URL
TL;DR
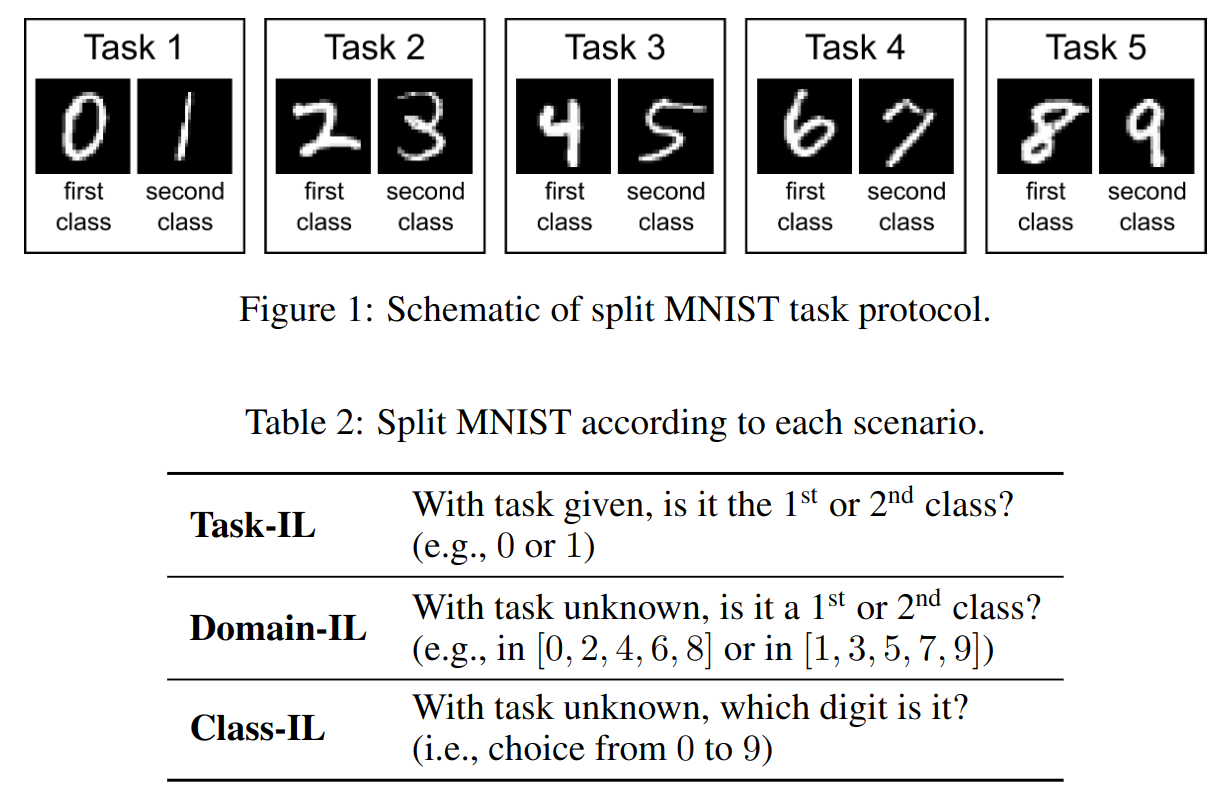
- 本文将增量学习细分为三种场景:
- 训练阶段:所有场景在训练阶段都一样,Task 1、Task 2、… 、Task T 一个接一个训练
- 预测阶段
task-incremental learning (Task-IL):测试阶段会指明是哪个 task,常用的结构是Multi-head每个任务独占一个head,所有任务共享backbone,但Multi-head和Single-head网络结构不能决定增量学习场景,只是一种常用的结构。domain-incremental learning (Domain-IL):测试阶段不指明是哪个 task,网络也无需推测输入属于哪一个 task,常用的网络结构是Single-head。class-incremental learning (Class-IL):网络需要推测输入属于哪个 task,并且输出这个任务中的哪一类。
Algorithm
- 本文的三种增量学习的对比实验所用实验策略有两个:
MNIST数据分类:一共 5 个 task,每个 task 分类 2 种数字,细节如上图所示。Permuted MNIST数据分类:一共 10 个 task,每个 task 分类 一种固定 shuffle 方式 的 10 种 MNIST 数字数据,细节如下图所示:
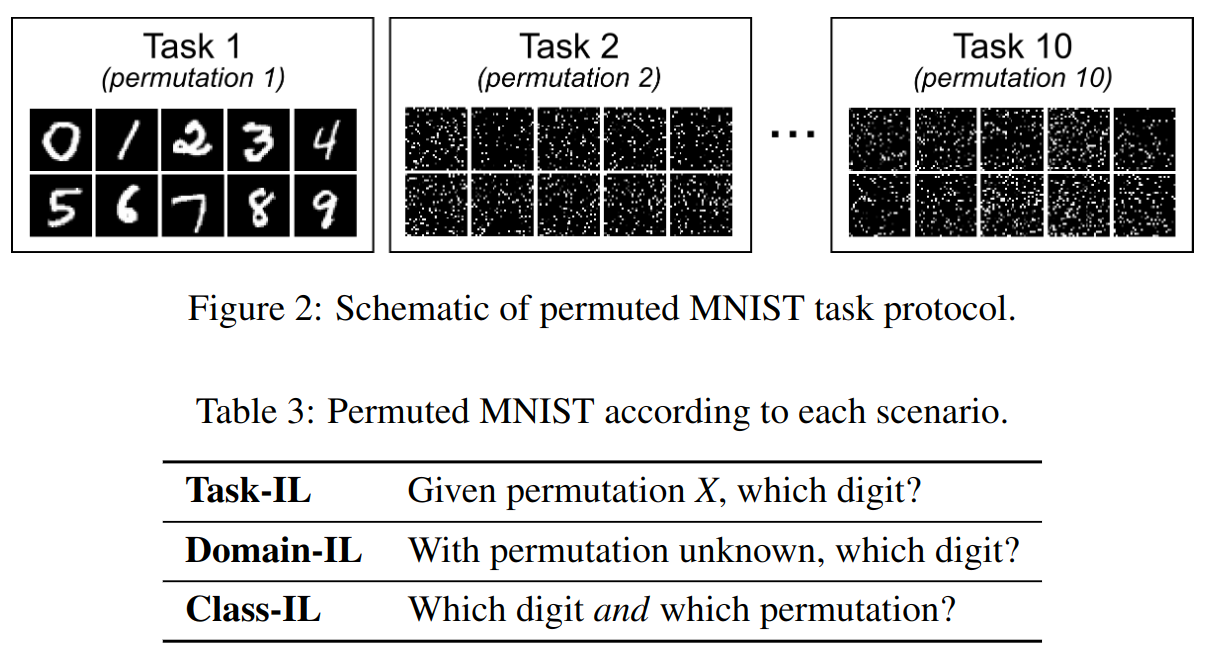
| model name | task number | class number | image size | info |
|---|---|---|---|---|
| split mnist | 5 | 2 | 28x28 pixel grey-scale images | 总共 10 类数字,每个类别有 6000个图片用于训练,1000个用于测试 |
| permuted mnist | 10 | 10 | zero-padded to 32x32 pixels | 总共 100 类数字,每个类别有 6000个图片用于训练,1000个用于测试 |
增量学习常用策略
- 任务独占组件:在每个任务上训练单独的组件,在
inference时根据给定的task选择组件。只适用于Task-IL,例如XdG算法。 - 正则优化:在每个任务上训练单独的组件,但在
inference时由于task不可知,所以使用整个网络inference。训练时加入正则化项,使得网络在新任务中的参数与旧任务参数接近,常用的算法有:EWC、Online-EWC、SI等。 - 修改训练数据:又被称为
replay方法,即通过某种方法将之前任务的数据(或伪数据)补充到新的训练任务中,例如:Learning without Forgetting方法(LwF),这种方法将新任务输入数据在旧模型中的输出分布作为软标签伪数据,与新数据的数据一起在旧模型上 fine-tunning,最终得到新模型,利用了类似 知识蒸馏 的方法。Deep Generative Replay方法(DGR),这种方法和 LwF 都属于使用 数据重放(data replay) 来实现增量学习的算法,不同之处在于,DGR 使用的是使用样本生成的方法直接生成旧任务的样本,使用硬标签训练,而不是使用新任务数据在旧模型上的软标签进行蒸馏。- 或者使用
DGR + LwF的方法,用DGR生成与旧任务数据同分布的数据并使用LwF方法蒸馏。
- 使用范例数据:例如
iCaRL类别增量学习算法,保存一部分旧类别数据的典型样本,每次和新类别数据一起更新表征,再根据新表征更新旧任务典型样本。
增量学习的算法上下界
- 增量学习的算法上界(joint training):所有任务的训练数据可以一次性拿到,同时训练所有任务。
- 增量学习的算法下界(fine-tuning):不使用任何优化,每次新任务都只使用新任务的数据对旧模型进行训练。
Experiment
实验设置
- 输出单元设置:为了公平比较,所有方法都使用相同的输出单元。
split MNIST使用2个隐藏层实现,每层 400 节点。permuted MNIST使用2个隐藏层实现,每层 1000 节点。激活函数使用ReLU,除了iCaRL之外,其他模型最后一层都是softmax输出层。 iCaRL只能用于类增量学习,任务增量和域增量不可以。Task-IL实验设置:所有算法都使用Multi-head Output Layer结构,每个任务都有一个指定的输出单元,对于任务 ,只有对应的输出单元 被使用,其他任务对应的输出单元不被使用。Domain-IL实验设置:所有算法都使用Single-head Output Layer结构,只有一个输出单元,所有任务共用一个输出单元。Class-IL实验设置:目前已有多少类,就有多少个输出单元,每个类都有独立的输出单元。
实验结果
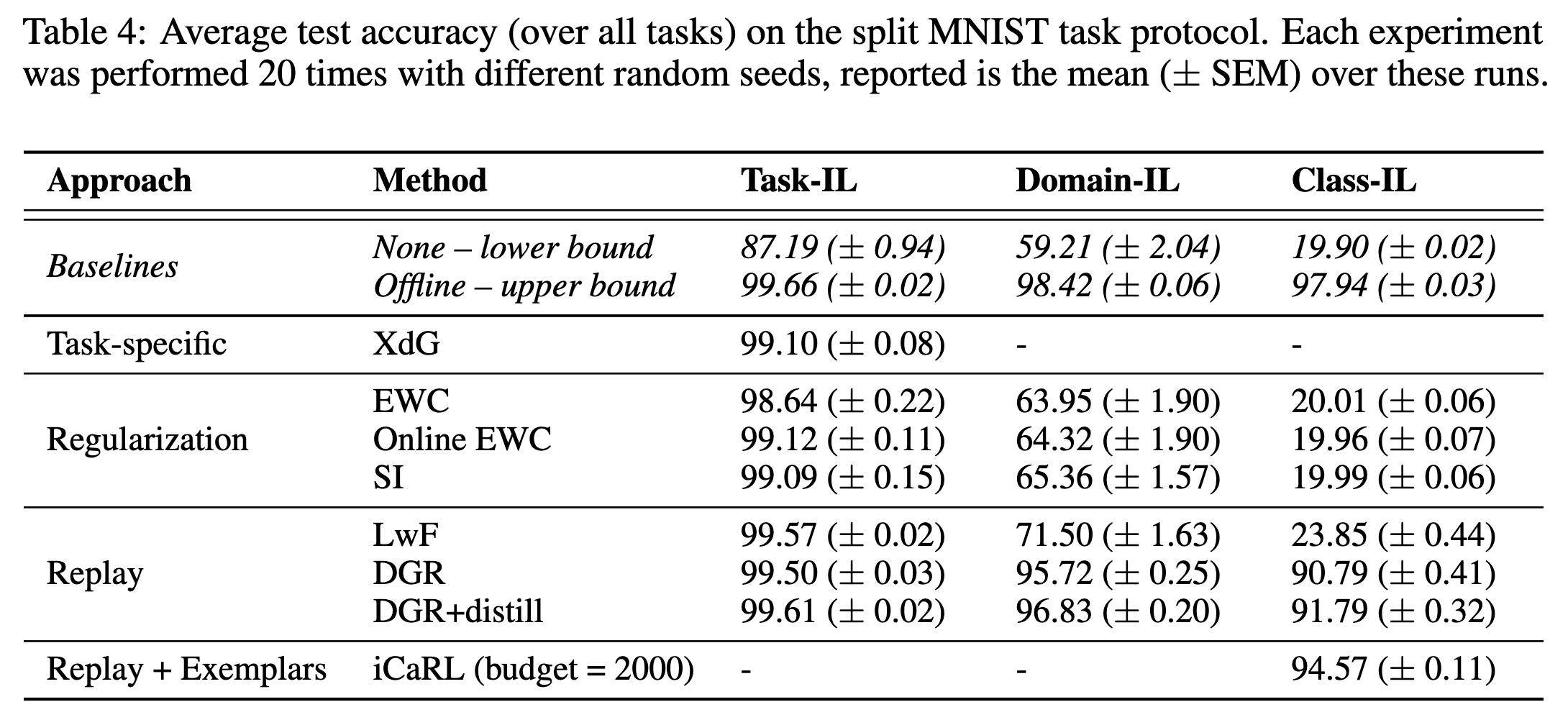
- 对于
split MNIST任务
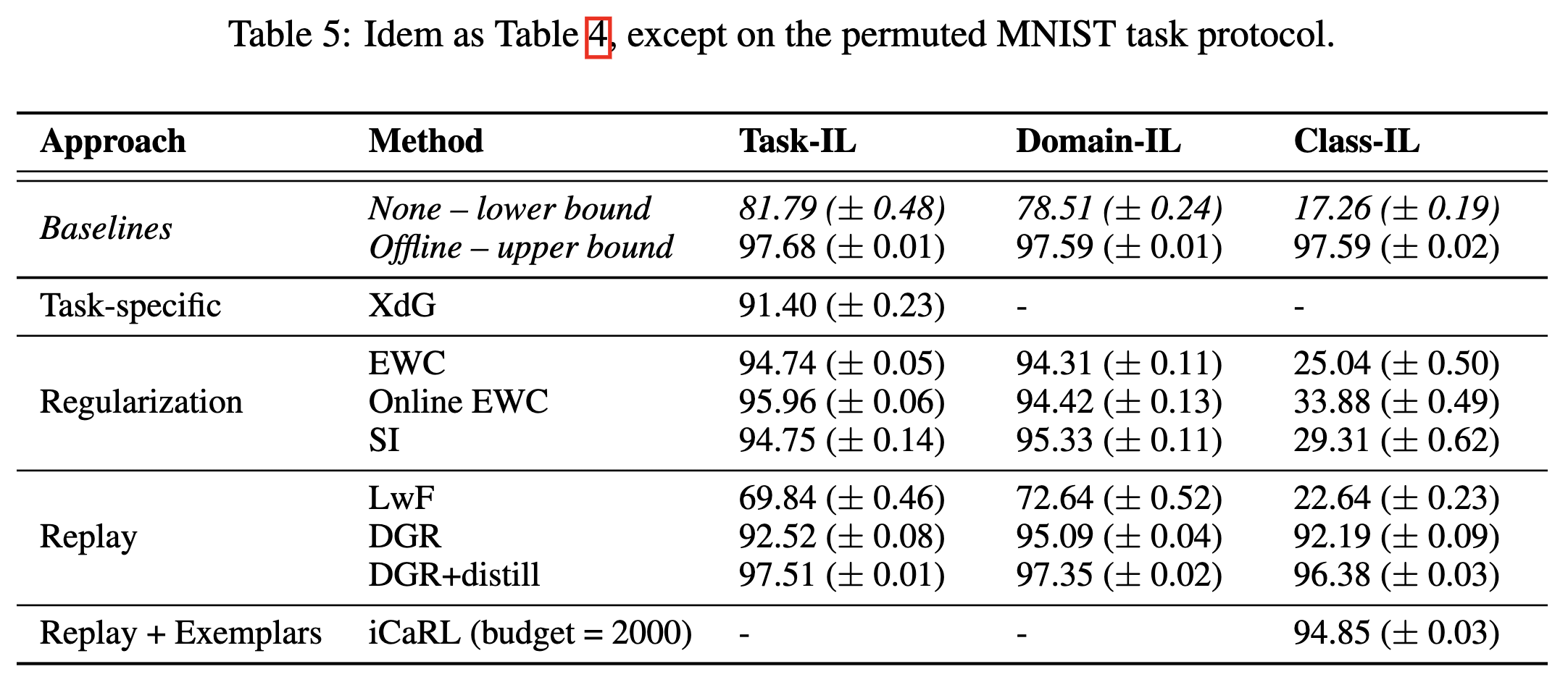
- 对于
permuted MNIST任务
Through
- 文章逻辑挺清晰的,就是代码写的太拉胯了…