URL
Algorithm
TL;DR
- 本文提出一种 最大编码率降低(MCR2) 表征算法,本质是一种表征损失函数,本算法有效优化了表征空间,在有监督学习(分类)与自监督学习(聚类)都取得了不错的效果。
Maximal Coding Rate Reduction
- 什么是一个好的表征?一个好的表征应该有哪些性质?
- 一个好的表征应该充分利用表征空间。
- 一个好的表征在同一类下的表征应该尽可能的相似。
- Loss
- 其中:
-
,其中 是表征向量的长度, 是一个
batch的大小,典型值是 。 -
表示行列式的值, 表示行列式的值的自然对数。
-
表示选择函数,选择属于类 的特征向量进行计算。
-
- Loss 解析
- 行列式函数可以用于衡量一个矩阵中向量的正交程度,行列式的值越大,矩阵中向量越正交,向量实际利用的表征空间越大。
- 矩阵的行列式表示由向量 组成的平行四边形的面积,如下图所示,当 向量正交时,面积最大,行列式值最大。
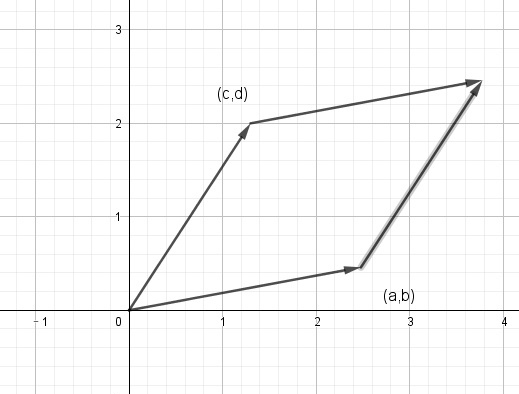
- 同理,在 维空间下,当 个 维空间越正交,组成的 空间积 越大。
- 是个实对称矩阵,因此是半正定矩阵,因此 是个正定矩阵,因此 的行列式的值 > 0,因此
logdet有定义。 - Loss 的实际含义是:所有表征向量尽可能正交,属于同一个类的表征向量尽可能不正交,因此属于同一个类别的表征向量会尽可能共线,不同类别会尽可能正交。
- Loss 中的 都是平衡因子,平衡因向量的长度和统计集大小引起的数值变化。
- 在使用 Cifar10 数据集训练后,将输出的 128 维度表征使用任意分类器(SVM / KNN / 单层神经网络)都很容易进行分类,达到 95+ 的准确率。
- 而且 Loss 在分类任务中的一个优势在于:对于存在错误标签的数据, 比交叉熵对错误标签的敏感度更低,如下图所示:

- 面对聚类任务,由于没有类别信息,损失函数变成: ,即:尽可能充分利用表征空间 。
Throught
- 本文提出的方法从表征角度讲非常 make sense,但存在的问题是:依然无法摆脱 维度灾难,因此 也仅仅被用于低维度表征空间中,无法在神经网络的每一层都使用,在分类任务中也仅仅可以被当做一个在交叉熵的升级版本(交叉熵作用于类别维度, 监督维度更高)。
- 一个简单的想法确实可以有效提高聚类任务的模型效果,所以为后面的 Deep (Convolution) Networks from First Principles 提供了理论基础。