URL
- paper: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
- demo code: https://github.com/karpathy/minGPT
- reference: https://jalammar.github.io/illustrated-gpt2/
TL;DR
GPT (Generative Pre-Training)是一种基于transformer decoder结构的语言预训练模型,和视觉预训练模型不同的是使用没有label的文本数据做自监督预训练训练。GPT训练主要分成两个步骤:- 在无标注数据上做自监督预训练,具体训练目标函数是:根据前 k 个词预测下一个词
- 在有监督数据集上做有监督微调,具体微调目标函数是:任务相关预测 + 根据前 k 个词预测下一个词
- 由于
transformer decoder中存在mask,所以不像Bert可以根据前后文推理中间缺失的词(完型填空任务),GPT只能使用根据前文推后文的方法,因此也更适合做文本生成任务。 - 预训练好的模型在下游任务上微调时,只需要对网络输出头做较小的修改即可适配,效果很好。
Algorithm
- 发展历程: Transformer -> GPT -> Bert -> GPT2 -> GPT3 -> GPT4
example
GPT 模型擅长文本生成,因此以文本生成举例:输入"Hello, world!" 要求生成后续内容。
1. tokenize
- 本质是查词表,把文本字符串转换成若干个有序
id,每个id表示这个词在词表的索引 - 词表可以在 https://huggingface.co/openai-community/gpt2/raw/main/vocab.json 这里获取
Hello, world!会被拆解为:Hello:15496,:11world:995!:0
2. token embeding
- 因为
id串不是神经网络可以处理的格式,所以需要id的向量化 token embedding过程本身也是一个查表过程,表格的大小是vocabulary_size * embedding_size,GPT-2中vocabulary size == 50257,embedding size == 768- 查表后得到一个
4 * 768的token embedding
3. position embeding
- 给每个
token id顺序编码一个position id, 因此position id为[0, 1, 2, 3] - 然后将
position id变成模型可识别的向量,也是一个查表过程,表格本身是可以通过梯度下降学习的,表格的大小是max_seq_len * embedding_size,max_seq_len表示 最大支持的上下文长度,GPT-2中为1024 position embedding只用在transformer第一层之前
4. 生成输入 hidden states
token embedding+position embedding=hidden stateshidden states的shape = 4 * 768
5. Casual Decoder Layer
- 这个是
GPT系列模型的核心,是一种因果注意力机制 - 因果注意力(
Casual)是指每个hidden state只能关注之前位置的hidden state,而不能关注之后的 - 例如:
Hello, world!的seq_len == 4,那么注意力矩阵是4x4,但此矩阵需要是下三角矩阵,即 “,” 只能关注Hello,而不能关注world
6. Casual Decoder Layer 输出的 hidden states 再输入下一层 Casual Decoder Layer
- 输出的
hidden states和输入的hidden states的shape保持一致 - 再输入下一层
Casual Decoder Layer,GPT-2有12层
7. 最后一层输出的 hidden states 的最后一个 hidden state 用于分类
- 经过重复
12层的Casual Decoder Layer,最后输出hidden states (shape = 4 x 768) - 取最后一维
hidden state (shape = 1 x 768)通过一层或多层fully connect映射到vocabulary size vocabulary size上取argmax得到最大概率的下一个词
8. 合并预测到的词到语句末尾
- 如果预测的词不是结束符,且语句总长小于
max_seq_len,则将预测得到的词加到原语句末尾 - 加完之后的长度为
5的语句继续通过12层Casual Decoder Layer去预测下一个词 - 重复直到结束符或
max_seq_len
model architecture
- token embedding
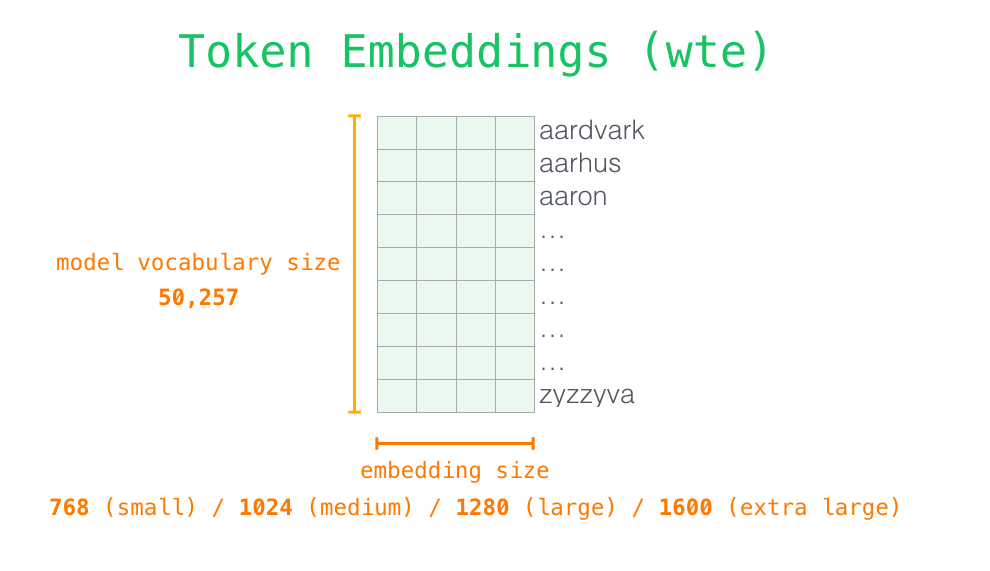
- postion embedding
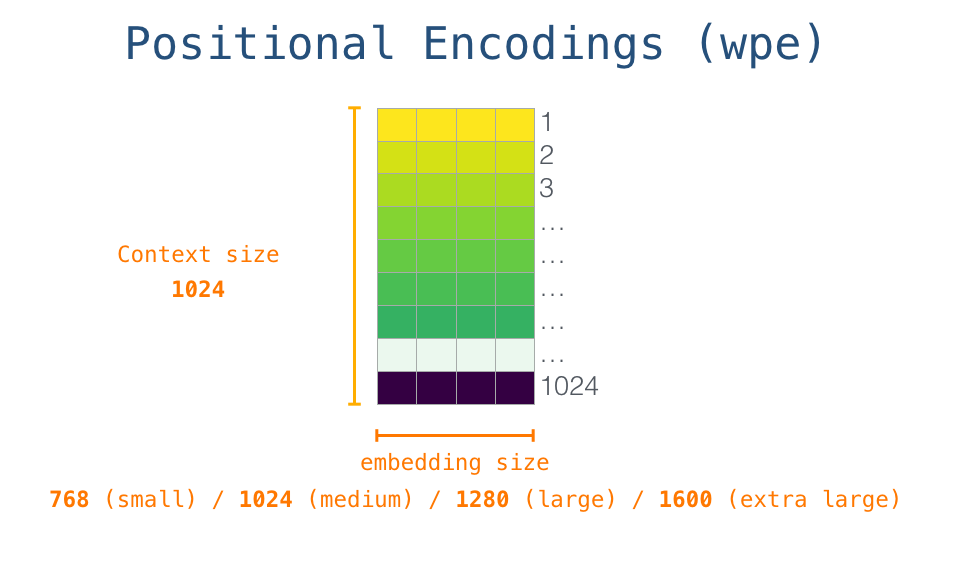
- model architecture

Unsupervised pre-training
- 使用标准语言建模(用前面的词预测下一个词)目标来最大化如下的似然函数:
目标函数:
其中:U 表示 token 的上下文向量,k 为窗口大小, 为模型参数 - 模型使用
Transformer decoder结构,整体计算流程可简写为:
其中:n表示transformer层数,U 表示上下文token, 表示token的embedding矩阵, 表示position embedding矩阵
Supervised fine-tuning
- 有监督
fine-tuning使用的数据可表示为:- 输入
- 标签 y
- 预测 这里使用 最后一层的最后一个 token 对应的输出
- 因此,有监督目标函数为: ,其中 C 表示
fine-tuning使用的有标签数据集 - 作者发现在
fine-tuning阶段,加上无监督损失函数效果会更好,即:
Task-specific input transformations
-
本节讨论的是在
fine-tunning以及inference阶段如何构造模型输入
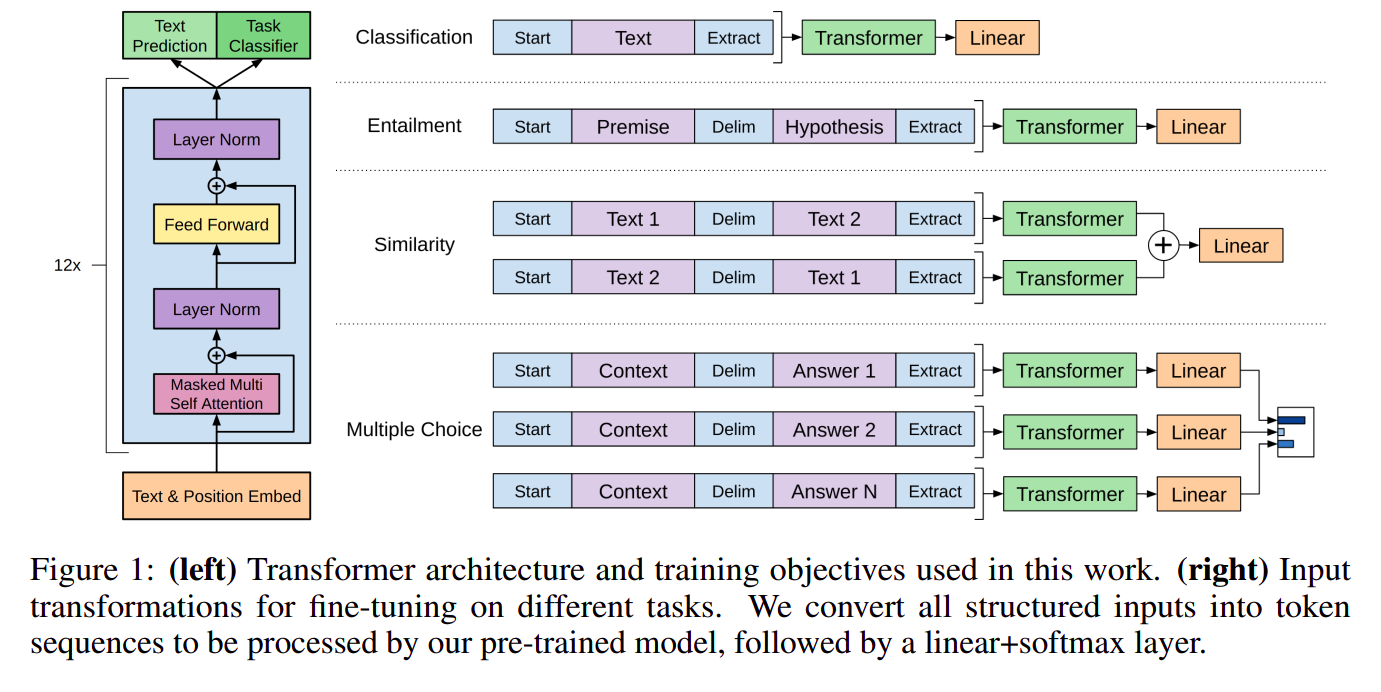
-
上图举例了四个常见
NLP任务:-
分类:图中的
Start和Extract分别是两个保留的特殊 token,分别表示输入的开始和输出特征的抽取(linear 层只输入 transformer 最后一层的最后一个 token 的输出,因此在最后填充一个 Extract 特殊标记 token) -
蕴含:用于分析 前提(premise) 是否蕴含 假设(hypothesis),本质是一个 蕴含 / 不蕴含 / 不确定 三分类问题,中间的
Delim是特殊标识 token,表示分割含义 -
相似:用于分析两个句子是否具有相似关系,由于相似具有对称性,所以需要构造两种顺序的输入,本质是二分类
-
多选:其中
context包含上下文文本和问题,需要针对每个答案构建一个context和answer对,最后用softmax计算answer概率分布
-
Thought
GPT使用了Transformer decoder,由于mask的存在,无法知道之后的句子,因此选择了比Bert更难的标准语言建模(根据前 k 个词预测下一个词)的代理任务,对应的模型无监督预训练效果上限也相应提高。- 由于
Bert使用的Transformer encoder,因此可以看到句子的上下文,因此Bert使用了较为简单的完形填空无监督目标函数。 Bert晚于GPT,借鉴了很多GPT的思想,效果也优于GPT,但GPT开启了语言模型无监督预训练先河,有可能成为AIGC的原型机。