URL
TL;DR
- 本文用比较简洁的方式给出了神经网络的通用量化方法,是量化领域的必读论文。
Algorithm
1. 量化基础知识
1.1 硬件背景
- 一个 实际上是由 乘法器 和 累加器 组合而成的,实际的计算过程如下:

卷积实际上也是通过
image to column操作变成 操作
- 常见的
int8量化会将上述过程变成如下过程:
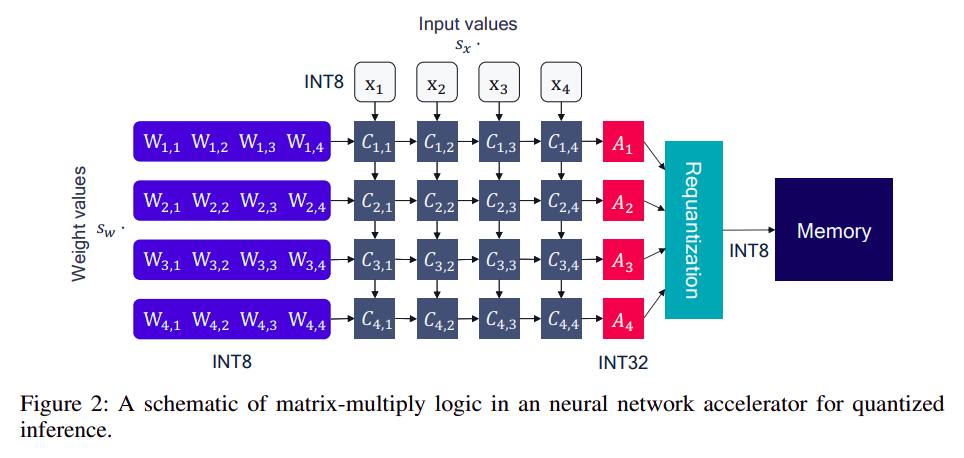
weight和input都被量化为int8,同时保留各自的量化scale,乘法操作是整形乘法器(更快),累加器是int32类型,最后再量化为int8放到OCM上
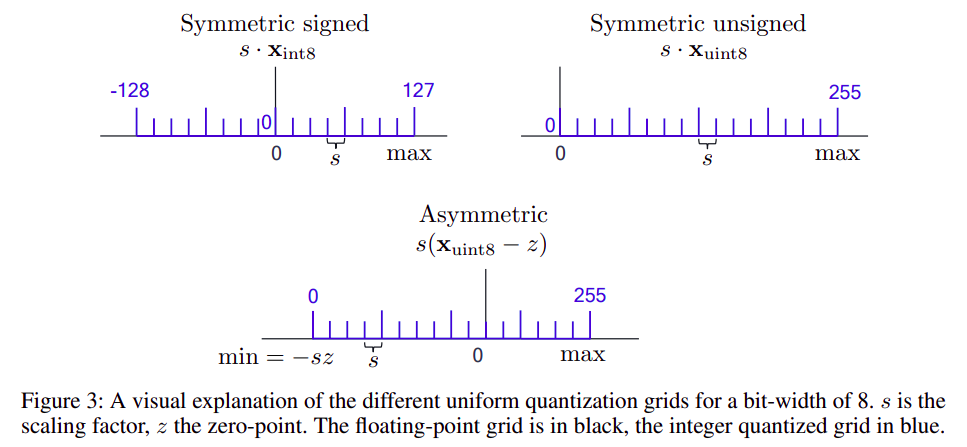
1.2 均匀仿射量化
- 均匀仿射量化也被称为 非对称量化,由三个量化参数定义:
- 比例因子
scale - 零点
zero_point - 比特宽度
bits
- 比例因子
- 非对称量化:
- for unsigned integers:
- for signed integers:
- 这里的 表示
round运算
- 对称量化是非对称量化的简化版本,是将零点
zero_point固定为0 - 对称量化:
- for unsigned integers:
- for signed integers:
- 对称量化和非对称量化的含义:
2的指数幂量化:- 限制
- 优势:scale 过程变成了硬件移位,对硬件更友好。
- 劣势:会使得 round 和 clip 误差的权衡变难。
- 量化颗粒度:
- per-tensor: 硬件更友好,但限制了量化的自由度。
- per-channel: 反之。
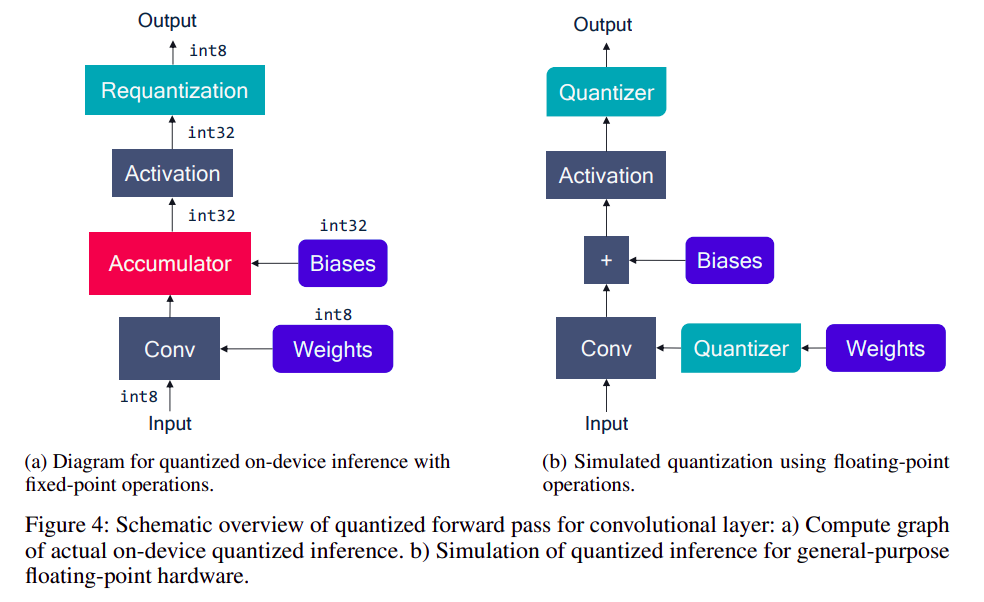
1.3 量化模拟
- 量化模拟是指在浮点计算设备上模拟定点计算设备的过程,通常用于训练。
左边是定点计算过程,右边是用浮点设备模型定点计算的过程
- 为了减少数据搬运和不必要的量化步骤,通常会做:
batch norm折叠:batch norm在推理时是静态的,因此可以和前面的conv等层合并。- 激活函数融合:在实际的硬件解决方案中,通常会在非线性操作(如
ReLU)之后直接进行量化,而不是先将激活写入内存然后再加载回计算核心。
1.4 实践考量
- 对称量化和非对称量化:
- 对称量化:
zero-point == 0 - 非对称量化:
zero-point != 0
- 对称量化:
- 为了方便计算,通常情况下,会将权重设置为对称量化(),将特征设置为非对称量化()
- 原因分析:
- 在推理阶段: 已知,因此:
- 等式的第三项和第四项可提前算出,无需推理耗时。
- 第一项和第二项由于关联动态输入 ,因此需要额外耗时;但是如果设置 ,则第二项恒等于0,可节省计算量。
- 原因分析:
2. 训练后量化(PTQ,post-training quantization)
- 训练后量化是指用
float32精度训练的模型直接转成量化模型,无需任何数据和训练。
2.1 量化范围的设置
- 最大最小值法(
min-max):, 是待量化tensor - 均方差法(
MSE): - 交叉熵法(
cross entropy):,其中 表示cross entropy function - 批量归一化法(
BN based):,其中 分布表示batch norm学到的per channel的shift和scale, 是超参数 - 组合法(
comparsion):以上方法的自由组合
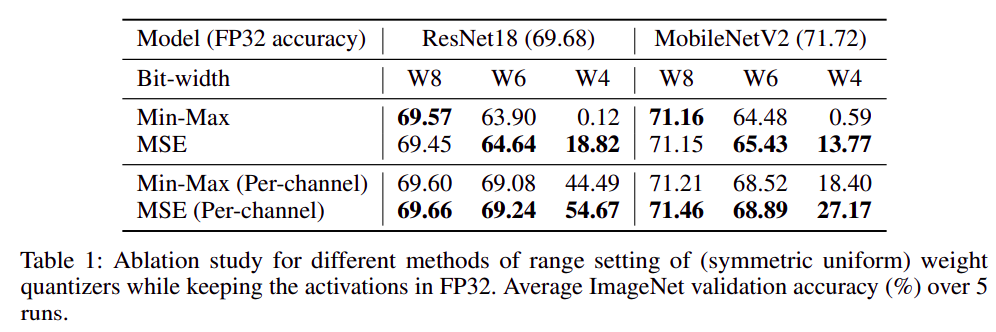
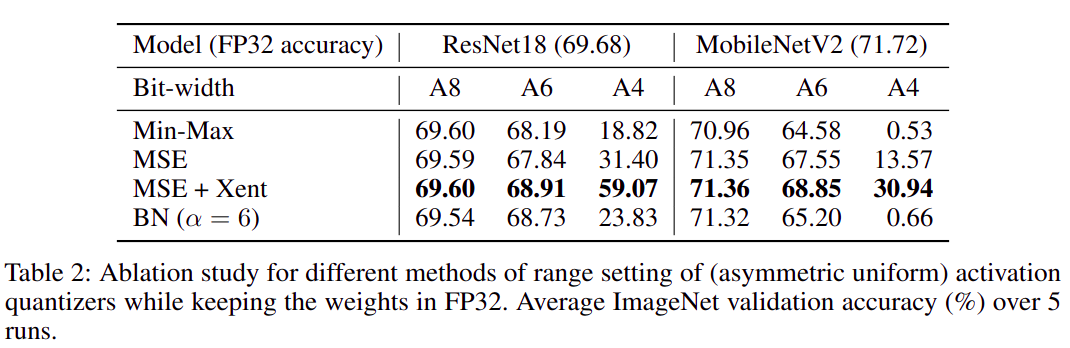
使用不同量化方法分别量化
weight和activation后的精度
2.2 跨层均衡(Cross-Layer Equalization)
- 这是一种 通过修改模型权重 来改善神经网络量化性能的技术,
CLE的目的是减少网络中不同channel之间由于量化引起的性能不平衡,这种问题在depth-wise conv layer中尤其容易出现。
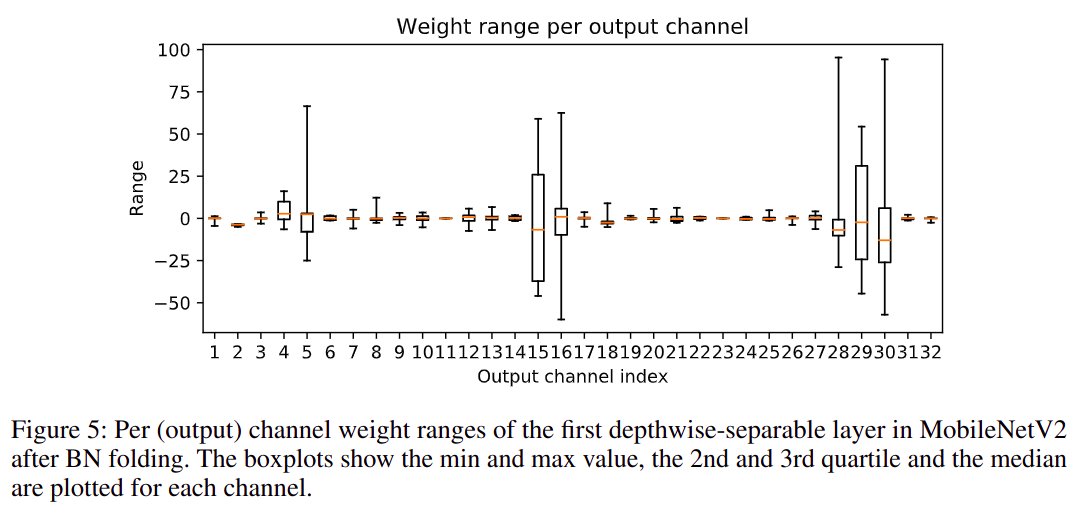
mobilenetv2第一个depth-wise conv层的per output channel weight range
- 想要实现跨层均衡的模型,需要激活函数满足交换律,即:,常见的
ReLU和PReLU都满足。
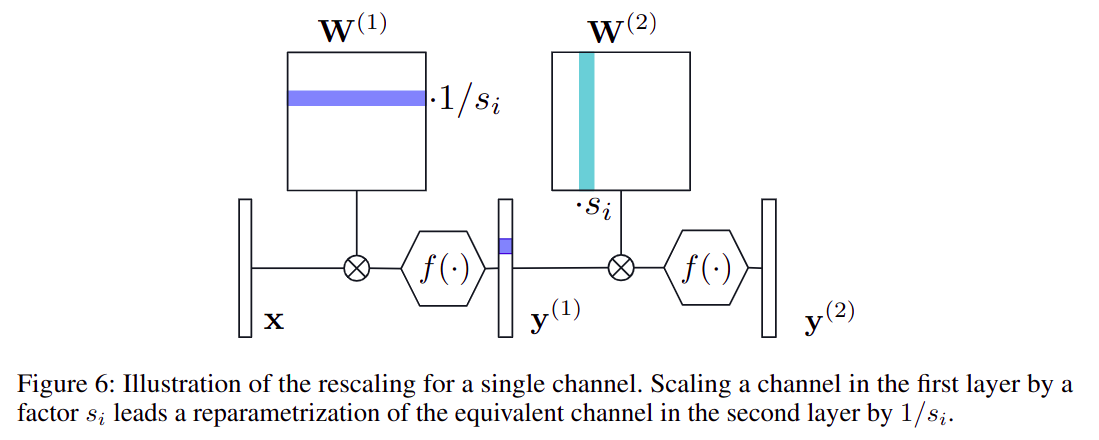
CLE原理:- 其中:
- ,其中 表示
j tensor的i channel
abosrbing high bias是一种 解决模型中过大 bias 的技术,原理是:- 其中:
2.3 偏移校正(Bias correction)
- 偏移校正:通过修改
bias,使得对于相同输入作用在量化前后的权重的输出期望相同 - 用公式解释:
- 这种校正方式可以在不借助
calibration数据集的情况下,单靠计算得到 ,比如通过BN层的runing mean得到 ,
2.4 自适应舍入(AdaRound)
AdaRound目的是为了解决量化中极为关键的痛点:“四舍五入(Round-to-Nearest,RTN)并不一定是取整最优解”AdaRound的核心思想:- 将 “取整” 这个离散的、不可导的动作,转成一个针对特定数据分布的、连续可导的优化问题。
- 不再进行简单的四舍五入,而是对每一个权重引入一个可学习的决策变量,让模型结合少量的校准集,自己决定每个权重是应该“向下取整(
Floor)”还是“向上取整(Ceil)”。
- 公式表示:
- 是向下取整
- 是与权重维度完全相同的连续可学习参数
- 是一个连续可导的函数
- :标准的 Sigmoid 函数
- 和 :控制拉伸范围的超参数, 和
- :截断函数,将最终结果强行限制在闭区间 内
- 损失函数设计
- 是原始浮点层的输出
- 是带有软取整参数层的输出
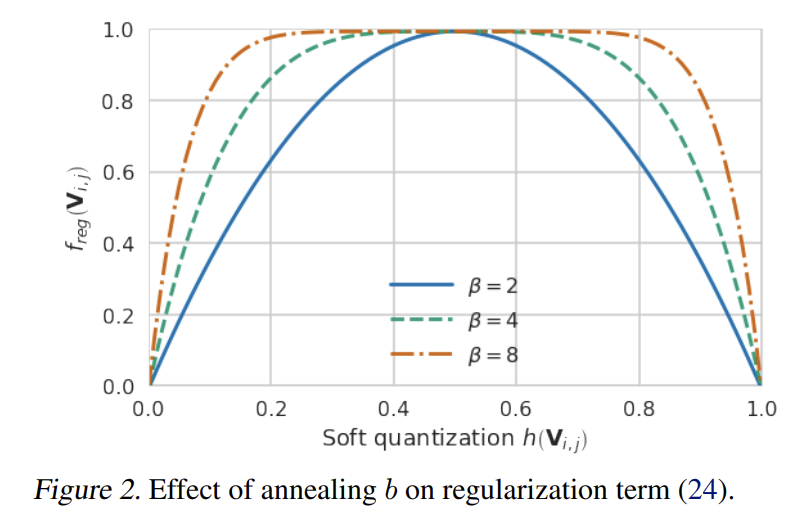
- 是一个正则化项(退火惩罚项)。随着优化的进行,这个正则化项会越来越强,逼迫 的值向 0 或 1 两端极化
- 在训练过程中, 会逐渐降低,从 20 逐渐降低到 2, 越大,曲线顶端越平
2.5 标准的 PTQ 流程
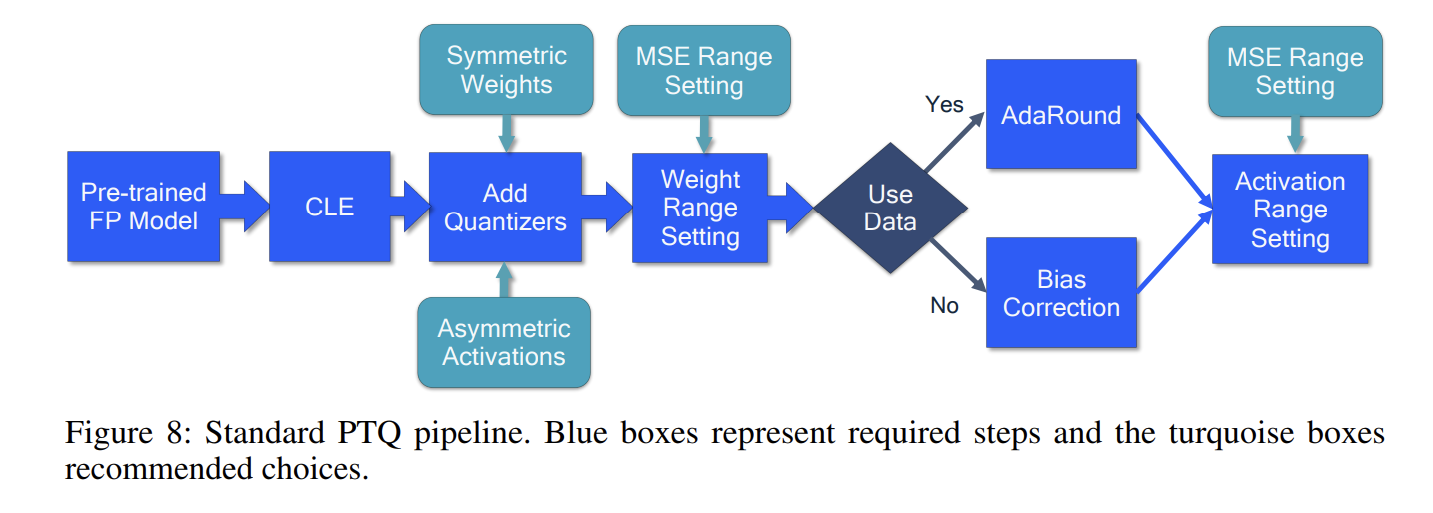
- 跨层均衡
- 添加量化器
- 权重范围设定
- 自适应舍入
- 偏移校正
- 激活范围设定
2.6 PTQ debug 流程
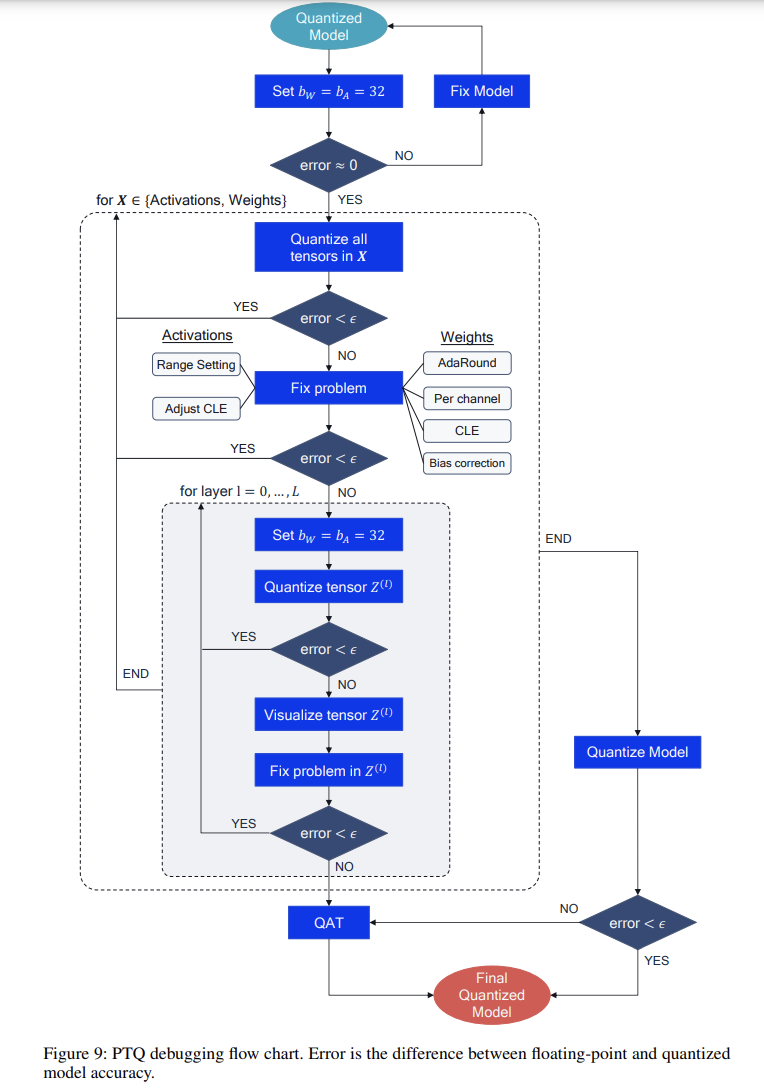
FP32健全性检查- 权重或激活量化
- 修复权重量化
- 修复激活量化
- 逐层分析
- 可视化层数据分布
- 修复各个量化器
3. 训练感知量化(QAT,Quantization-aware training)
3.1 模拟量化反向传播
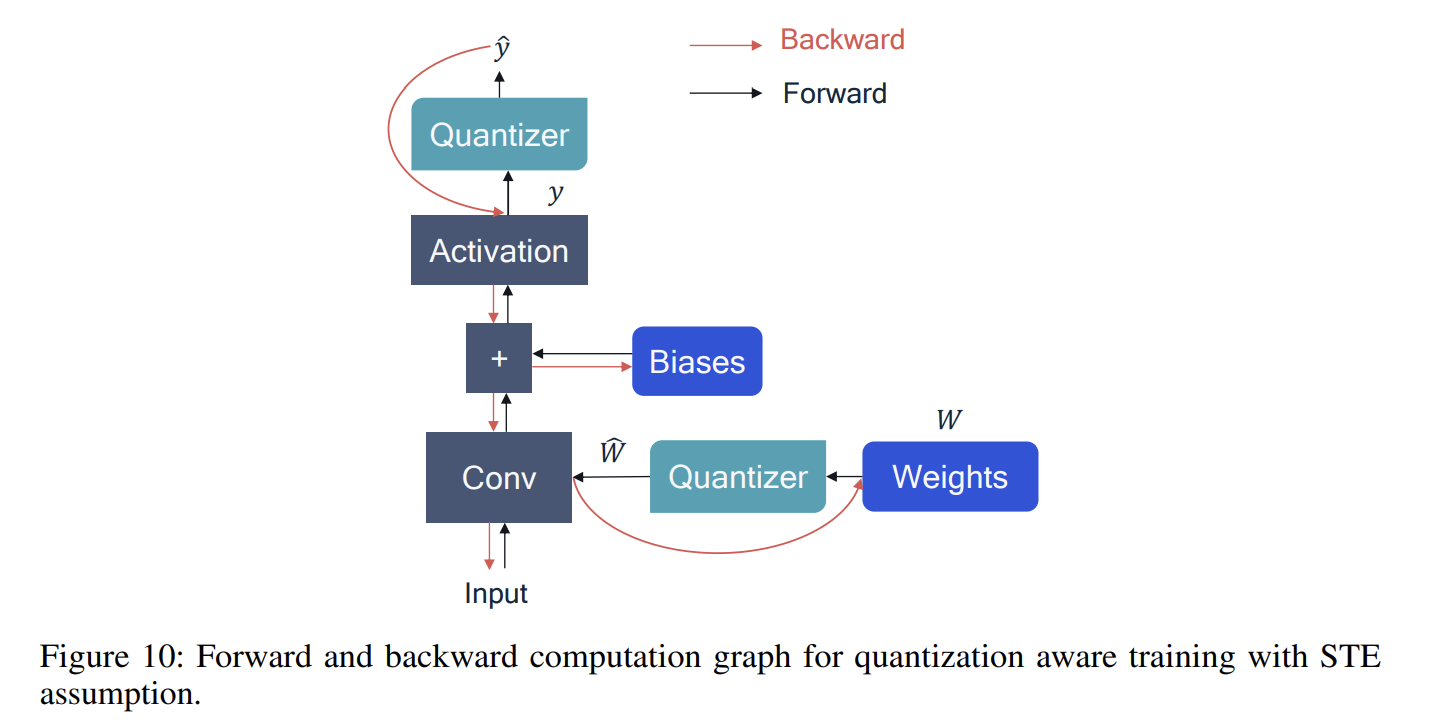
- 红色线表示直通估计器(
STE, straight-through estimator),说人话就是 “由于四舍五入运算不可微,那就让梯度跳过这一层继续向前”
- 被饱和的部分没有梯度(包括
weight和activation)
3.2 BN 折叠
QAT在训练过程中,如果conv可以做per-channel量化,那conv的activation在送入BN之前可以不需要做量化,BN之后做activation的量化- 部署时,
BN的per-channel缩放系数可以和conv的per-channel缩放系数合并
3.3 QAT 初始化
- 更好的初始化可以带来更好的 QAT 结果,但增益通常很小,并且随着训练持续时间的延长而消失。
3.4 标准 QAT 流程
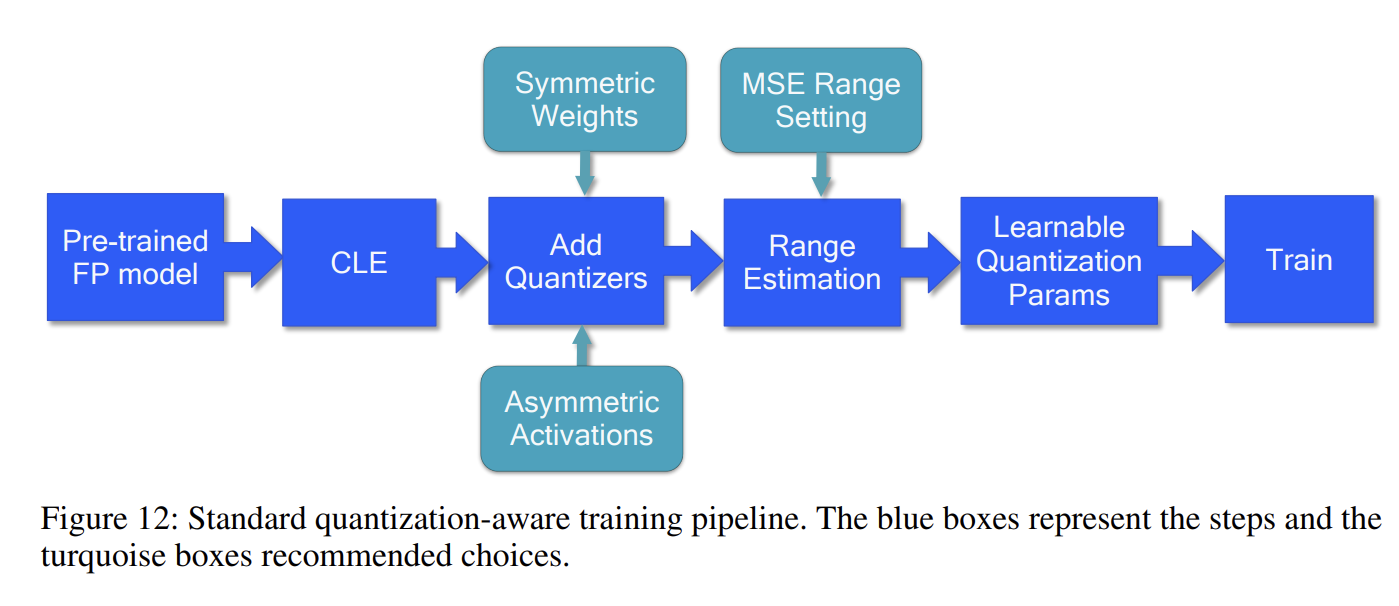
- 跨层均衡
- 添加量化层
- 范围估计
- 量化可学习参数
Thoughts
- 非常全面的讲解了
PTQ和QAT的底层原理,在CNN网络上非常适合 - 对于模型架构的持续迭代,以及的
GPU对低比特浮点数的支持(包括分组量化浮点数类型),给模型量化带来了更多新的课题