URL
背景知识
- CUDA(Compute Unified Device Architecture,同一计算设备架构)教程:
GPU 体系结构
- 物理模型
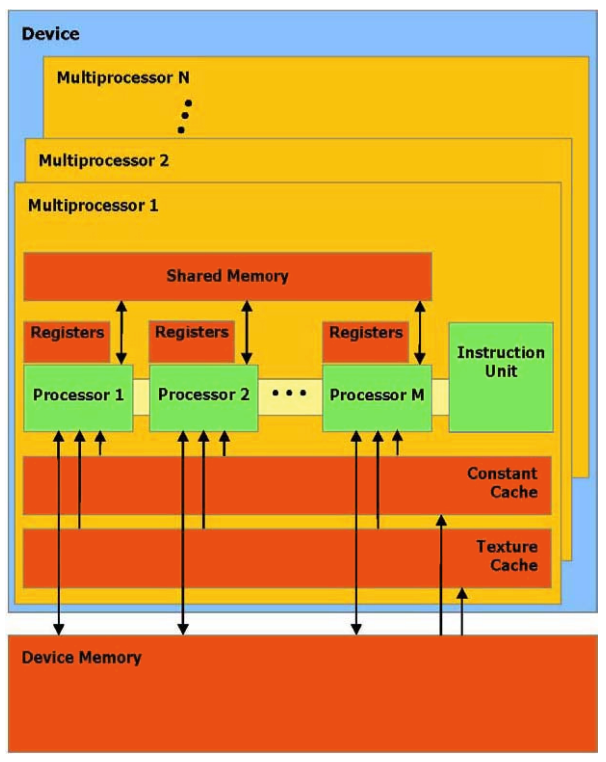
- 典型的
GPU包含一组流处理器 (stream multi-processors,SM),每个流处理器都有许多核心,硬件实现上这些核心之间可共享内存(shared memory)
- 典型的
- 逻辑模型
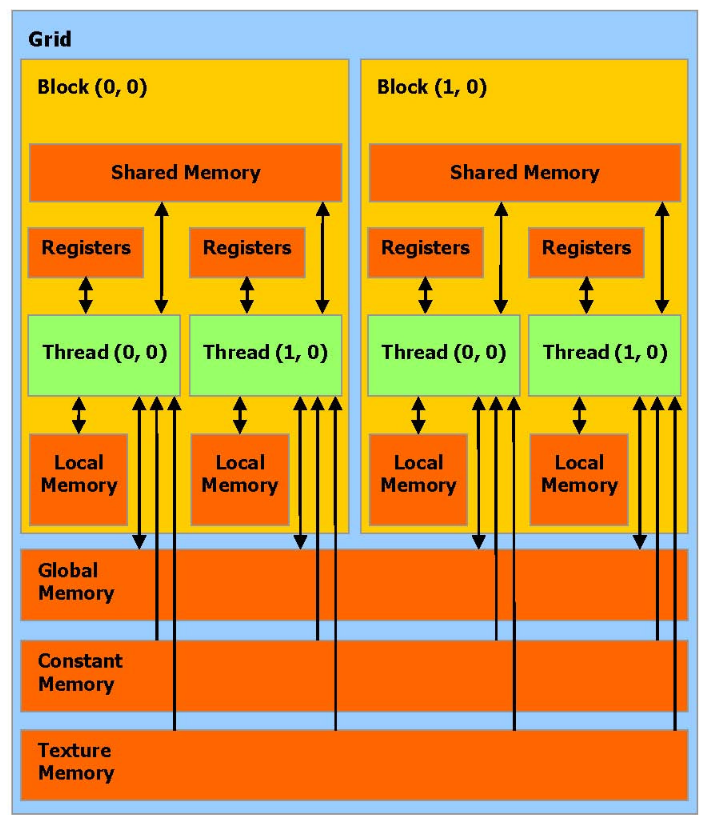
- 逻辑模型中,引入了
Grid/Block/Thread三级概念,逻辑模型与物理的对应关系如下图所示:
因此:同一个
Block中的Thread可共享shared memory
- 逻辑模型中,引入了
- Memory Hierarchy
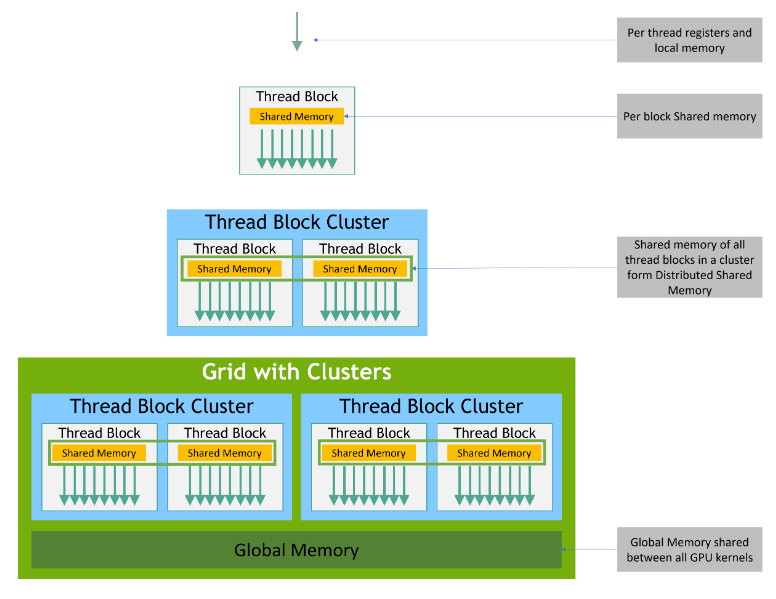
shared memory速度几乎和 L1 cache 一样,比local memory和global memory都快的多(在物理上,local memory和global memory是同一块DRAM) - 在对
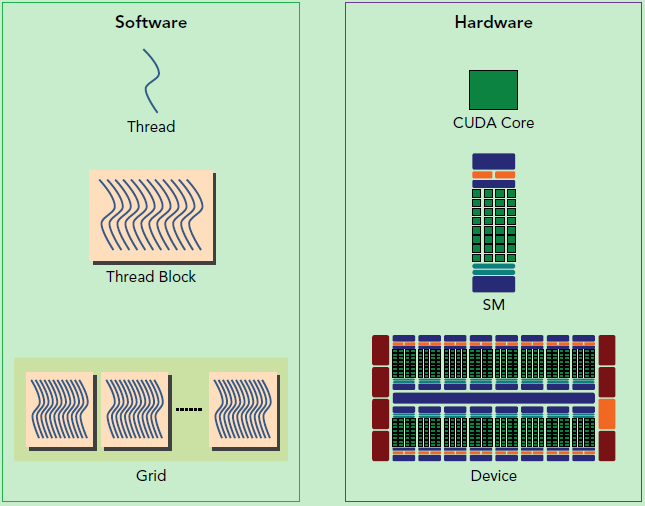
GPU进行编程时,需要创建一组进程块 (thread blocks),每个thread映射到单个核心,而block映射到流式多处理器 (SM),如下图所示:
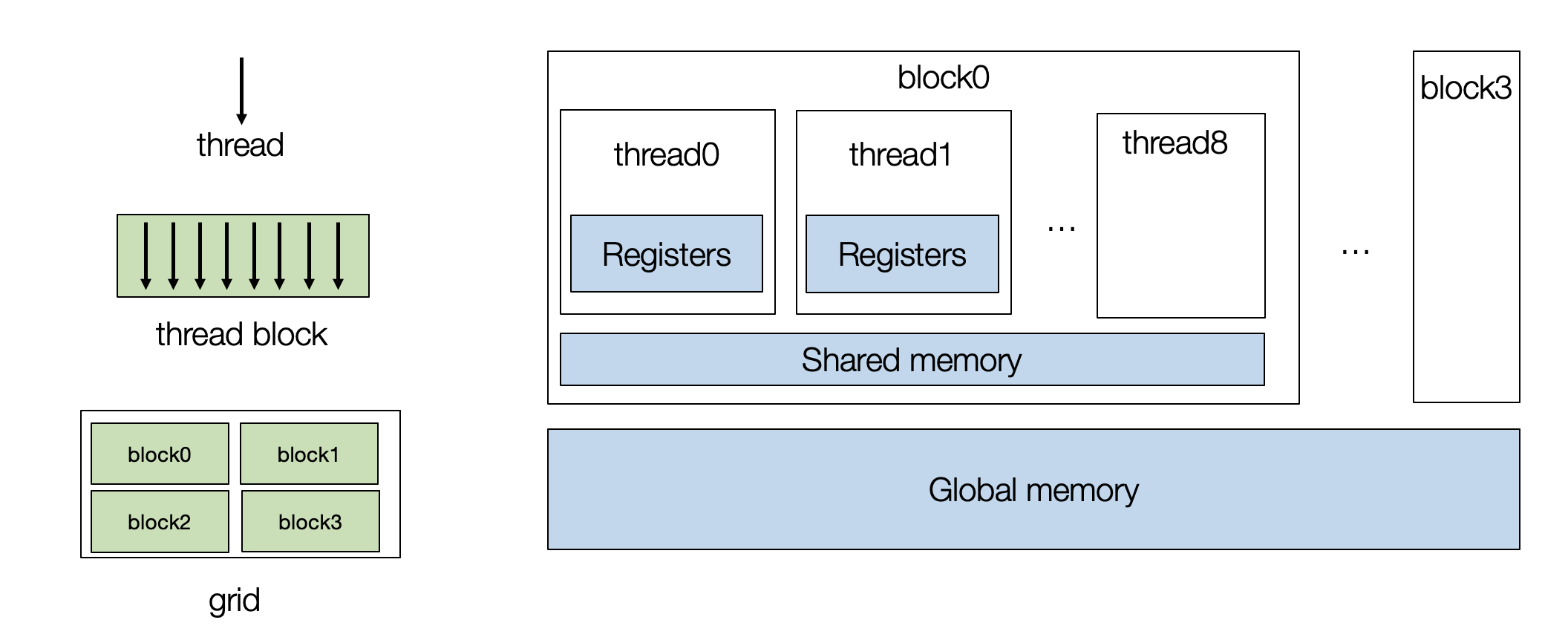
- 每个线程可由
threadIdx和blockIdx索引,在实际应用中,可以有多维线程索引
Element-wise Add GPU 加速
- 两个向量 A 和 B,向量长度都为 1024,执行元素相加,并将结果存储在 C 中
1
2
3
4
5
6
7
8
9
10
11
class MyModuleVecAdd:
def main(A: T.Buffer[(1024,), "float32"],
B: T.Buffer[(1024,), "float32"],
C: T.Buffer[(1024,), "float32"]) -> None:
T.func_attr({"global_symbol": "main", "tir.noalias": True})
for i in T.grid(1024):
with T.block("C"):
vi = T.axis.remap("S", [i])
C[vi] = A[vi] + B[vi] - 首先将循环 i 拆分成两个循环:
1
2
3
4sch = tvm.tir.Schedule(MyModuleVecAdd)
block_C = sch.get_block("C")
i, = sch.get_loops(block=block_C)
i0, i1 = sch.split(i, [None, 128]) - 将迭代器绑定到 GPU 线程块。 每个线程由两个索引进行表示
threadIdx.x和blockIdx.x1
2
3sch.bind(i0, "blockIdx.x")
sch.bind(i1, "threadIdx.x")
sch.mod.show() - 绑定后的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class Module:
def main(A: T.Buffer[1024, "float32"], B: T.Buffer[1024, "float32"], C: T.Buffer[1024, "float32"]) -> None:
# function attr dict
T.func_attr({"global_symbol": "main", "tir.noalias": True})
# body
# with T.block("root")
for i_0 in T.thread_binding(8, thread="blockIdx.x"):
for i_1 in T.thread_binding(128, thread="threadIdx.x"):
with T.block("C"):
vi = T.axis.spatial(1024, i_0 * 128 + i_1)
T.reads(A[vi], B[vi])
T.writes(C[vi])
C[vi] = A[vi] + B[vi] - 由于
Element-wise Add不存在数据依赖,所以可以直接拆分到多个block中的多个thread中,一个cycle全部算完
窗口求和 GPU 加速
- 相邻三个窗口求和,输入向量 A 长度 1026,输出 B 长度 1024。(即无 padding 的权重为 [1, 1, 1] 的 conv1d)
1
2
3
4
5
6
7
8
9
10
class MyModuleWindowSum:
def main(A: T.Buffer[(1026,), "float32"],
B: T.Buffer[(1024,), "float32"]) -> None:
T.func_attr({"global_symbol": "main", "tir.noalias": True})
for i in T.grid(1024):
with T.block("C"):
vi = T.axis.remap("S", [i])
B[vi] = A[vi] + A[vi + 1] + A[vi + 2] - 拆分循环并绑定到
block和thread1
2
3
4
5
6
7
8sch = tvm.tir.Schedule(MyModuleWindowSum)
nthread = 128
block_C = sch.get_block("C")
i, = sch.get_loops(block=block_C)
i0, i1 = sch.split(i, [None, nthread])
sch.bind(i0, "blockIdx.x")
sch.bind(i1, "threadIdx.x")
sch.mod.show() - 拆分循环后
IRModule1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
class Module:
def main(A: T.Buffer[1027, "float32"], B: T.Buffer[1024, "float32"]) -> None:
# function attr dict
T.func_attr({"global_symbol": "main", "tir.noalias": True})
# body
# with T.block("root")
for i_0 in T.thread_binding(8, thread="blockIdx.x"):
for i_1 in T.thread_binding(128, thread="threadIdx.x"):
# 启用 8 个 block 并发计算,每个 block 用 16 个 thread 并发
# 因此每一个 thread 只需要计算 1 次乘加
with T.block("C"):
vi = T.axis.spatial(1024, i_0 * 128 + i_1)
T.reads(A[vi : vi + 3])
T.writes(B[vi])
B[vi] = A[vi] + A[vi + 1] + A[vi + 2] - 提前缓存数据
1
2
3A_shared = sch.cache_read(block_C, read_buffer_index=0, storage_scope="shared")
sch.compute_at(A_shared, i1)
sch.mod.show() - 提前缓存数据后的
IRModule1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
class Module:
def main(A: T.Buffer[1027, "float32"], B: T.Buffer[1024, "float32"]) -> None:
# function attr dict
T.func_attr({"global_symbol": "main", "tir.noalias": True})
# body
# with T.block("root")
A_shared = T.alloc_buffer([1027], dtype="float32", scope="shared")
for i_0 in T.thread_binding(8, thread="blockIdx.x"):
for i_1 in T.thread_binding(128, thread="threadIdx.x"):
# 由上图 GPU 结构图可知
# 不同 block 无法共享 share memory
# 相同 block 的不同 thread 之间可以共享
# 所以输出 128 个结果需要 130 个输入(本行 128 个加下一行 2 个)
for ax0 in T.serial(130):
with T.block("A_shared"):
v0 = T.axis.spatial(1027, i_0 * 128 + ax0)
T.reads(A[v0])
T.writes(A_shared[v0])
A_shared[v0] = A[v0]
with T.block("C"):
vi = T.axis.spatial(1024, i_0 * 128 + i_1)
T.reads(A_shared[vi : vi + 3])
T.writes(B[vi])
B[vi] = A_shared[vi] + A_shared[vi + 1] + A_shared[vi + 2] - 缓存数据可以使用多线程优化
- 因为内存是跨线程共享的,所以需要重新拆分循环并将获取过程的内部迭代器绑定到线程索引上,这种技术称为
cooperative fetching
1
2
3
4ax = sch.get_loops(A_shared)[-1]
ax0, ax1 = sch.split(ax, [None, nthread])
sch.bind(ax1, "threadIdx.x")
sch.mod.show() - 因为内存是跨线程共享的,所以需要重新拆分循环并将获取过程的内部迭代器绑定到线程索引上,这种技术称为
- 缓存数据优化后
IRModule1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
class Module:
def main(A: T.Buffer[1026, "float32"], B: T.Buffer[1024, "float32"]) -> None:
# function attr dict
T.func_attr({"global_symbol": "main", "tir.noalias": True})
# body
# with T.block("root")
A_shared = T.alloc_buffer([1026], dtype="float32", scope="shared")
for i_0 in T.thread_binding(8, thread="blockIdx.x"):
for i_1 in T.thread_binding(128, thread="threadIdx.x"):
for ax0_0 in T.serial(2):
for ax0_1 in T.thread_binding(128, thread="threadIdx.x"):
with T.block("A_shared"):
# 由上图 GPU 结构图可知
# 不同 block 无法共享 share memory
# 相同 block 的不同 thread 之间可以共享
# 所以输出 128 个结果需要 130 个输入(本行 128 个加下一行 2 个)
v0 = T.axis.spatial(1026, i_0 * 128 + (ax0_0 * 128 + ax0_1))
T.where(ax0_0 * 128 + ax0_1 < 130)
T.reads(A[v0])
T.writes(A_shared[v0])
A_shared[v0] = A[v0]
with T.block("C"):
vi = T.axis.spatial(1024, i_0 * 128 + i_1)
T.reads(A_shared[vi : vi + 3])
T.writes(B[vi])
B[vi] = A_shared[vi] + A_shared[vi + 1] + A_shared[vi + 2]
矩阵乘法 GPU 加速
IRModule基础实现:1
2
3
4
5
6
7
8
9
10
11
12
13
class MyModuleMatmul:
def main(A: T.Buffer[(1024, 1024), "float32"],
B: T.Buffer[(1024, 1024), "float32"],
C: T.Buffer[(1024, 1024), "float32"]) -> None:
T.func_attr({"global_symbol": "main", "tir.noalias": True})
for i, j, k in T.grid(1024, 1024, 1024):
with T.block("C"):
vi, vj, vk = T.axis.remap("SSR", [i, j, k])
with T.init():
C[vi, vj] = 0.0
C[vi, vj] = C[vi, vj] + A[vi, vk] * B[vk, vj]- 绑定
block和thread+ 本地存储分块优化
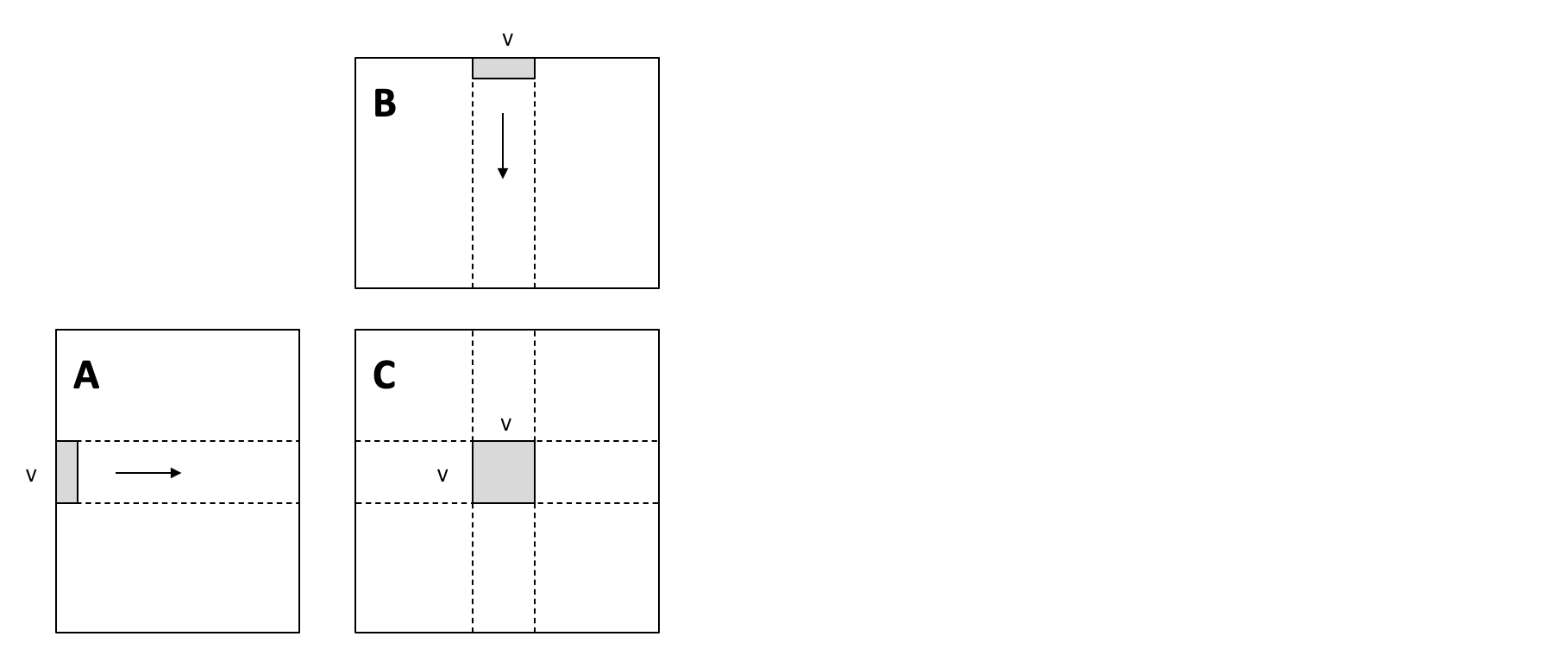
循环拆分,来增加整体内存复用,只需要从
A和B加载一次条形数据(上图中的灰色部分),然后使用它们来计算矩阵乘法结果
下面代码中设置V = 81
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24def blocking(sch,
tile_local_y,
tile_local_x,
tile_block_y,
tile_block_x,
tile_k):
block_C = sch.get_block("C")
C_local = sch.cache_write(block_C, 0, "local")
i, j, k = sch.get_loops(block=block_C)
i0, i1, i2 = sch.split(loop=i, factors=[None, tile_block_y, tile_local_y])
j0, j1, j2 = sch.split(loop=j, factors=[None, tile_block_x, tile_local_x])
k0, k1 = sch.split(loop=k, factors=[None, tile_k])
sch.unroll(k1)
sch.reorder(i0, j0, i1, j1, k0, k1, i2, j2)
sch.reverse_compute_at(C_local, j1)
sch.bind(i0, "blockIdx.y")
sch.bind(j0, "blockIdx.x")
sch.bind(i1, "threadIdx.y")
sch.bind(j1, "threadIdx.x")
sch.decompose_reduction(block_C, k0)
return sch
sch = tvm.tir.Schedule(MyModuleMatmul)
sch = blocking(sch, 8, 8, 8, 8, 4)
sch.mod.show() - 输出优化后的
IRModule1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
class Module:
def main(A: T.Buffer[(1024, 1024), "float32"], B: T.Buffer[(1024, 1024), "float32"], C: T.Buffer[(1024, 1024), "float32"]) -> None:
# function attr dict
T.func_attr({"global_symbol": "main", "tir.noalias": True})
# body
# with T.block("root")
C_local = T.alloc_buffer([1024, 1024], dtype="float32", scope="local")
for i_0 in T.thread_binding(16, thread="blockIdx.y"):
for j_0 in T.thread_binding(16, thread="blockIdx.x"):
for i_1 in T.thread_binding(8, thread="threadIdx.y"):
for j_1 in T.thread_binding(8, thread="threadIdx.x"):
# 一共使用 16 * 16 个 block 并发计算
# 每个 block 使用 8 * 8 个 thread 并发
# 所以每个 thread 只需计算输出为 8 * 8 的区域,因此只需要加载 A 中 8 行和 B 中 8 列数据
# 1. 初始化 8 * 8 的输出区域为 0
for i_2_init, j_2_init in T.grid(8, 8):
with T.block("C_init"):
vi = T.axis.spatial(1024, i_0 * 64 + i_1 * 8 + i_2_init)
vj = T.axis.spatial(1024, j_0 * 64 + j_1 * 8 + j_2_init)
T.reads()
T.writes(C_local[vi, vj])
C_local[vi, vj] = T.float32(0)
# 2. 计算 8 * 8 输出区域的值,共计算 8 * 8 * 1024 次乘加
for k_0 in T.serial(256):
for k_1 in T.unroll(4):
for i_2, j_2 in T.grid(8, 8):
with T.block("C_update"):
vi = T.axis.spatial(1024, i_0 * 64 + i_1 * 8 + i_2)
vj = T.axis.spatial(1024, j_0 * 64 + j_1 * 8 + j_2)
vk = T.axis.reduce(1024, k_0 * 4 + k_1)
T.reads(C_local[vi, vj], A[vi, vk], B[vk, vj])
T.writes(C_local[vi, vj])
C_local[vi, vj] = C_local[vi, vj] + A[vi, vk] * B[vk, vj]
# 3. 把每个 thread 的 8 * 8 的输出区域拼成最后的 1024 * 1024 的输出
for ax0, ax1 in T.grid(8, 8):
with T.block("C_local"):
v0 = T.axis.spatial(1024, i_0 * 64 + i_1 * 8 + ax0)
v1 = T.axis.spatial(1024, j_0 * 64 + j_1 * 8 + ax1)
T.reads(C_local[v0, v1])
T.writes(C[v0, v1])
C[v0, v1] = C_local[v0, v1] - 共享内存优化
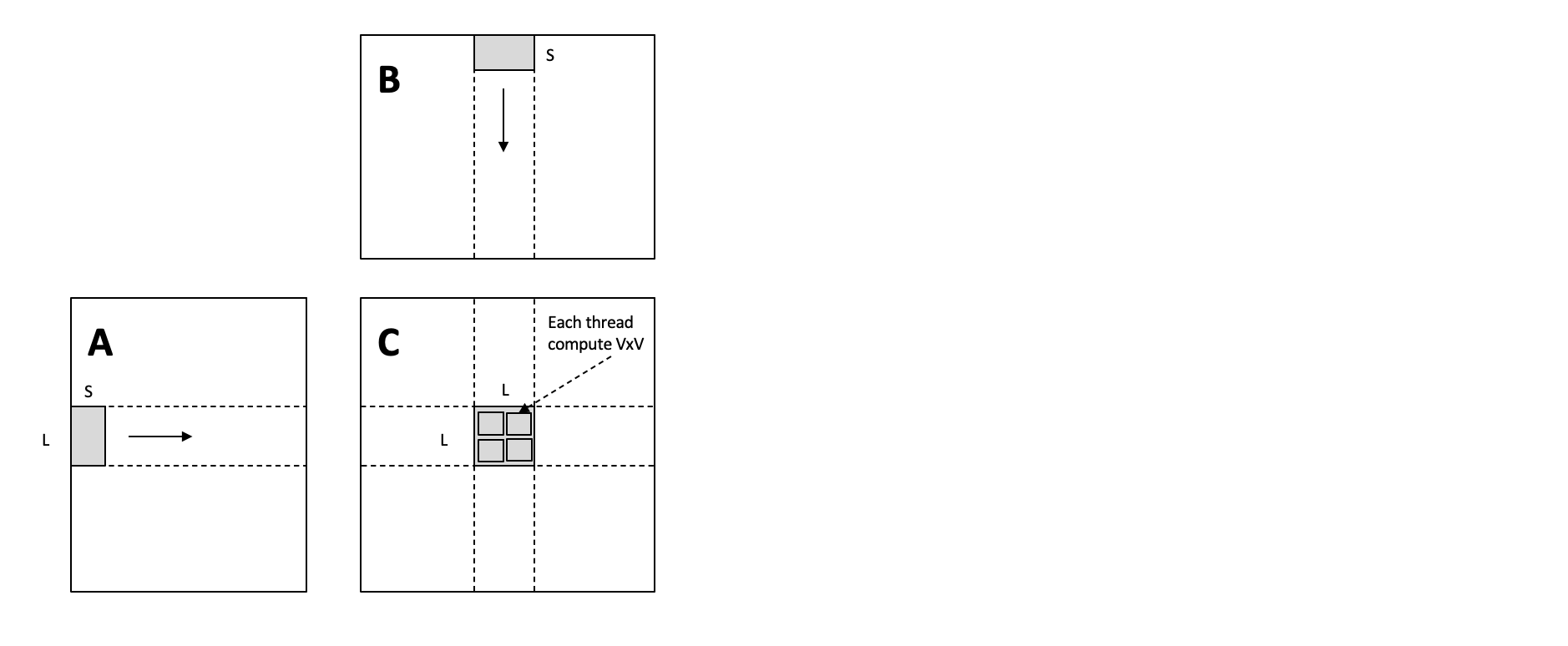
与上图不同,图中矩阵 C 中
L * L灰色区域表示一个block的计算输出
每个L * L灰色区域由多个V * V的小区域组成,表示一个thread的输出-
同一个
block中的多个thread可共享内存,因此可以重排同一个block中的thread数据,使得尽可能少的数据缓存到shared memory中 -
优化前:
- 每个
thread需要计算输出矩阵中8 * 8的数据,需要从local memory中读取8 * 8 * 1024 * 2数据 - 每个
block中的thread之间没有数据共享,所以需要从local memory中读取 个矩阵元素
- 每个
-
优化后:
- 每个
block计算输出矩阵的64 * 64的数据最少需要 的数据,可提前将这部分数据缓存到shared memory - 然后每个
thread从shared memory读数据计算,需读取 个数据
- 每个
-
内存优化前后每个
block读取数据对比:- 优化前:从
local memory读取 个矩阵元素 - 优化后:从
local memory读取 个矩阵元素到shared memory,再从shared memory读取 个数据计算
- 优化前:从
-
优化过程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36def cache_read_and_coop_fetch(sch, block, nthread, read_idx, read_loc):
read_cache = sch.cache_read(block=block, read_buffer_index=read_idx, storage_scope="shared")
sch.compute_at(block=read_cache, loop=read_loc)
# vectorized cooperative fetch
inner0, inner1 = sch.get_loops(block=read_cache)[-2:]
inner = sch.fuse(inner0, inner1)
_, tx, vec = sch.split(loop=inner, factors=[None, nthread, 4])
sch.vectorize(vec)
sch.bind(tx, "threadIdx.x")
def blocking_with_shared(
sch,
tile_local_y,
tile_local_x,
tile_block_y,
tile_block_x,
tile_k):
block_C = sch.get_block("C")
C_local = sch.cache_write(block_C, 0, "local")
i, j, k = sch.get_loops(block=block_C)
i0, i1, i2 = sch.split(loop=i, factors=[None, tile_block_y, tile_local_y])
j0, j1, j2 = sch.split(loop=j, factors=[None, tile_block_x, tile_local_x])
k0, k1 = sch.split(loop=k, factors=[None, tile_k])
sch.reorder(i0, j0, i1, j1, k0, k1, i2, j2)
sch.reverse_compute_at(C_local, j1)
sch.bind(i0, "blockIdx.y")
sch.bind(j0, "blockIdx.x")
tx = sch.fuse(i1, j1)
sch.bind(tx, "threadIdx.x")
nthread = tile_block_y * tile_block_x
cache_read_and_coop_fetch(sch, block_C, nthread, 0, k0)
cache_read_and_coop_fetch(sch, block_C, nthread, 1, k0)
sch.decompose_reduction(block_C, k0)
return sch
sch = tvm.tir.Schedule(MyModuleMatmul)
sch = blocking_with_shared(sch, 8, 8, 8, 8, 8)
sch.mod.show()- 优化后
IRModule
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
class Module:
def main(A: T.Buffer[(1024, 1024), "float32"], B: T.Buffer[(1024, 1024), "float32"], C: T.Buffer[(1024, 1024), "float32"]) -> None:
# function attr dict
T.func_attr({"global_symbol": "main", "tir.noalias": True})
# body
# with T.block("root")
C_local = T.alloc_buffer([1024, 1024], dtype="float32", scope="local")
A_shared = T.alloc_buffer([1024, 1024], dtype="float32", scope="shared")
B_shared = T.alloc_buffer([1024, 1024], dtype="float32", scope="shared")
for i_0 in T.thread_binding(16, thread="blockIdx.y"):
for j_0 in T.thread_binding(16, thread="blockIdx.x"):
for i_1_j_1_fused in T.thread_binding(64, thread="threadIdx.x"):
for i_2_init, j_2_init in T.grid(8, 8):
with T.block("C_init"):
vi = T.axis.spatial(1024, i_0 * 64 + i_1_j_1_fused // 8 * 8 + i_2_init)
vj = T.axis.spatial(1024, j_0 * 64 + i_1_j_1_fused % 8 * 8 + j_2_init)
T.reads()
T.writes(C_local[vi, vj])
C_local[vi, vj] = T.float32(0)
for k_0 in T.serial(128):
for ax0_ax1_fused_0 in T.serial(2):
for ax0_ax1_fused_1 in T.thread_binding(64, thread="threadIdx.x"):
for ax0_ax1_fused_2 in T.vectorized(4):
with T.block("A_shared"):
v0 = T.axis.spatial(1024, i_0 * 64 + (ax0_ax1_fused_0 * 256 + ax0_ax1_fused_1 * 4 + ax0_ax1_fused_2) // 8)
v1 = T.axis.spatial(1024, k_0 * 8 + (ax0_ax1_fused_0 * 256 + ax0_ax1_fused_1 * 4 + ax0_ax1_fused_2) % 8)
T.reads(A[v0, v1])
T.writes(A_shared[v0, v1])
A_shared[v0, v1] = A[v0, v1]
for ax0_ax1_fused_0 in T.serial(2):
for ax0_ax1_fused_1 in T.thread_binding(64, thread="threadIdx.x"):
for ax0_ax1_fused_2 in T.vectorized(4):
with T.block("B_shared"):
v0 = T.axis.spatial(1024, k_0 * 8 + (ax0_ax1_fused_0 * 256 + ax0_ax1_fused_1 * 4 + ax0_ax1_fused_2) // 64)
v1 = T.axis.spatial(1024, j_0 * 64 + (ax0_ax1_fused_0 * 256 + ax0_ax1_fused_1 * 4 + ax0_ax1_fused_2) % 64)
T.reads(B[v0, v1])
T.writes(B_shared[v0, v1])
B_shared[v0, v1] = B[v0, v1]
for k_1, i_2, j_2 in T.grid(8, 8, 8):
with T.block("C_update"):
vi = T.axis.spatial(1024, i_0 * 64 + i_1_j_1_fused // 8 * 8 + i_2)
vj = T.axis.spatial(1024, j_0 * 64 + i_1_j_1_fused % 8 * 8 + j_2)
vk = T.axis.reduce(1024, k_0 * 8 + k_1)
T.reads(C_local[vi, vj], A_shared[vi, vk], B_shared[vk, vj])
T.writes(C_local[vi, vj])
C_local[vi, vj] = C_local[vi, vj] + A_shared[vi, vk] * B_shared[vk, vj]
for ax0, ax1 in T.grid(8, 8):
with T.block("C_local"):
v0 = T.axis.spatial(1024, i_0 * 64 + i_1_j_1_fused // 8 * 8 + ax0)
v1 = T.axis.spatial(1024, j_0 * 64 + i_1_j_1_fused % 8 * 8 + ax1)
T.reads(C_local[v0, v1])
T.writes(C[v0, v1])
C[v0, v1] = C_local[v0, v1] -
程序自动变换
1 | from tvm import meta_schedule as ms |