URL
TL;DR
- 本文提出一种新型
Transformer结构使用Window Multi-head Self-attention (W-MSA)和Shifted Window Multi-head Self-attention (SW-MSA)结构替代原始Transformer使用的Multi-head Self-attention (MSA)结构。- 大大节省了原始
Transformer的计算复杂度。 - 在视觉任务中吊打了一众
CNN和Transformer。
- 大大节省了原始
Algorithm
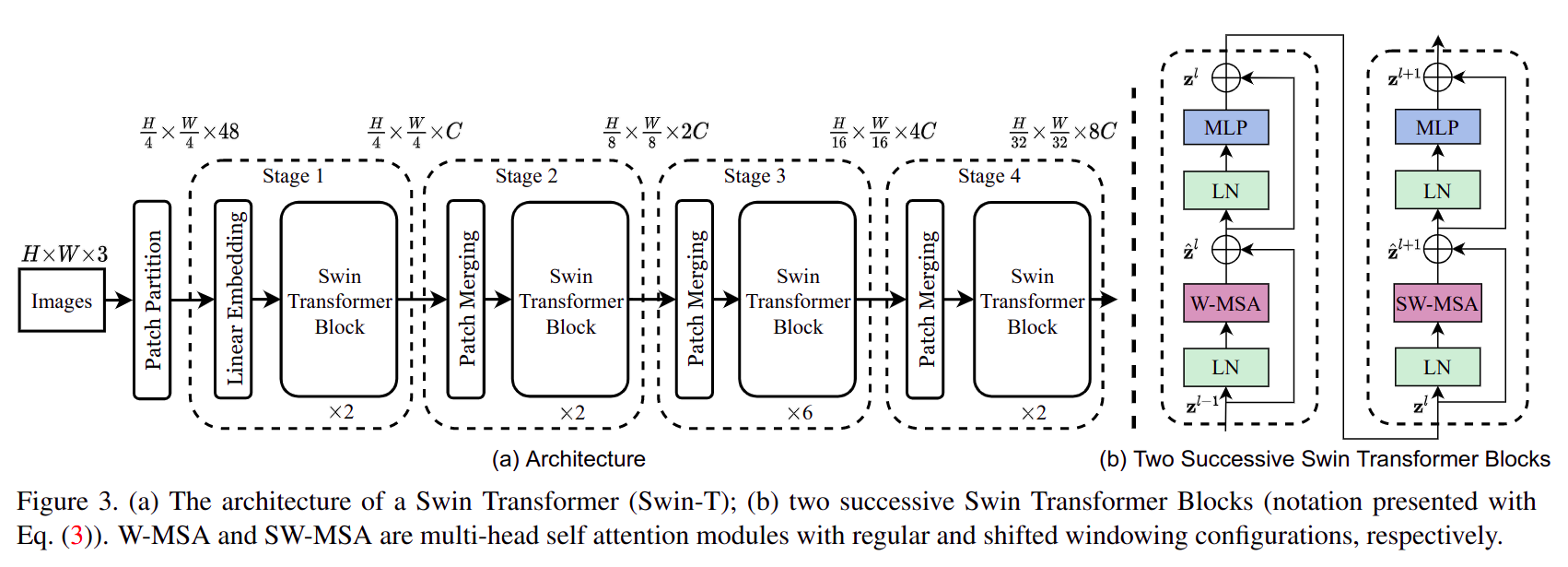
总体结构
swin-Transformer总体按照类似CNN的层次化构建方式构建网络结构,分为 4 个stage,每个stage都会将分辨率缩小一倍,channel数扩大一倍 (like vgg) 。Swin Tranformer Block像大多数Transformer Block一样,不改变输入特征shape,可以看做是一种比较高级(加入了 self-attention)的激活函数。- 图中
Swin Tranformer Block都是以连续偶数次出现,因为是一个W-MSA Transformer Block+ 一个SW-MSA Transformer Block,如右边子图 b 所示。
Patch Partition
- 作用与
ViT第一步很像:将图片切成若干等大小不重叠的patch,patch_size= P,然后把每个patch从(P, P, c)拉成 1 维。 - 本实验中
patch_size = 4,所以一张图被裁切成了 个长度为4 * 4 * 3 = 48的向量。
Linear Embedding
- 与一个
shape = (48, C)的矩阵乘将48维映射到C维。
与上一步结合可以变成一个 in_channel = 3, out_channel = C, kernel_size = stride = 4 的 Conv2d,官方实现中实际上也是这么做的(
class PatchEmbed)。
Patch Merging
- 由两步组成,作用是 将分辨率缩小一倍,channel 扩大一倍。
- 将 的输入使用
bayer2rggb (space2depth with block_size = 2)变成 。 - 再将 与一个 的矩阵相乘,输出一个 的矩阵。
- 将 的输入使用
W-MSA
- 全称为
Windows Multi-head Self-attention,目的是为了减少Self-attention计算量。- 原始的
MSA会直接对完整输入计算其self-attention结果 W-MSA先将输入拆成大小为 且互不重叠的windows,然后计算每个window的self-attention结果。- 计算公式还是:
- 原始的
MSA和W-MSA计算量对比(假设输入特征图 ,且 ,且Multi-head的head数为 1):-
MSA计算量:-
X -> Q / K / V 计算量: 计算量为 。
-
计算量: 计算量为 。
-
不考虑 softmax 和 计算量。
-
softmax 结果 计算量: 计算量为 。
-
因为需要
Multi-head,所以需要将 之后的矩阵再 ,且head数为 1,计算量: 计算量为 。 -
总计算量: 。
-
-
W-MSA计算量:- 上图的 ,一共重复 次,所以总计算量为:
-
相比之下
W-MSA会比WSA计算量少: 。
-
SW-MSA
- 为了节省计算量
W-MSA会将输入的完整特征图分 window,每个 window 独立去做 self-attention,这会导致 window 之间的关联性消失,这有悖于 self-attention 会在全图上建立长距离全局相关性依赖的特点。 - 所以,作者引入
SW-MSA的方案通过 滑窗 解决这一问题。
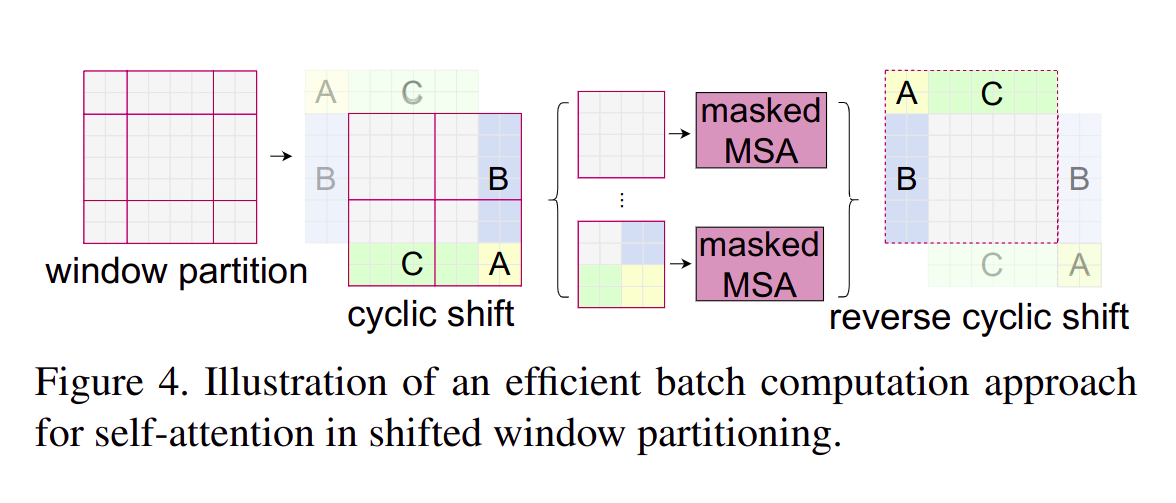
- 滑窗会带来边角处的零碎区域(长或宽小于
window_size的区域),由于 (W-MSA要求),所以零碎的区域可以通过调整位置拼成完整window。 - 完整的滑窗区域与
W-MSA一样独立做Self-attention。 - 由零碎区域拼成的滑窗区域中:
-
本属于同一零碎区域的位置可以
Self-attention。 -
本不属于同一零碎区域的位置在原图上不相邻,不能做
Self-attention。 -
具体做法是来自不同区域位置之间的
Self-attention被 mask 掉 ,只保留来自相同区域的位置间的Self-attention。
-
W-MSA + SW-MSA
- 如网络结构图子图 b 所示,
W-MSA连接SW-MSA之后,数学表示:
Relative Position Bias
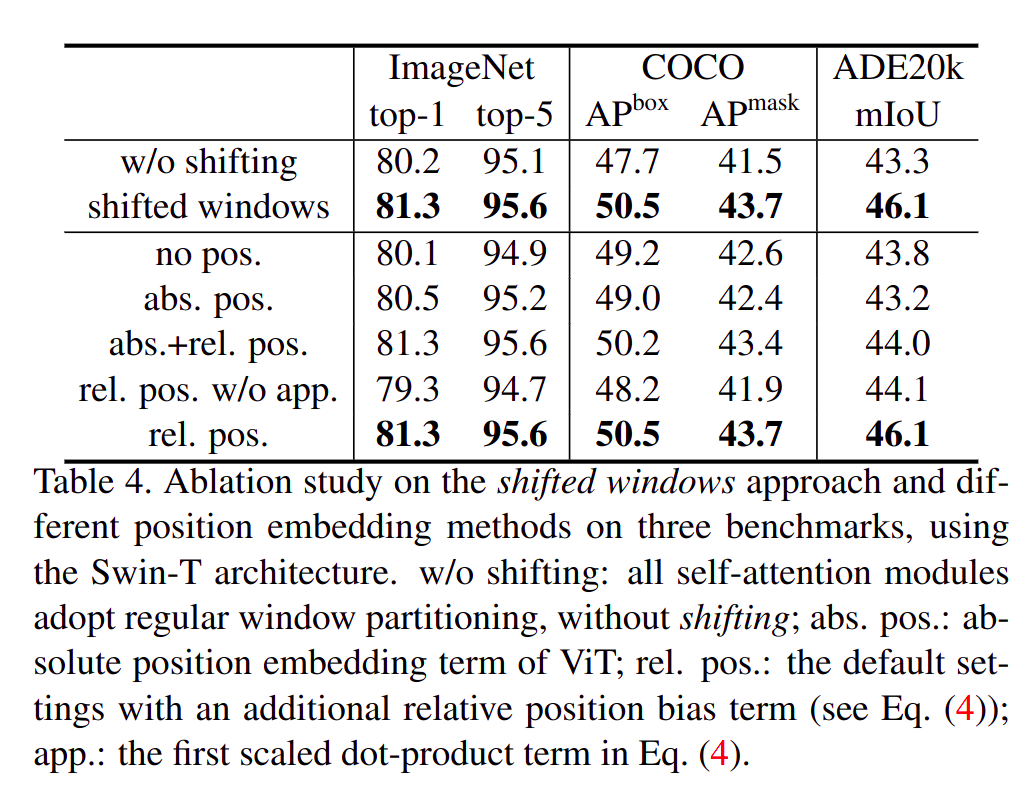
- 对
Self-attention加上 相对位置偏置bias之后,精度提升巨大。 - 原始
Self-attention: 。 Relative Position Bias Self-attention: 。
Through
- 质疑了很多人都没有质疑的点,例如给
Self-attention加上相对位置偏置。 - 本质是对
Tranformer的一种很 work 的加速方法。 - 但
Shift window逻辑比较复杂,没有经典模型该有的简约美,盲猜之后会被更make sense的结构替代。