URL
https://mlc.ai/zh/chapter_tensor_program/index.html
元张量函数
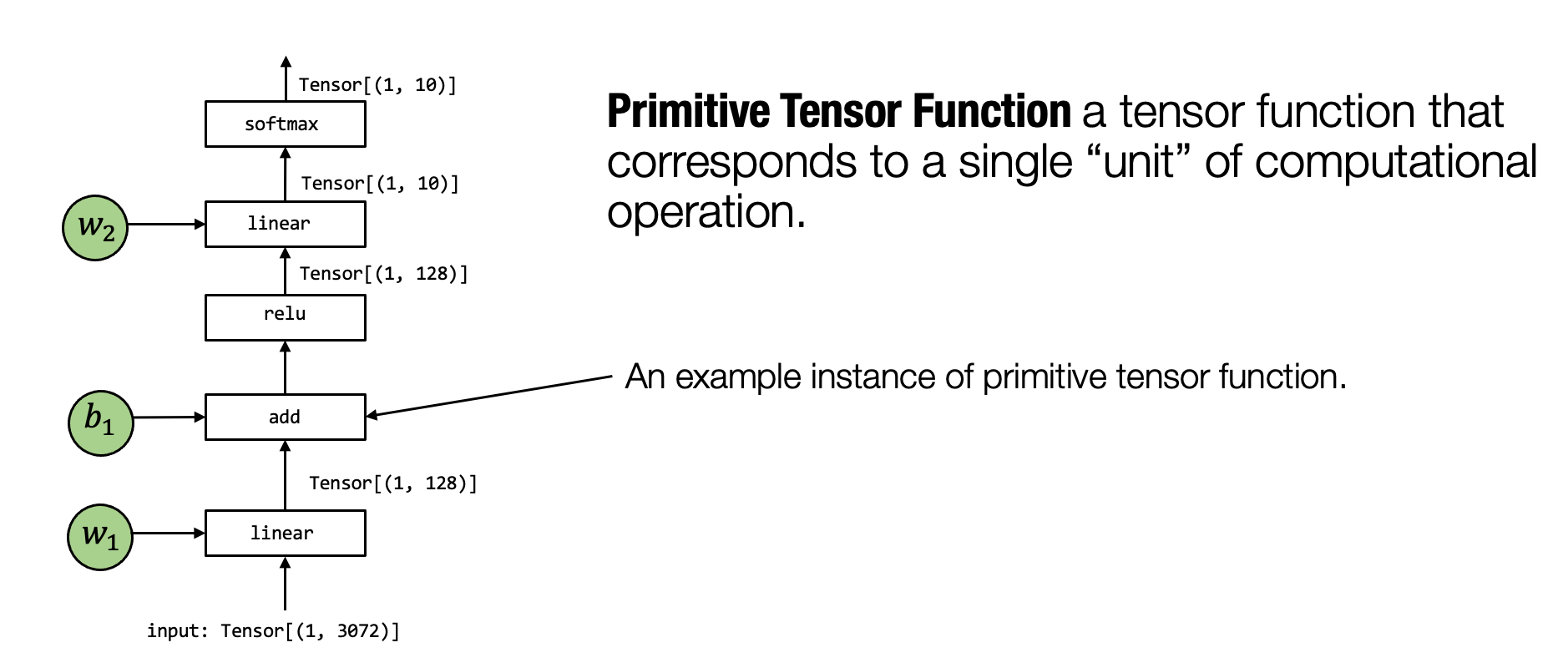
- 元张量函数 表示机器学习模型计算中的单个单元计算。
- 一个机器学习编译过程可以有选择地转换元张量函数的实现。
张量程序
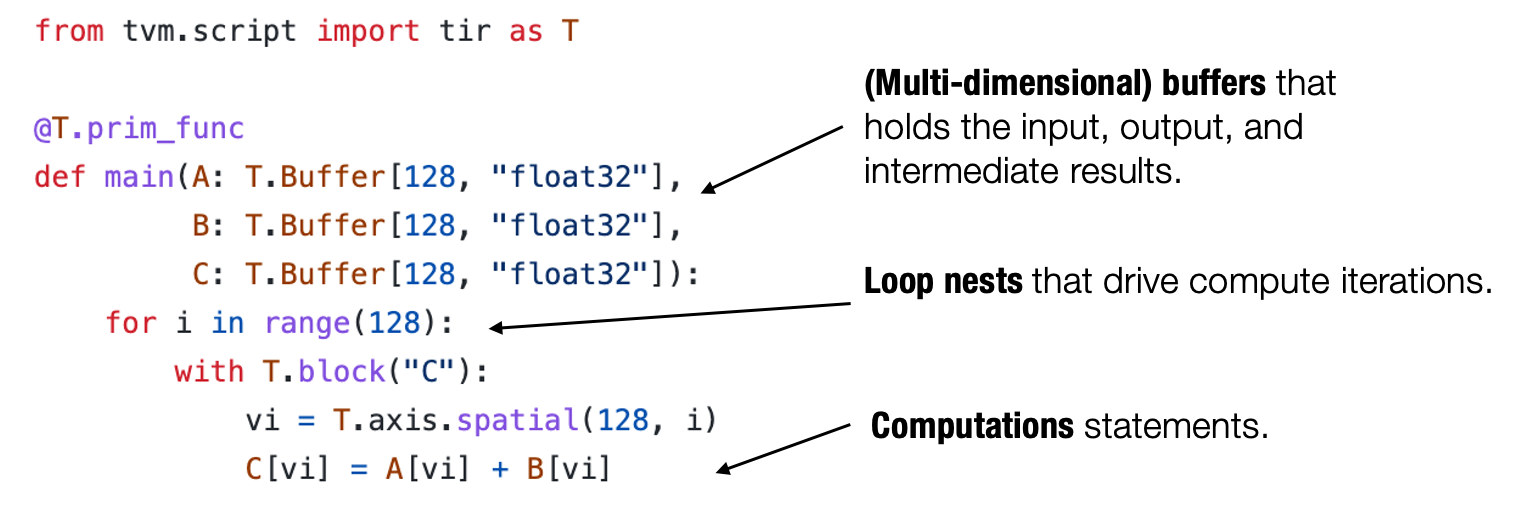
- 张量程序 是一个表示元张量函数的有效抽象。
- 关键成分包括: 多维数组,循环嵌套,计算语句。
- 程序变换可以被用于加速张量程序的执行。
- 张量程序中额外的结构能够为程序变换提供更多的信息。
TensorIR: 张量程序抽象案例研究
- TensorIR 是标准机器学习编译框架
Apache TVM中使用的张量程序抽象。
目标
-
使用
TensorIR张量程序抽象ReLU(A @ B)张量函数。 -
数学表示:
不同实现方法
使用 Numpy 实现
1 | dtype = "float32" |
使用 Low Level Numpy 实现
Low Level Numpy是指只使用Numpy的数据结构而不调用Numpy的 API
1 | # Use low level numpy to implement matmal ReLU |
使用 TensorIR 实现
TensorIR是TVMScript中的一种Python方言
1 | import tvm |
TensorIR 代码与 Low Level Numpy 代码对比
函数参数
1 | # TensorIR |
buffer
1 | # TensorIR |
循环
1 | # TensorIR |
计算块
1 | # TensorIR |
块(Block) 是
TensorIR中的基本计算单位。
-
值得注意的是,对于一组固定的 vi 和 vj,计算块在 Y 的空间位置 (Y[vi, vj]) 处生成一个点值,该点值独立于 Y 中的其他位置(具有不同的vi, vj 值的位置)。我们可以称 vi、vj 为 空间轴,因为它们直接对应于块写入的缓冲区空间区域的开始。 涉及归约的轴(vk)被命名为 归约轴。
-
空间轴上的每个点都独立于其他点。
1 | vi = T.axis.spatial(128, i) |
函数属性
1 | T.func_attr({"global_symbol": "mm_relu", "tir.noalias": True}) |
其中:
global_symbol对应函数名。tir.noalias是一个属性,表示所有的缓冲存储器不重叠。
装饰器
@tvm.script.ir_module表示被装饰的类是一个 IRModule。@T.prim_func表示被装饰的函数是一个张量函数。