URL
- paper: https://arxiv.org/pdf/2008.05711.pdf
- code: https://github.com/real-zhangzhe/lift-splat-shoot (fork from official implementation, adding comments and predictions)
TL;DR
- 本文是
BEV (bird eye view)的开山之作,通过隐式2D深度估计和像素坐标到世界坐标转换,将多张(6张)车周环视图拼接得到一张鸟瞰图。 - 具体实现请看代码,代码中有非常详细的注释。
Algorithm
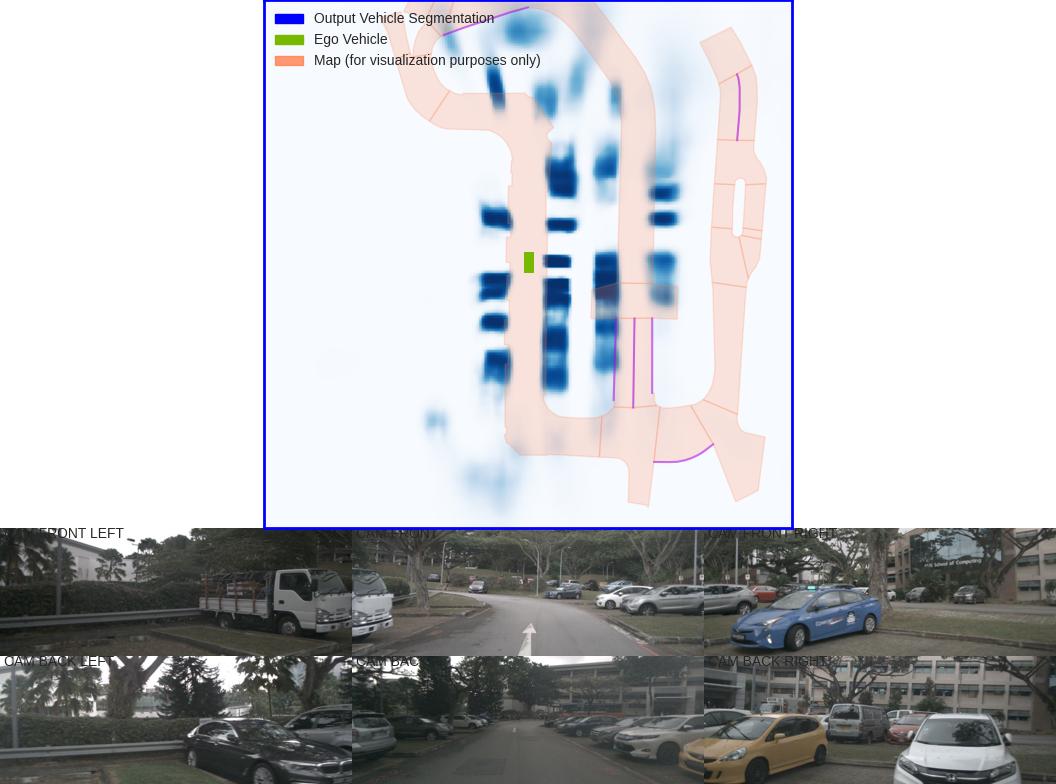
在 inference 过程中,下半部分的 6 张环视图为输入,上半部分的鸟瞰图为输出(地图和本算法无关)。
Dataset
- 本文使用自动驾驶数据集
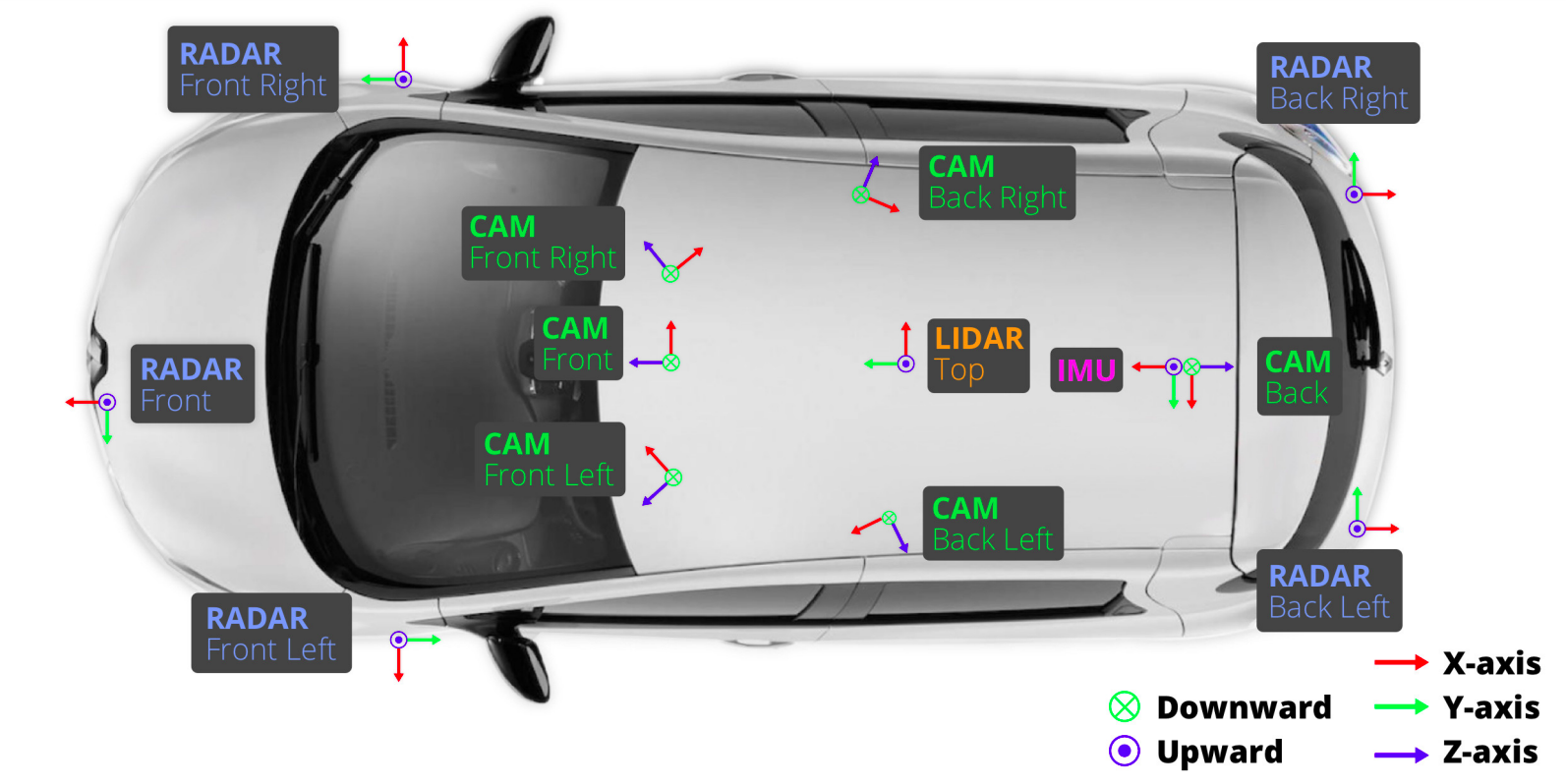
nuScense - 输入的 6 张图来自上图的 6 个绿色 camera
- 世界坐标系如图
IMU所示原点定为 车后轴中心,x轴正方向为车辆前进方向,y轴正方向为面向车辆前进方向的左手边,z轴正方向为竖直向上。
相关知识
- 相机内外参:参考 相机内参与外参
- 体素:
- 立体像素
- 在本文中,一个体素表示 x 方向上 0.5m,y 方向上 0.5m,z 方向上 20m 的立方体区域
- 体素为鸟瞰视角中可区分的最小单元
算法细节
特别细节的看代码
1. 特征提取(Lift)
- 使用
EfficientNet进行2D特征提取 + 隐式深度估计- 输入:
shape = [4, 6, 3, 128, 352],分别表示:[batch, cameras, channel, height, width] - 输出:
shape = [24, 64, 41, 8, 22],分别表示:[batch * cameras, features, depth, height, width]- 使用
64维向量编码深度(不是直接预测深度,所以被称为隐式深度估计) - 深度从
4m ~ 45m,编码精度为1m,所以有41种离散深度,相机坐标系下深度估计的目的是:从像素坐标转化为世界坐标 - 长宽各下采样
16倍,减小计算量
- 使用
- 输入:
2. 像素坐标和相机坐标系下深度到世界坐标的映射(Splat)
- 使用如下参数将像素坐标和相机坐标系下深度映射到世界坐标
- 相机内参
- 相机外参
- 旋转
- 平移
- 像素坐标系内变换参数(缩放 + 裁剪(平移))
- 原图(900, 1600) -> 模型输入图(128, 352) -> 模型预测图(8, 22)
- 体素池化:将属于同一个体素的深度估计向量求和
- 输入:
- 深度估计:
shape = [24, 64, 41, 8, 22] - 相机内外参和缩放参数
- 深度估计:
- 输出:
shape = [4, 64, 200, 200]200 * 200个体素- X 方向上 [-50m, 50m) 0.5m 为一个 bin,200 个 bin
- Z 方向上 [-50m, 50m) 0.5m 为一个 bin,200 个 bin
- Y 方向不分 bin
- 每个体素用
64维向量编码
- 本质是:
- 构造一个 [24 * 41 * 8 * 22, 3] 的查找表,输入为 backbone 输出特征图的每一个 pixel,输出为这个 pixel 对应的世界坐标(这个查找表可由相机内外参和图像缩放系数计算得到)
- 将离散的世界坐标点合并,合并规则是属于同一个体素的坐标点则合并
3. 体素编码降维(Shoot)
- 输入:
shape = [4, 64, 200, 200] - 输出:
shape = [4, 1, 200, 200],BEV 图
4. 训练 loss
非常简单粗暴
- 将 GT bbox3d 同样映射到 BEV 空间 [4, 1, 200, 200],然后做 pixel-wise loss(分割 loss)
Thought
- 代码中 像素坐标和相机坐标系下深度到世界坐标的映射 部分比较难懂,需要较强的相机成像原理 / 图像
2D转3D背景才能看懂