URL
TL;DR
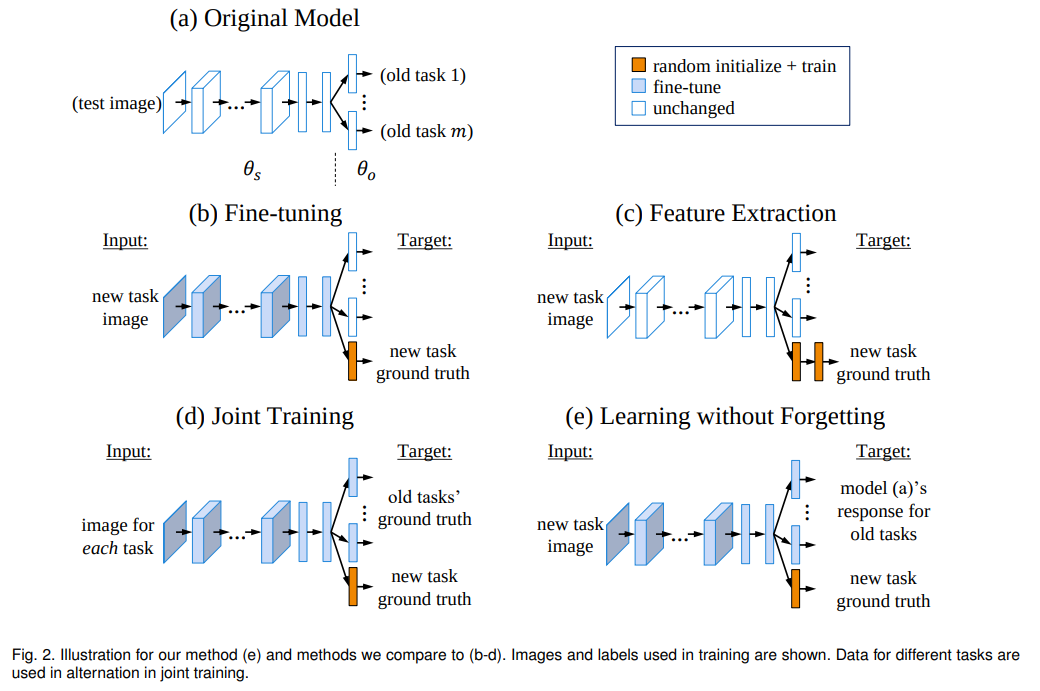
- 本文将一个增量学习任务的网络结构拆分成三个部分:
backbone- 旧任务相关参数
- 新任务相关参数
- 所有增量学习都需要:
- 使用原始 backbone(可微调)
- 随机初始化新任务相关参数
- 在此基础上增量学习常用的解决灾难式遗忘的方法有:
Fine-tuning:在 新任务数据集 上 冻结旧任务相关参数,Fine-tuning backbone 以及新任务相关参数,如上图 b 所示Feature Extraction:在 新任务数据集 上 冻结 backbone 以及旧任务相关参数,只训练新任务相关参数,(与 b 不同的地方在于 是否冻结 backbone),如上图 c 所示Joint Training:在 所有任务数据集上 上 Fine-tuning 所有参数(backbone、新任务相关参数、旧任务相关参数),(与 b 不同的地方在于 是否使用所有任务数据,以及是否 fine-tuning 旧任务相关参数),如上图 d 所示Learning without Forgetting:在 新任务数据集 上 Fine-tuning 所有参数(backbone、新任务相关参数、旧任务相关参数),如上图 e 所示,(与 d 不同的地方在于 使用的训练数据不同),这种方法使用的标签包括:- 硬标签:新任务数据的 原始标签
- 软标签:新任务数据在旧模型上的 输出分布,目的是:使得网络在训练新任务时,尽可能保持旧任务上的分布
Joint Training因为用到所有数据同时训练,所以通常被认为是增量学习的算法效果上界
Algorithm

LwF算法会修改所有参数:backbone- 新任务相关参数
- 旧任务相关参数(这个很重要!)
LwF损失函数中各参数的含义:- 分别表示:
backbone原始参数、backbone在所有任务上的最优参数、backbone训练中的临时参数 - 分别表示:旧任务相关参数原始参数、旧任务相关参数在所有任务上的最优参数、旧任务相关参数训练中的临时参数
- 分别表示:新任务相关参数原始参数、新任务相关参数在所有任务上的最优参数、新任务相关参数训练中的临时参数
- 表示:旧任务重要程度权重
- 分别表示:
Experiment
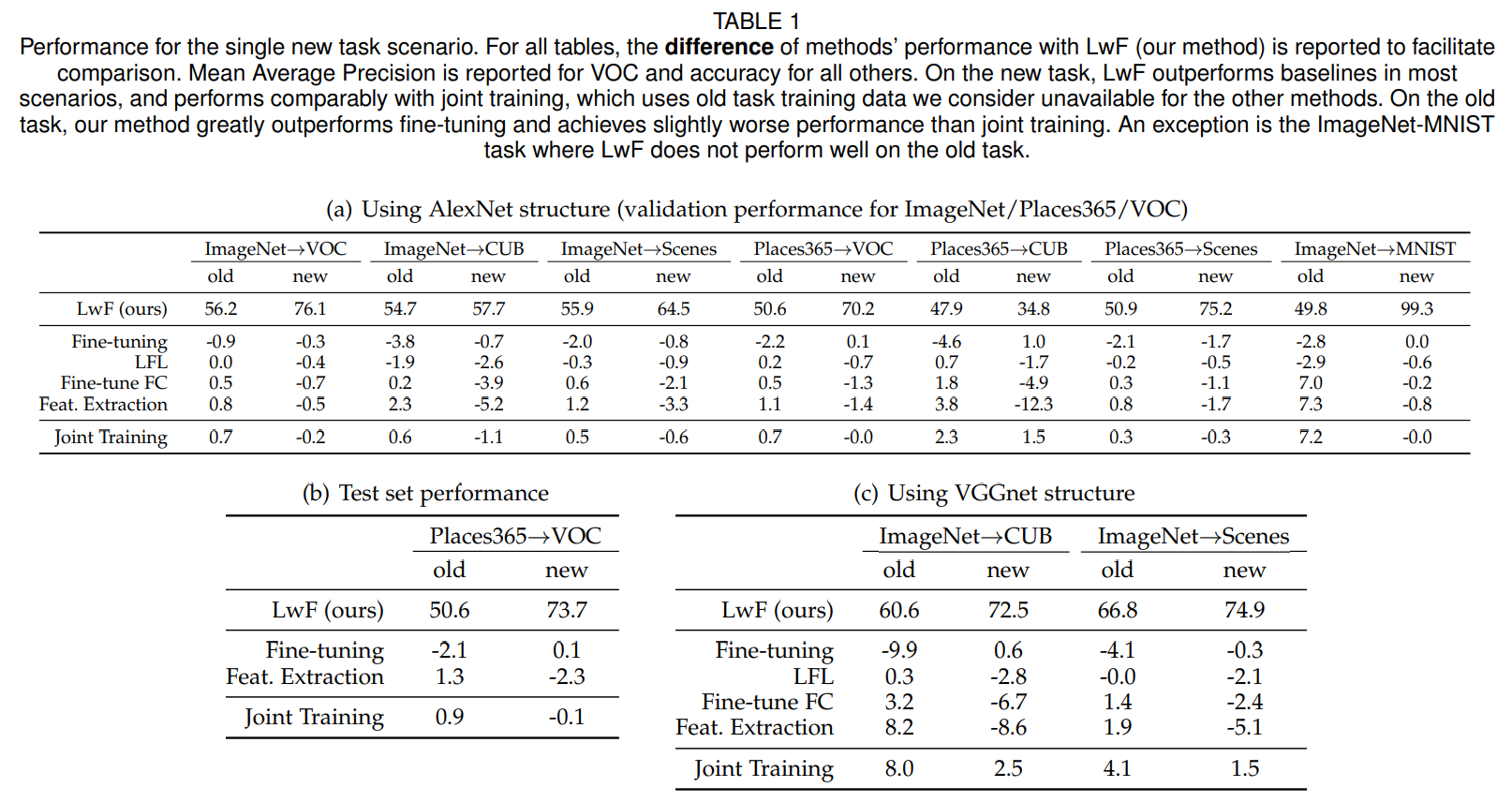
比
Fine-tuning、Feature Extraction、Joint Training都强
Thought
- 使用一种类似蒸馏的方法,使用新数据 + 旧模型的方法 replay 旧数据,看起来挺
make sense