CUDA(Compute Unified Device Architecture,统一计算设备架构)资料:
GPU 体系结构
- 物理模型
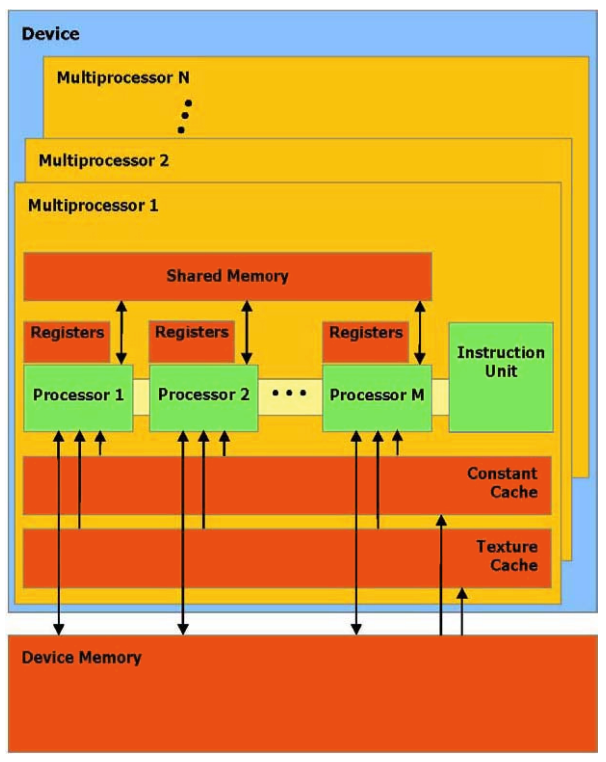
- 典型的
GPU包含一组流处理器 (stream multi-processors,SM),每个流处理器都有许多核心,硬件实现上这些核心之间可共享内存(shared memory)
- 典型的
- 逻辑模型
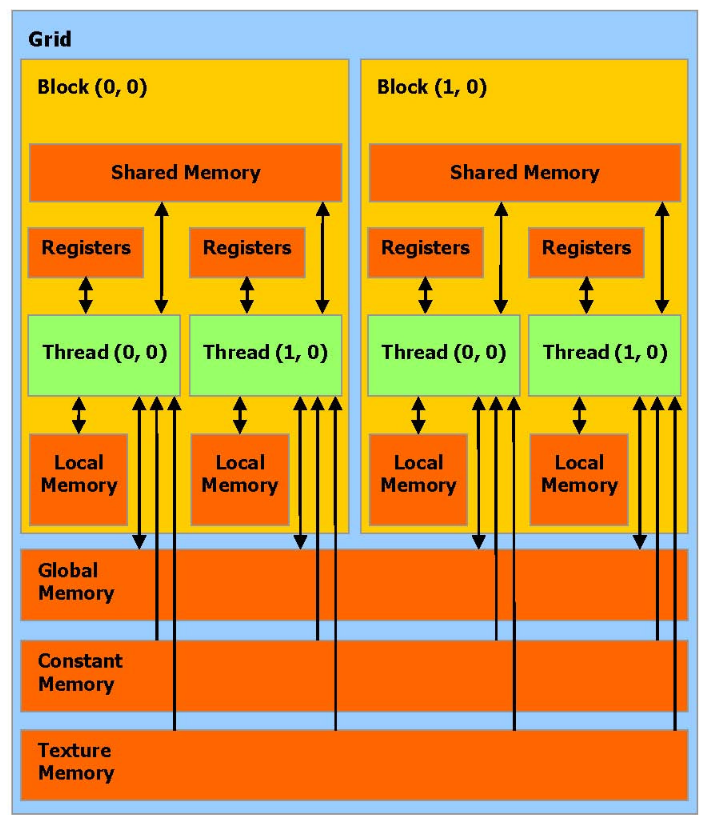
- 逻辑模型中,引入了
Grid/Block/Thread三级概念,逻辑模型与物理的对应关系如下:
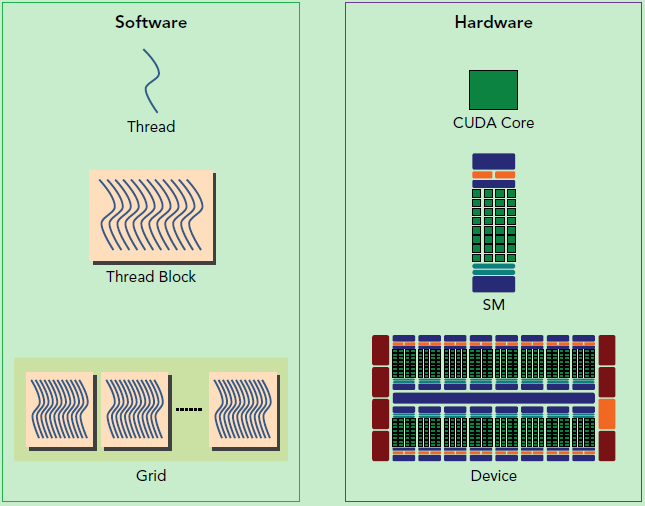
因此:同一个
Block中的Thread可共享shared memory
- 逻辑模型中,引入了
- Memory Hierarchy
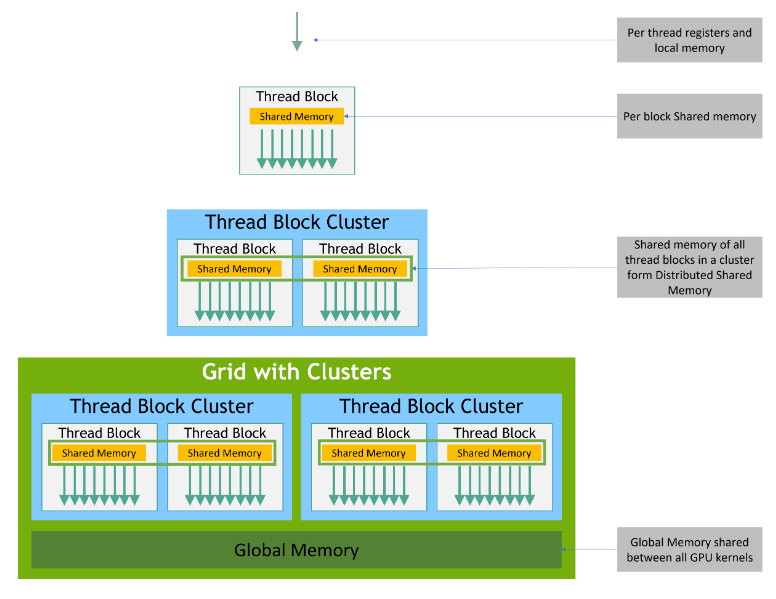
shared memory速度几乎和 L1 cache 一样,比local memory和global memory都快的多(在物理上,local memory和global memory是同一块DRAM) - 在对
GPU进行编程时,需要创建一组进程块 (thread blocks),每个thread映射到单个核心,而block映射到流式多处理器 (SM),如下图所示:
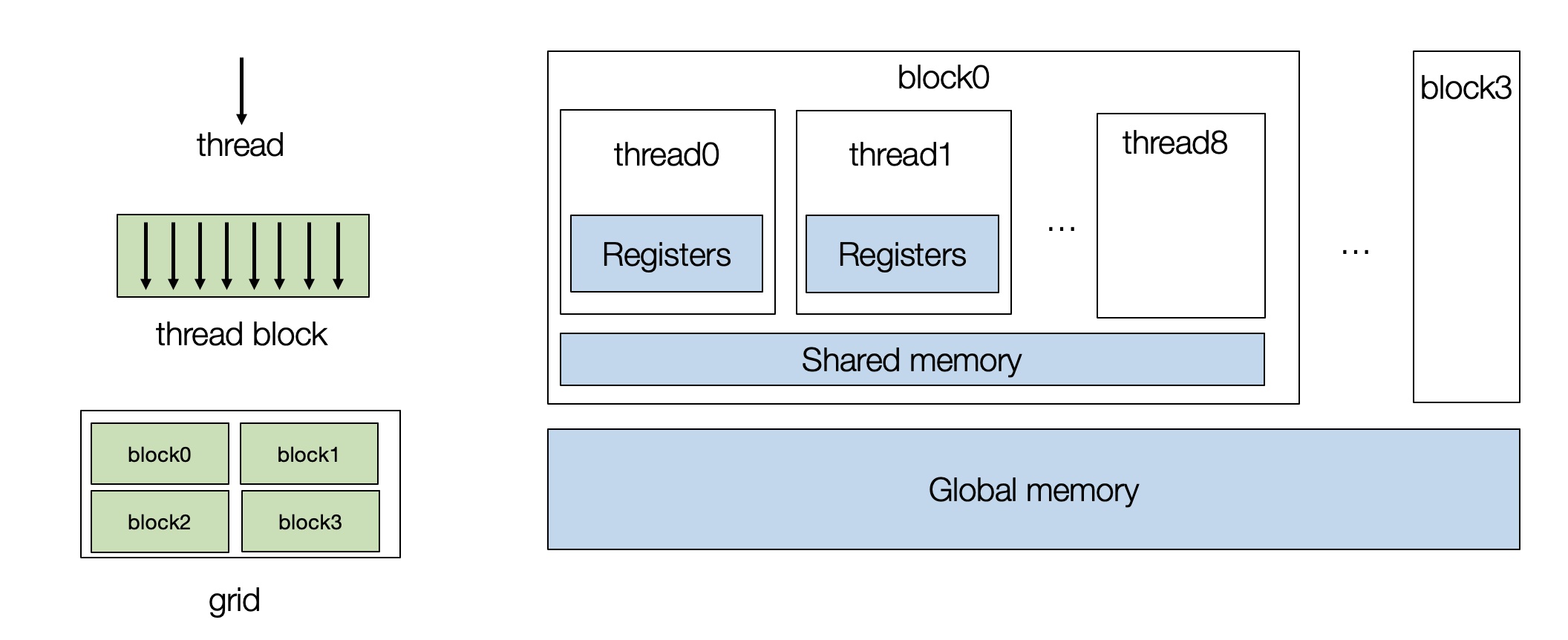
- 每个线程可由
threadIdx和blockIdx索引,在实际应用中,可以有多维线程索引
共享内存优化
- 以矩阵乘为例,
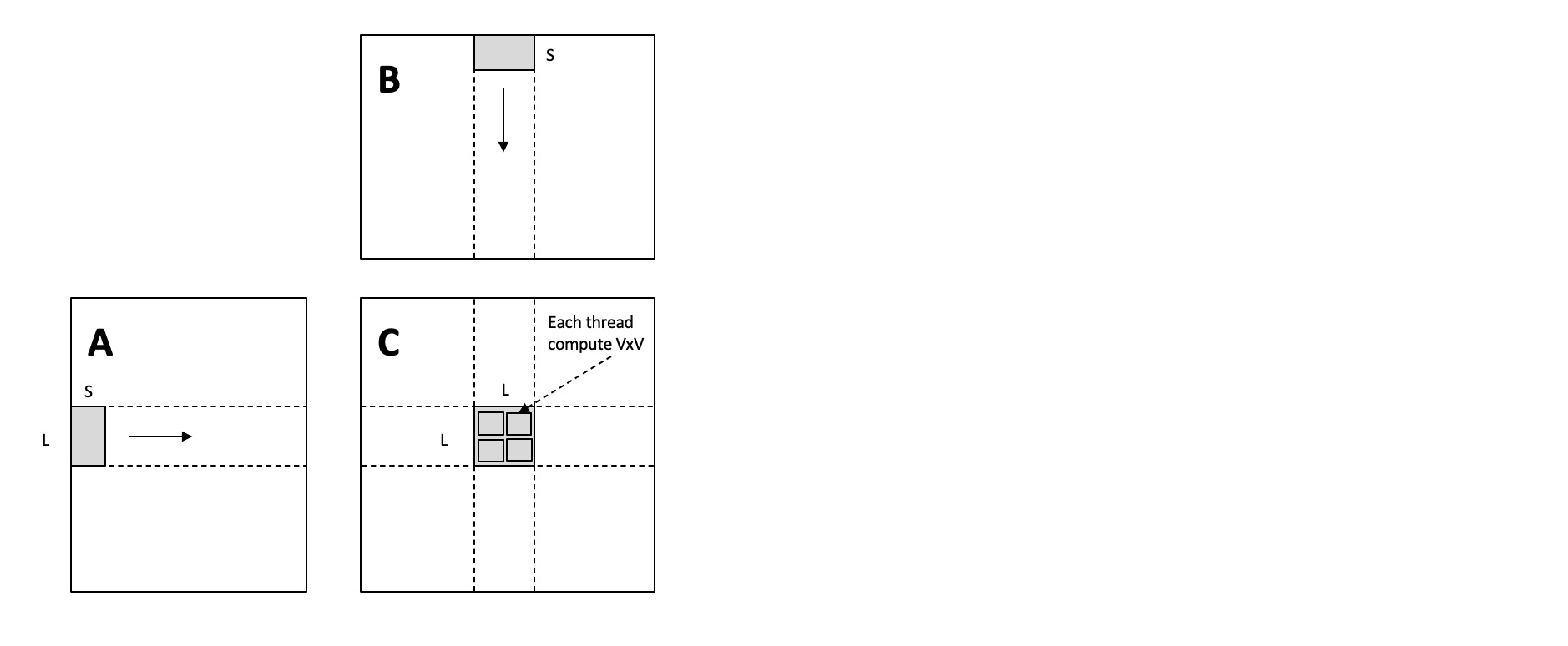
- 同一个
block中的多个thread可共享内存,因此可以重排同一个block中的thread数据,使得尽可能少的数据缓存到shared memory中 - 优化前:
- 每个
thread需要计算输出矩阵中8 * 8的数据,需要从local memory中读取8 * 8 * 1024 * 2数据 - 每个
block中的thread之间没有数据共享,所以需要从local memory中读取 个矩阵元素
- 每个
- 优化后:
- 每个
block计算输出矩阵的64 * 64的数据最少需要 的数据,可提前将这部分数据缓存到shared memory - 然后每个
thread从shared memory读数据计算,需读取 个数据
- 每个
- 内存优化前后每个
block读取数据对比:- 优化前:从
local memory读取 个矩阵元素 - 优化后:从
local memory读取 个矩阵元素到shared memory,再从shared memory读取 个数据计算
- 优化前:从
- 同一个