单、有效、mask sense
- 使在图像上应用超大规模预训练模型成为可能