Topic
- 本文汇总多种 语义分割算法
decode head结构和 部分分割专用backbone,用于理解语义分割算法的演进过程 decode head模型来源:mmsegmentaion decode head- 本文的语义分割
decode head是指满足如下要求的网络结构:- 输入为
backbone / neck提取的feature map或feature map list - 输出为
segmentation结果
- 输入为
语义分割推理过程
1. 原始特征处理
- 输入的原始特征包括两类:
backbone输出的feature map(例如PSPNet输出)backbone不同阶段 /neck(例如FPN) 输出的不同尺度的feature map list
- 对于
feature map,可以resize到输出大小再送入decode head,也可以直接送入decode head,根据具体算法选择 - 对于
feature map list,一般有两种做法,根据具体算法选择:resize concat: 将所有feature map全部resize到输出大小后再concat(例如FCN-8s)multiple select: 根据index在feature map list中索引并输出对应的feature map sub list
2. 特征解码
- 将 1 中输出的
feature map / feature map list转化成与输出 宽高一致 的feature map,也是本文具体展开讲的内容
3. 特征映射到分割任务空间
- 将 2 中输出的特征映射到分割空间,具体通道数与任务定义相关(例如:二分类的语义分割输出通道为
1或2,N分类的语义分割输出通道数为N)
演进过程
第一代:在 CNN 结构上创新
FCN: 2014年,出自UC Berkeley,分割算法起点PSP: 2016年,出自商汤,FCN+ 多尺度ASPP: 2017年,出自Google,PSP的优雅实现版(DeepLab V2、DeepLab V3)FPN: 2018年,出自FAIR,UNet多尺度的升级版UperNet: 2018年,出自旷视,PSP+FPN更暴力的多尺度DepthwiseSeparableASPP: 2018年,出自Google,DeepLab V3结构的小改动(DeepLab V3+)DepthwiseSeparableFCN: 2019年,出自东芝 + 剑桥,FCN的轻量化改造(Fast-SCNN)PointRend: 2019年,出自FAIR,在其他decode head基础上级联了一个subnetwork实现了图像分割边缘的细化
第二代:Self-Attention (Non-local / Channel Attention)
Non-Local: 2017年,出自FAIR,Self Attention经典PSANet: 2018年,出自商汤,Non-local的二维狗尾续貂版CCNet: 2018年,出自地平线,Non-local的低算力版,使用两个低算力的Attention替代Non-local AttentionDANet: 2018年,出自京东,两路Non-local,一路attention to postion一路attention to channelEncNet: 2018年,出自商汤 +Amazon,优化了SENet中的暴力编码方式,在分割任务中额外加入了分类辅助监督EMANet: 2019年,出自北大,attention to channel和attention to postion可分离的attentionANN: 2019年,出自华中科技大学,简化Non-local同时引入PPM,极大的降低了matmul和softmax两类算子的耗时GCNet: 2019年,出自MSRA,简化版Non-local+SENet的缝合怪OCRNet: 2019年,出自MSRA,级联结构,在其他decode head的输出结果上做了Self-Attention,并在论文中从Transformer角度解释了Self-Attention(Transformer 开始觉醒)APCNet: 2019年,出自商汤,复杂网络结构 + 简化矩阵乘实现的AttentionDMNet: 2019年,出自商汤,根据输入特征的全局信息动态生成卷积核,本质也是AttentionLRASPP: 2019年,出自Google,全局scale实现的Attention(MobileNet V3)ISANet: 2019年,出自MSAR,使用feature map shuffle实现长范围和短范围的稀疏注意力机制DNLNet: 2020年,出自MSAR,改进Non-local,加入了归一化和一元分支BiSeNet: 2019年,出自旷视,在backbone之外加入了一个context branch,将特征提取和attention解耦,降低了attention恐怖的计算量BiSeNet V2: 2020年,出自腾讯,BiSeNet的改进SDTC: 2021年,出自美团,BiSeNet系列的改进版,但由于融合了两路分支到一处,不再Bilateral,所以用特征提取SDTC block命名…
第三代:Transformer
SETR: 2020年,出自腾讯,Vit做backbone+FCN / FPN decode headDPT: 2021年,出自Intel,SETR的升级版,backbone不变,decode head更FPN了一些Segmenter: 2021年,出自法国INRIA研究所,用了纯Transformer架构而不是像SETR / DPT一样用Transformer Encoder + CNN Decoder架构SegFormer: 2021年,出自NVIDIA,SETR的高效版KNet: 2021年,出自商汤,decode head融合了Channel Attention + Multi-head Attention + RNN,统一了语义分割、实例分割、全景分割框架
Algorithms
1. FCN
FCN全称是Fully Convolutional Networks- paper: https://arxiv.org/pdf/1411.4038.pdf
- code: https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/fcn_head.py
1.1 原始特征处理
- 原始特征处理使用了
resize concat方式,将多个不同尺度(backbone不同阶段)的feature map resize concat到输出尺寸,如下图所示:
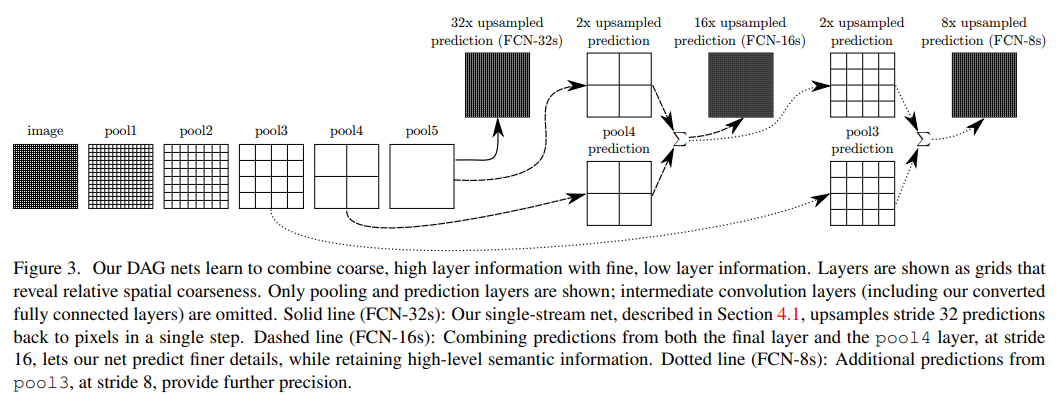
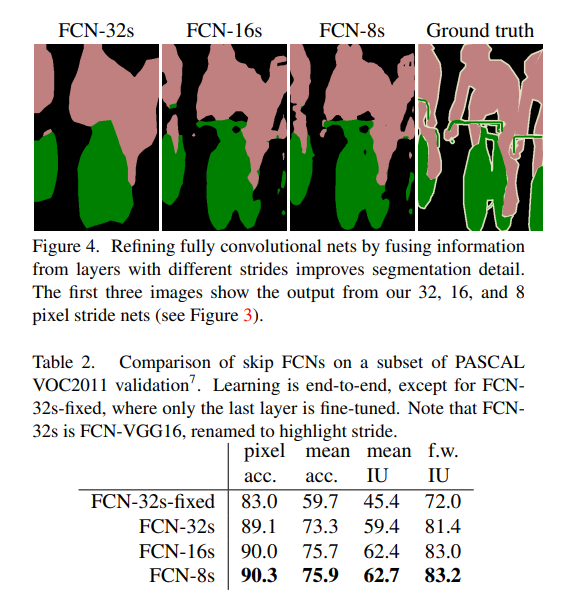
实验证明越多尺度融合分割效果越好
1.2 特征解码
- 特征解码只使用了几层普通
Conv+ 可选择的concat input(shortcut)结构
2. PSP
PSP全称是Pyramid Scene Parsing(金字塔场景理解)- paper: https://arxiv.org/pdf/1612.01105.pdf
- code: https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/psp_head.py
2.1 原始特征处理
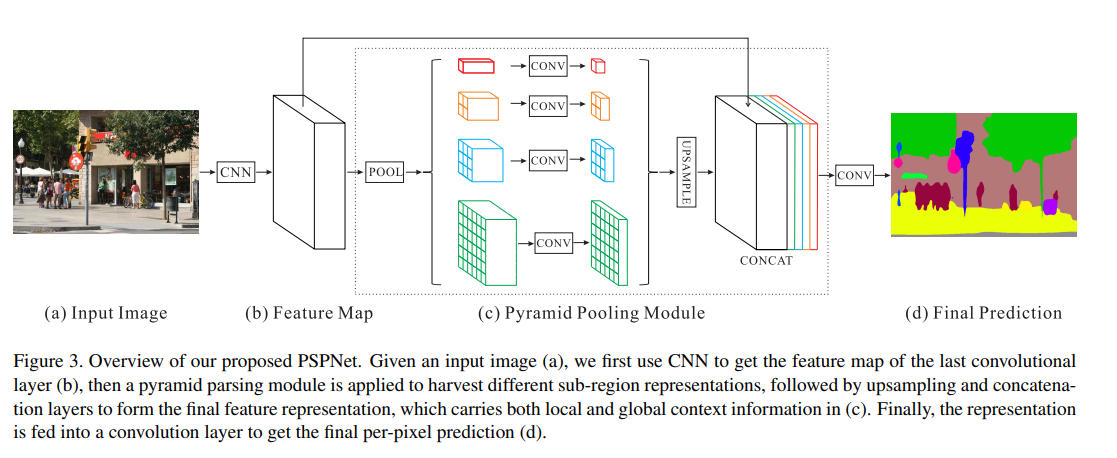
PSPNet的原始特征是backbone最后一层的输出,所以无需原始特征处理
2.2 特征解码
PSPNet将输入特征通过Pyramid Pooling Module结构做了feature map不同尺度down sample+up sample,如下图所示:
3. ASPP
- ASPP 全称是
Atrous Spatial Pyramid Pooling(空洞空间金字塔池化) - paper: https://arxiv.org/pdf/1706.05587.pdf (大名鼎鼎的
DeepLab V3) - code: https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/aspp_head.py
3.1 原始特征处理
DeepLabV3输入为单个单尺度feature map,所以此步骤可省略
3.2 特征解码
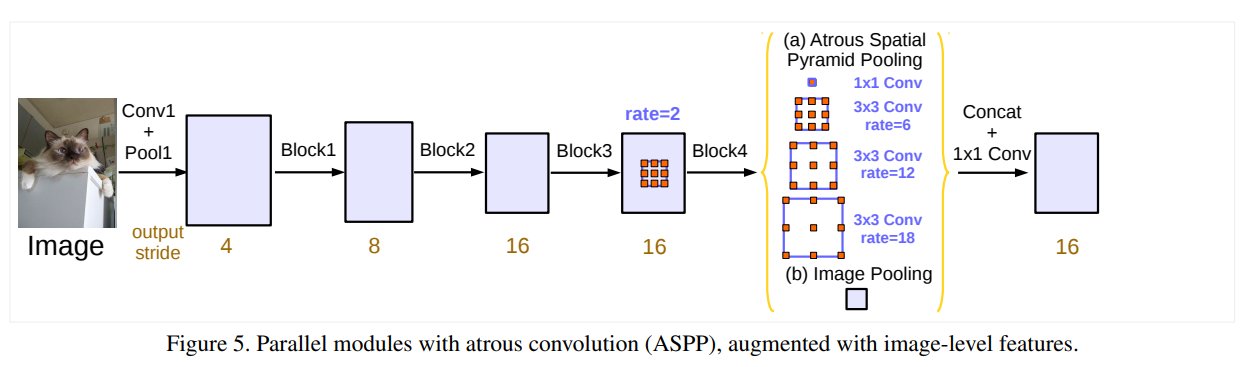
与
PSPNet很像,PSPNet是使用普通Conv去卷积多种尺度的Pooled feature map;ASPP是不改变feature map而是使用 不同空洞系数的Conv
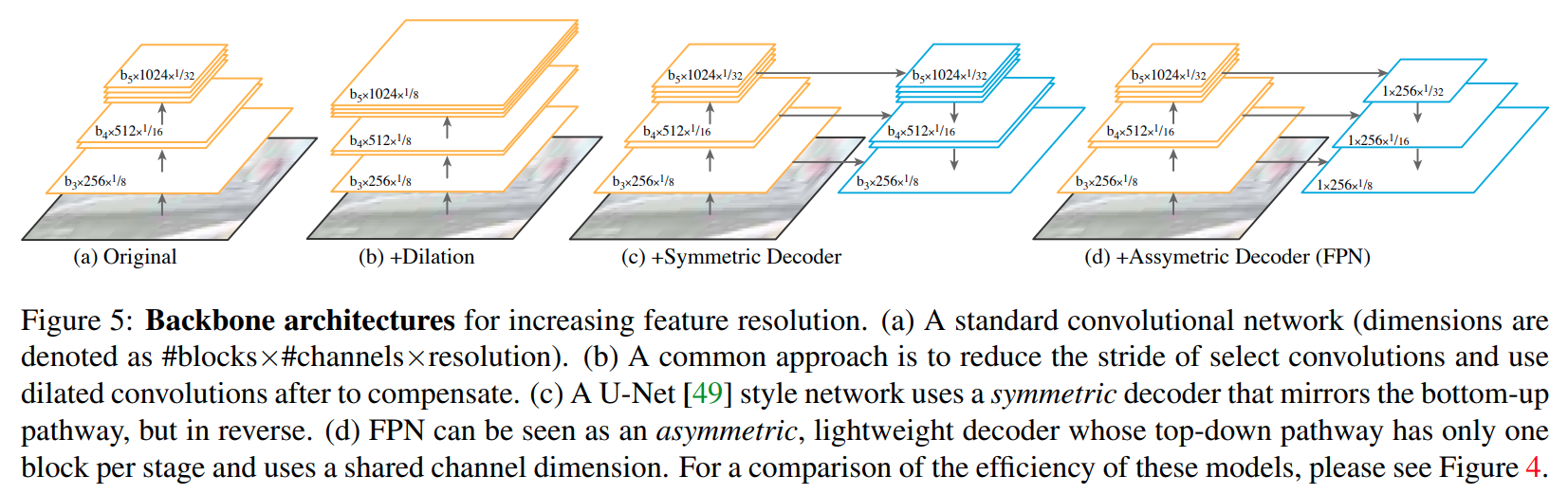
4. FPN
FPN全称是Feature Pyramid Network,出自 kaiming 大神,可以用在所有和feature map scale大小相关的领域- paper: https://arxiv.org/pdf/1901.02446.pdf
- code: https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/fpn_head.py
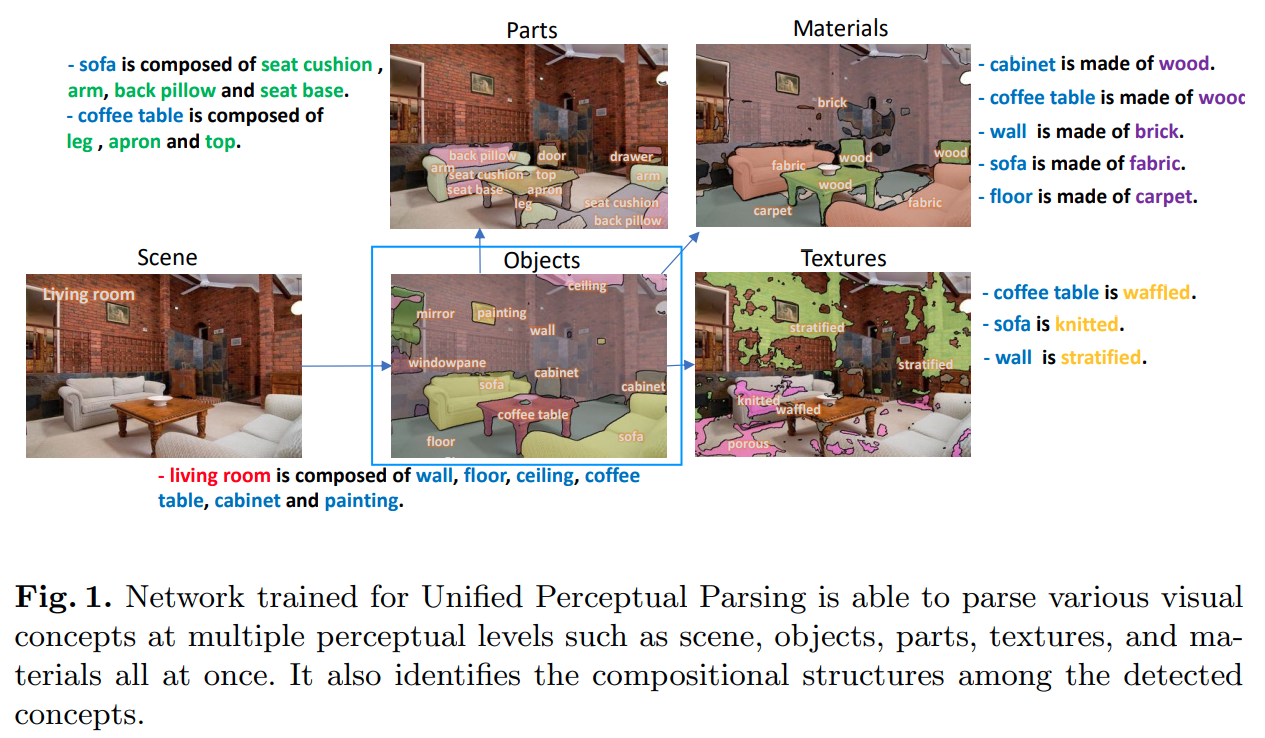
5. UperNet
UperNet的全称是Unified Perceptual Parsing Network(统一感知解析网络),本身是多任务模型:- 场景分类
objects语义分割parts语义分割materials语义分割textures语义分割
本文只讨论其中的objects语义分割部分
- paper: https://arxiv.org/pdf/1807.10221.pdf
- https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/uper_head.py
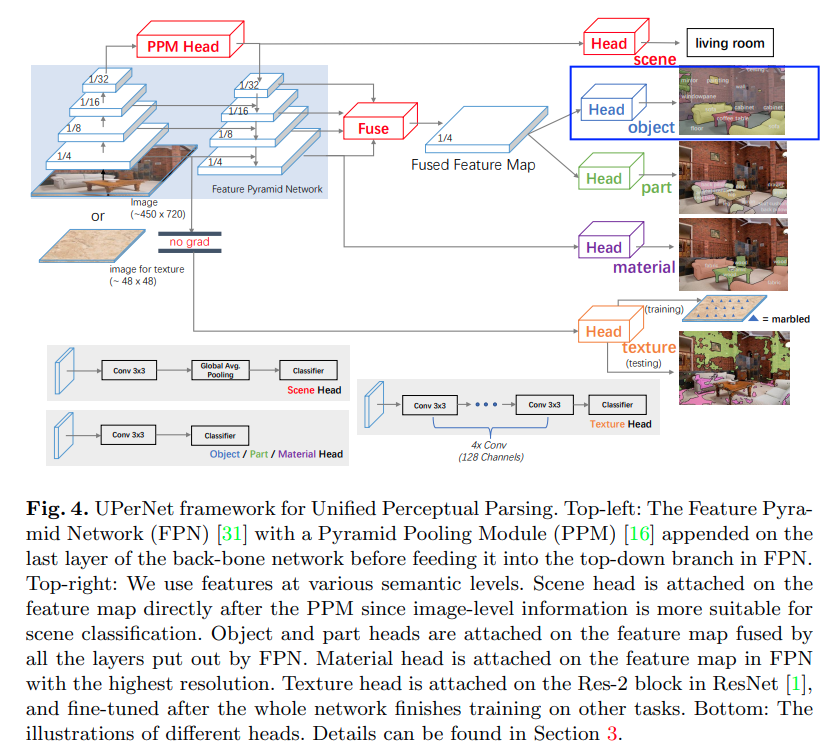
5.1 原始特征处理
- 本算法在
decode head中内嵌使用FPN(而不是以网络neck方式使用),所以feature map list格式的原始特征无需处理,直接透传到特征解码部分
5.2 特征解码
本文只讨论图中蓝色框部分
只需要看蓝色框为输出的通路,算法:
- 在最小尺度
feature map上使用PPM(全称Pyramid Pooling Module,来自于PSPNet)- 使用
FPN融合多尺度特征
6. DepthwiseSeparableASPP
- 在
DeepLab V3引入的ASPP基础上增加了两点改进:- 使用
DepthwiseSeparable ASPP替代ASPP,减小计算量 - 增加了一个
vanilla FPN结构,避免了DeepLab V3直接上采样 8 倍预测的问题
- 使用
- paper: https://arxiv.org/pdf/1802.02611.pdf (大名鼎鼎的
DeepLab V3+) - code: https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/sep_aspp_head.py
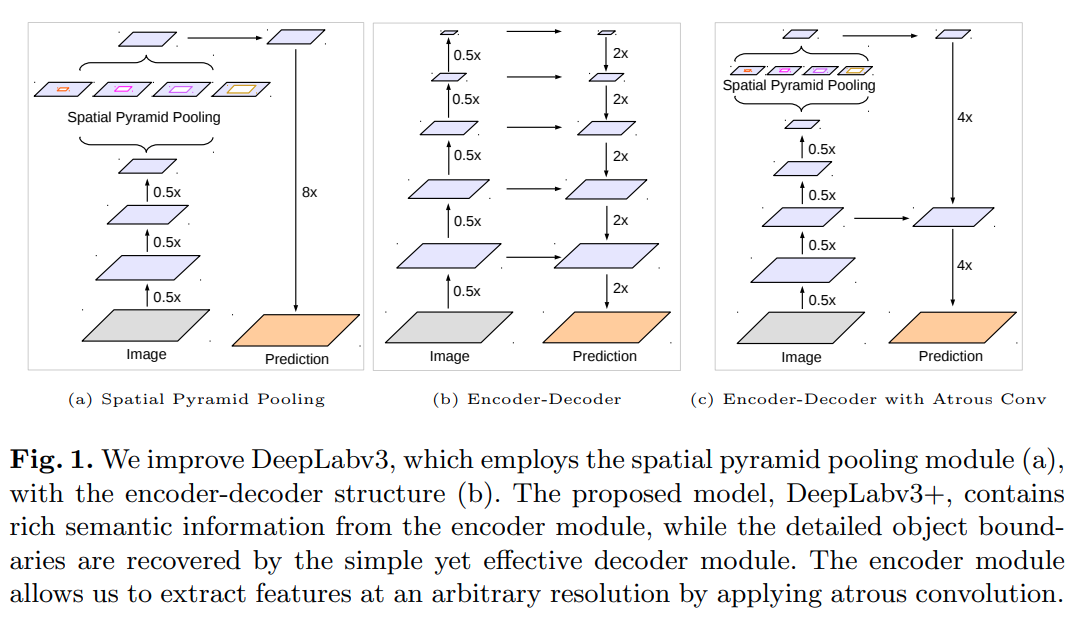
相较于
DeepLab V3在 8 倍下采样的feature map上使用 ASPP,DeepLab V3+在更小尺度(16 倍下采样)feature map上使用DepthwiseSeparable ASPP
同时为了解决小尺度预测的问题,加入了一个vanilla FPN做不同尺度特征融合
7. DepthwiseSeparableFCN
FCN的轻量化实现,使用DWConv(Depthwise Conv) 和DSConv(Depthwise Separable Conv) 替换FCN中的普通Conv- paper: https://arxiv.org/pdf/1902.04502.pdf (
Fast-SCNN) - code: https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/sep_fcn_head.py
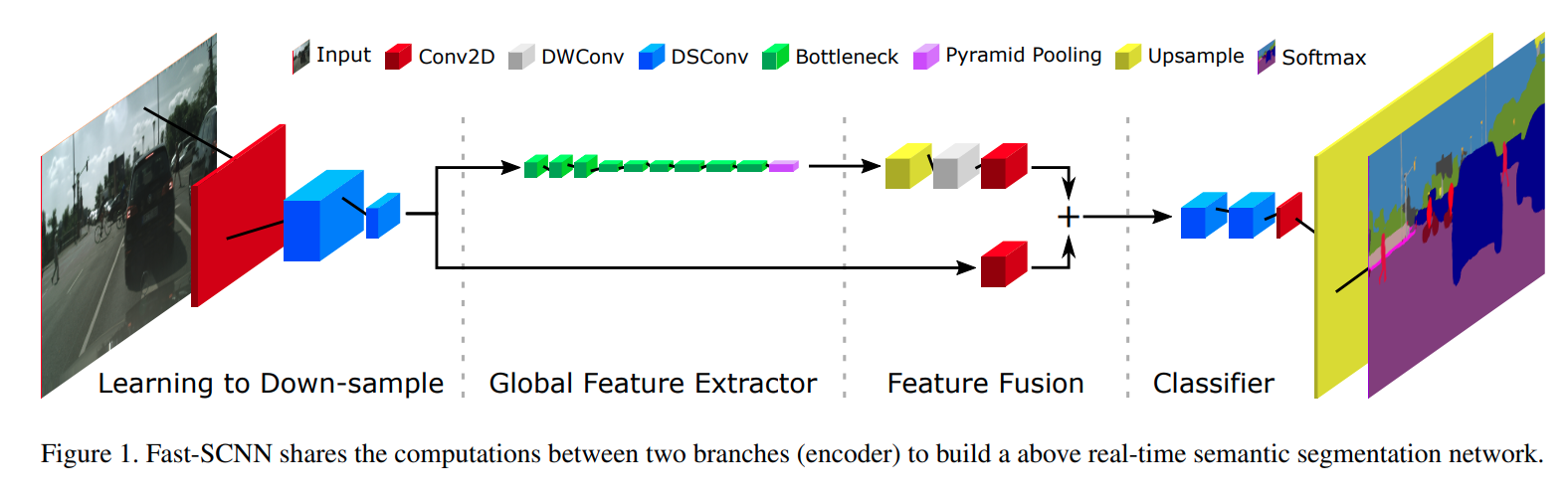
图中的
DWConv是指Depthwise Conv(ic == oc == group)
图中的DSConv是指Depthwise Separable Conv,DSConv不是一个Conv而是Depthwise Conv和Pointwise Conv(kernel_size == 1 and group == 1) 以及激活函数 /BN一起组成的一个block
8. PointRend
PointRend全称是point-base rendering(基于点的渲染算法),是一个级联分割算法,实例分割和语义分割都可使用,依赖于一个其他完整的decode head(例如FCN)的输出,该算法提出了一个subnetwork,该结构只关心目标边界点的分割,可预测更准确更sharp的目标边界- paper: https://arxiv.org/pdf/1912.08193.pdf
- code: https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/point_head.py

- 渲染:渲染(
render)是指在电脑中使用三维制作软件将制作的模型经过纹理、绑定、动画、灯光处理后得到模型和动画的图像。三维渲染是使用计算机从数字三维场景中生成二维影像的过程- 细分表面算法:细分表面算法(
subdivision surface algorithm)在3D计算机图形中使用,通过递归完善基本级多边形网格来创建弯曲表面

- 本文的核心思想:
- 将计算机图形学中的
Subdivision render思想用于分割,使用coarse-to-fine思想,逐级细分,提高分割效果 - 使用非均匀采样方法,越高频的区域使用越多的采样点,提高边缘分割效果
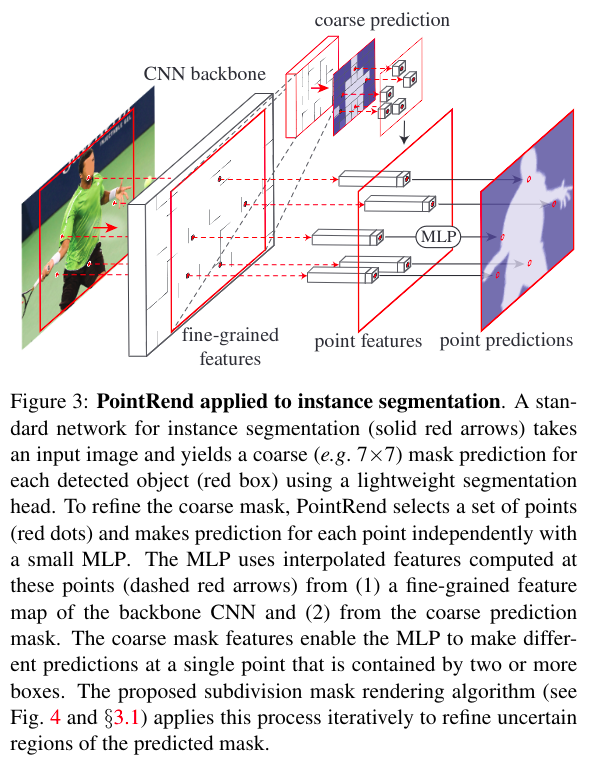
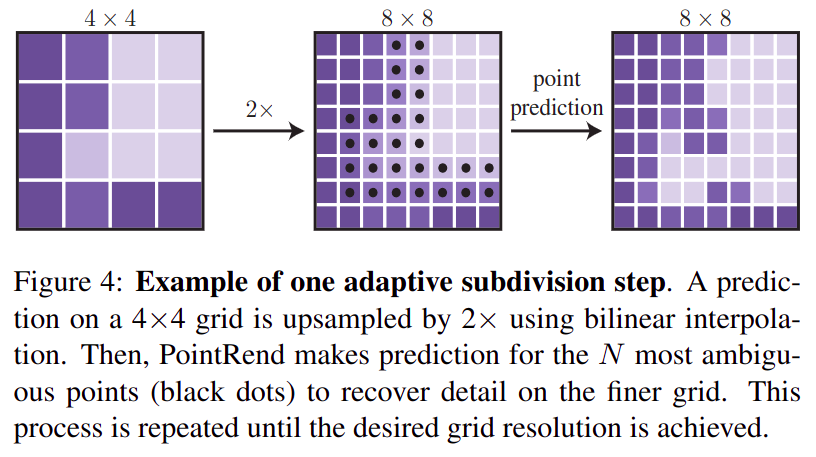
- 将计算机图形学中的
Inference过程(以FCN作为prev_decode_head为例):- 输入:
backbone的输出x,shape = [batch, channels, height, width]FCN的输出prev_output,shape = [batch, num_cls, height, width]
- 输出:
refine后的输出,shape = [batch, num_cls, 2 * subdivision_steps * height, 2 * subdivision_steps * width]
prev_output copy一份作为refined_seg_logitsrefined_seg_logits插值放大两倍,shape = [batch, num_cls, 2 * height, 2 * width]- 在
refined_seg_logits上挑选最hard的N个点(hard的定义是:如果一个像素的top1_cls_logitis和top2_cls_logits越接近,则该点越hard),输出相对坐标,shape = [batch, N, 2] - 根据选出的
N个点的坐标在x中找到对应的点(需要插值找出),作为fine_grained_point_feats,shape = [batch, channels, N] - 根据选出的
N个点的坐标在prev_output中找到对应的点(需要插值找出),作为coarse_point_feats,shape = [batch, num_cls, N] fine_grained_point_feats和coarse_point_featsconcat后经过Subnetwork(几层MLP)映射到类别空间point_logits,shape = [batch, num_cls, N]- 根据
3中的point index,将6输出的point_logits替换到1中的refined_seg_logits对应位置 - 重复
2 ~ 7 subdivision_steps次,输出最终的refined_seg_logits,shape = [batch, num_cls, 2 * subdivision_steps * height, 2 * subdivision_steps * width]
- 输入:
Train过程:- 输入:
backbone的输出x,shape = [batch, channels, height, width]FCN的输出prev_output,shape = [batch, num_cls, height, width]gt_semantic_seg,shape = [batch, num_cls, height, width]
- 输出:
loss Train过程与Inference过程基本相同,区别在于:- 由于
topk运算对梯度反向传播不友好,所以在Train的过程中使用随机采样点的策略,没有挖掘hard case Train不会引入多尺度,只会在同一尺度学习subnetwork对point的分类
- 由于
- 输入:
9. Non-Local
- 出自 kaiming 大神,原论文是做三维特征理解(视频理解),二维化后用在分割上也很强
- paper: https://arxiv.org/pdf/1711.07971.pdf
- code: https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/nl_head.py
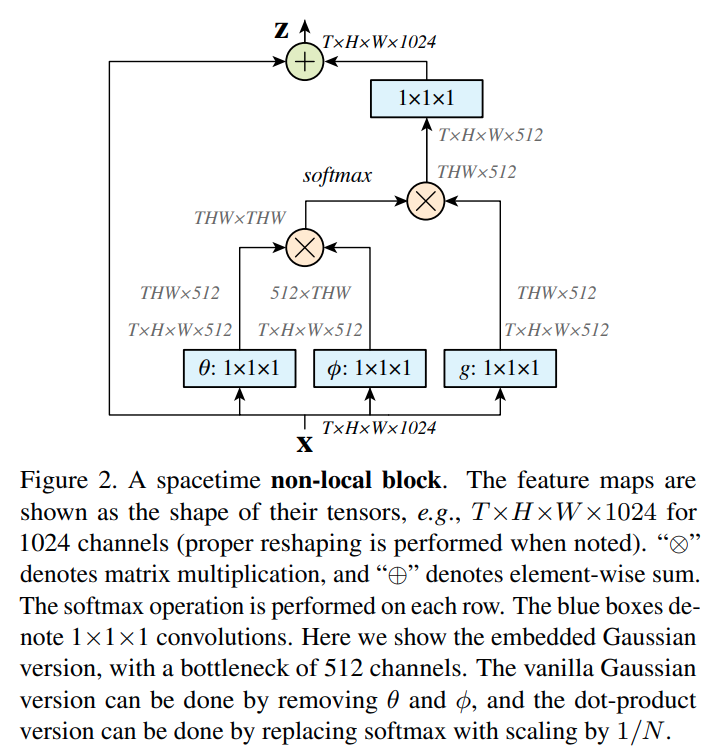
用于
2维图像,所以T == 1,通过增加(HW, HW)的特征相关性矩阵给特征带来全局相关性(Attention)
decode head前后处理和FCN一致
10. PSANet
PSA的全称是Point-wise Spatial Attention- paper: https://hszhao.github.io/papers/eccv18_psanet.pdf
- code: https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/psa_head.py
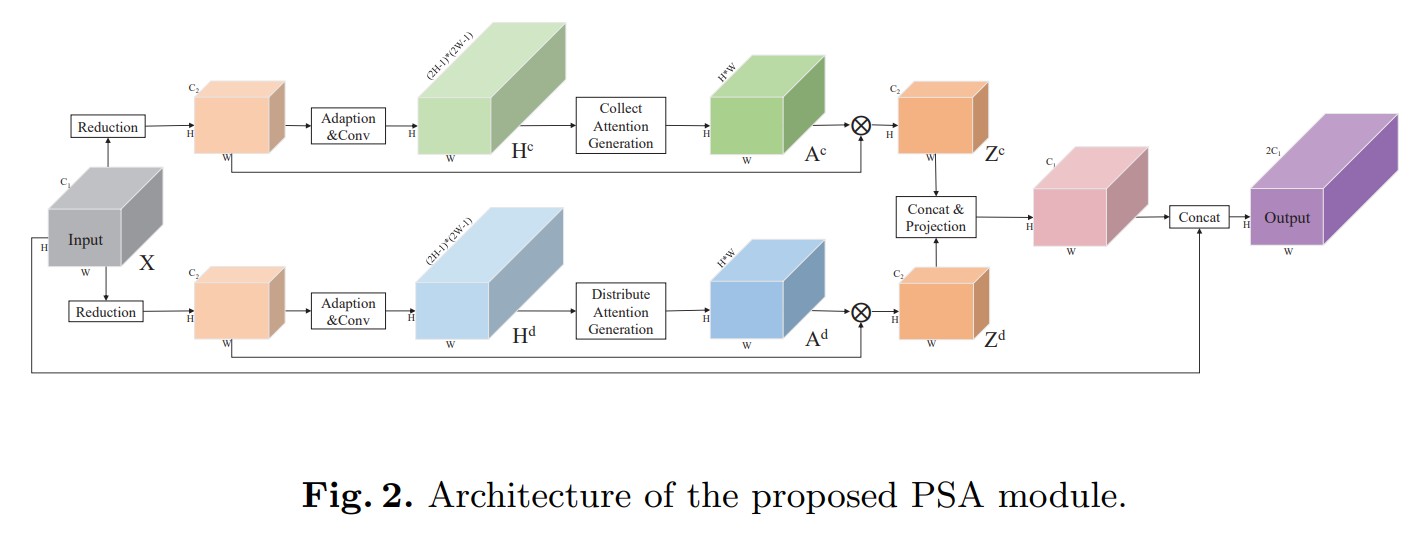
借鉴于
Non-local,强行给了比较牵强的数学解释,推理过程复杂到需要调用CUDA而不是使用pure pytorch
11. CCNet
CC的全称是Criss-Cross Attention(十字交叉注意力机制)- paper: https://arxiv.org/pdf/1811.11721.pdf
- code: https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/cc_head.py
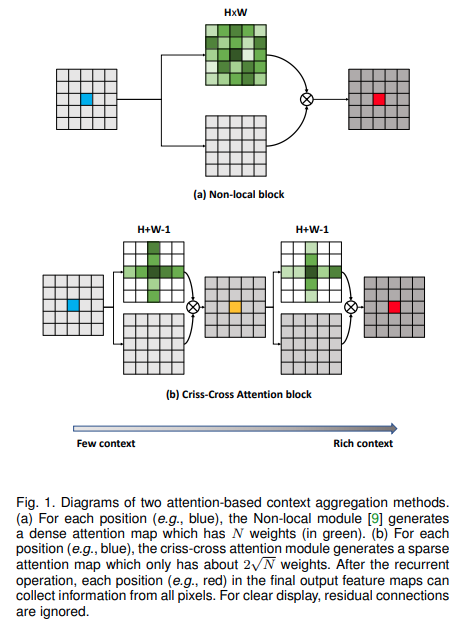
使用两个十字交叉注意力模块的串联替代
Non-local,降低算力
整体流程平平无奇
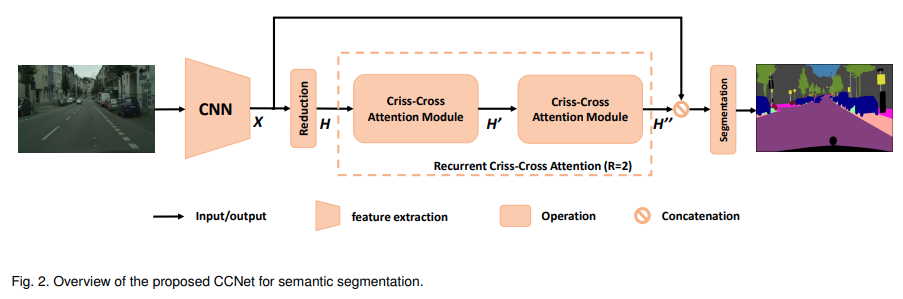
decode head前后处理和FCN一致
12. DANet
DANet全称是Dual Attention Network(双路Attention网络)- 一路在空间维度
Attention,照搬Non-local - 一路在通道维度
Attention,通道维度Non-local
- 一路在空间维度
- paper: https://arxiv.org/pdf/1809.02983.pdf
- code: https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/da_head.py
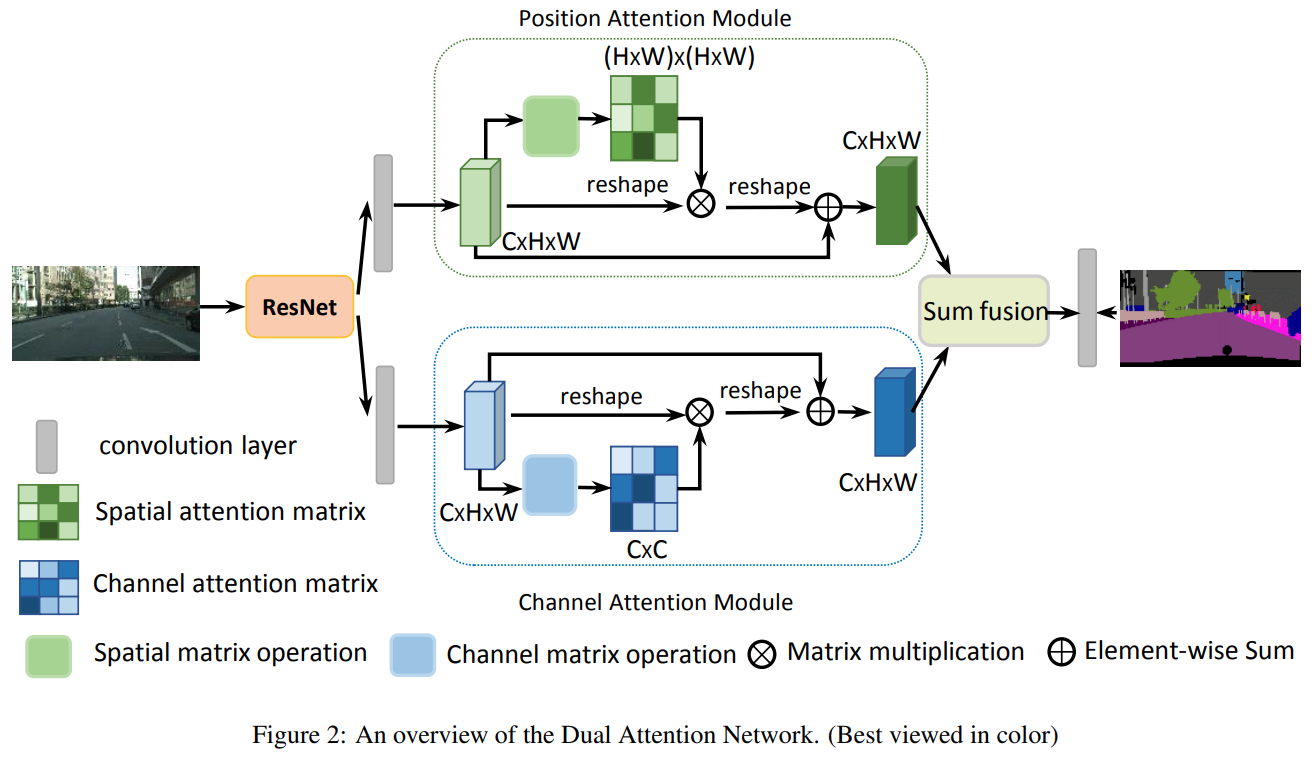
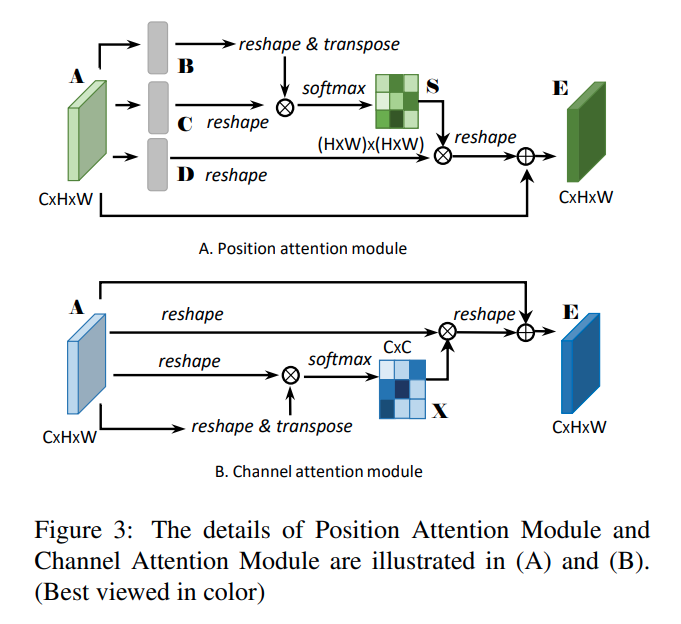
13. EncNet
EncNet的全称是Context Encoding Network(上下文编码网络),做法是对网络中间层feature map编码到分类空间,加入了分类Loss监督- paper: https://arxiv.org/pdf/1803.08904.pdf
- code: https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/enc_head.py
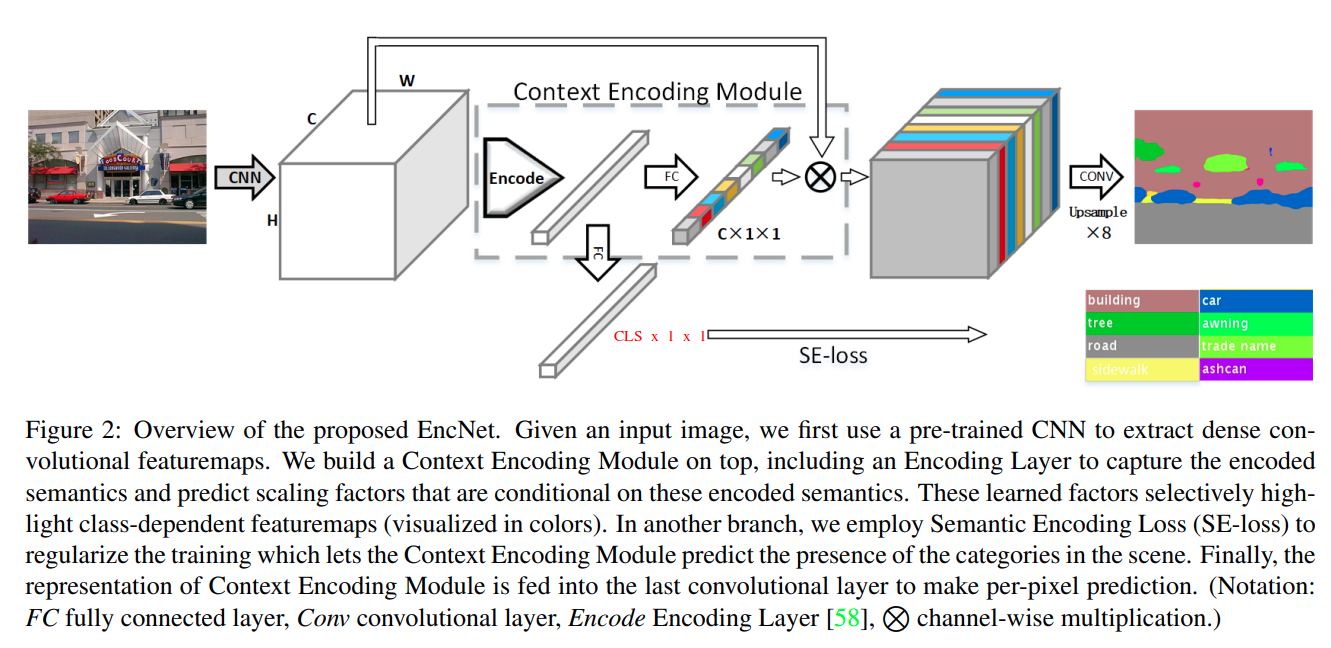
对于
SE-loss: 监督图中包含哪些类别的像素,使用交叉熵实现
对于Encode:
- 从本质上看:
- 上图使用的
Encode和SENet(Squeeze and Excitation Network) 对feature map per channel编码没有区别- 从实现层面看:
Encode使用了更在数学上更好解释的编码方式(而不是SENet粗暴的Global Average Pooling编码方式)Encode编码空间比SENet更大(SENet 每个通道使用 空间编码,Encode每个通道使用 空间编码)
14. EMANet
EMA的全称是Expectation-Maximization Attention(最大期望注意力),从数学角度解释了Attention,实现上也是通过多个矩阵乘实现的channel与position分离的Attention- paper: https://arxiv.org/pdf/1907.13426.pdf
- code: https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/ema_head.py
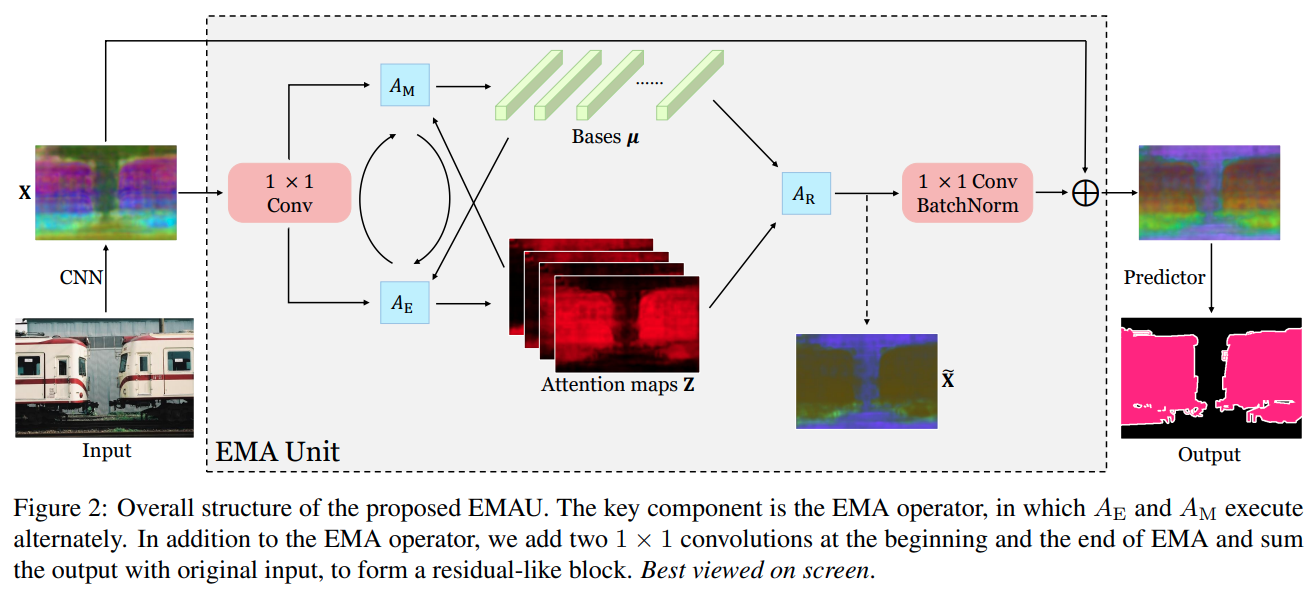
15. ANN
ANN全称是Asymmetric Non-local(非对称Non-local), 简化Non-local同时引入PPM,极大的降低了matmul和softmax两类算子的耗时- paper: https://arxiv.org/pdf/1908.07678.pdf
- code: https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/ann_head.py
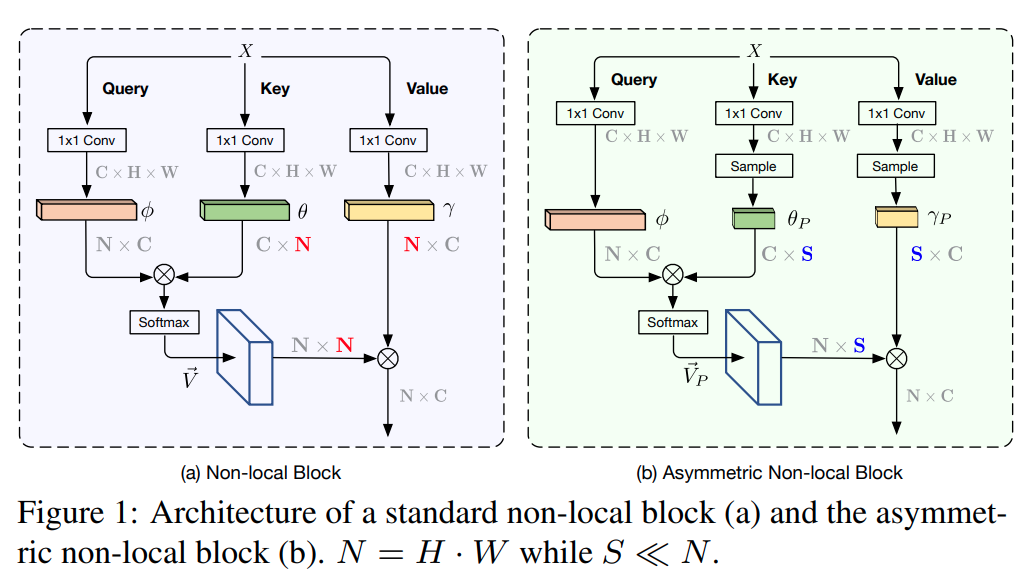
在
key/value上对特征进行了降维N -> S,由下图可知,上图的sample方法具体是指PPM(Pyramid Pooling Module)
AFNB全称是Asymmetric Fusion Non-local Block
APNB全称是Asymmetric Pyramid Non-local Block
二者对Non-local的Self-Attention进行简化,例如share key value
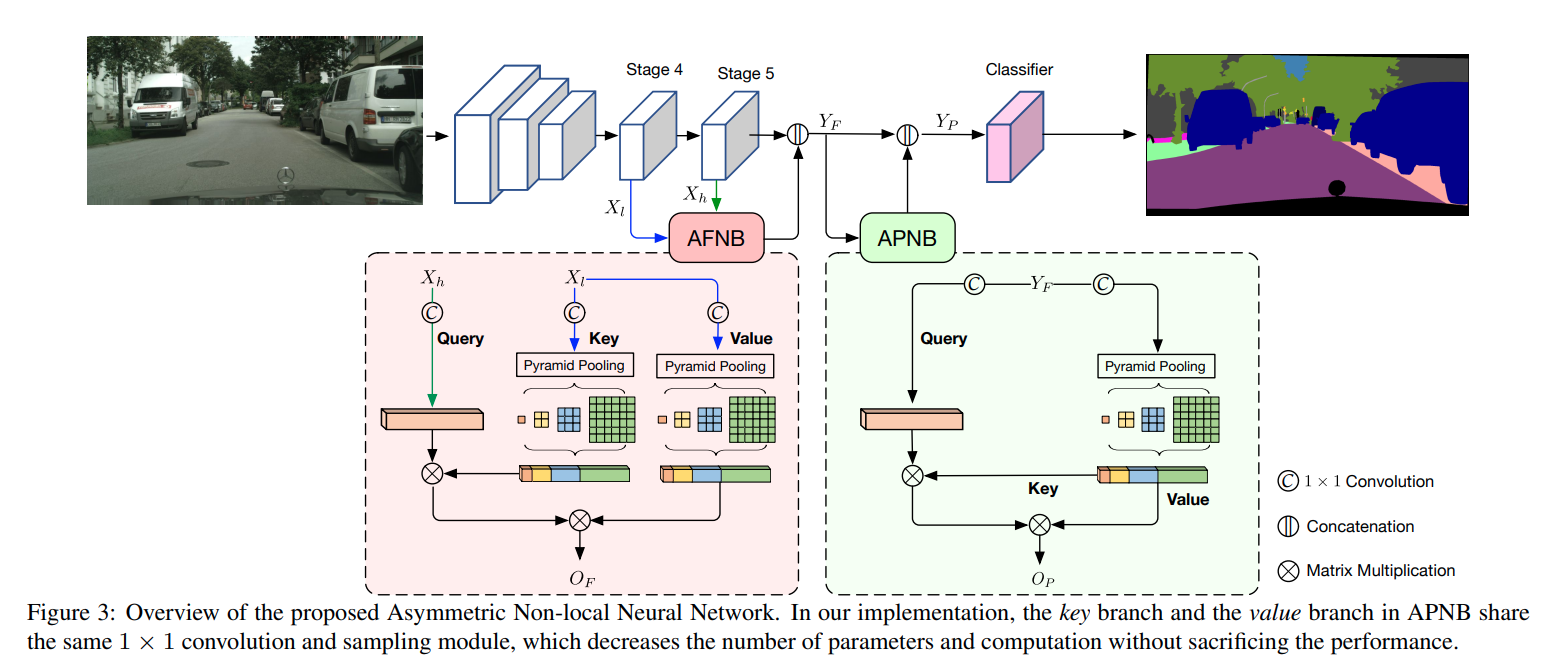
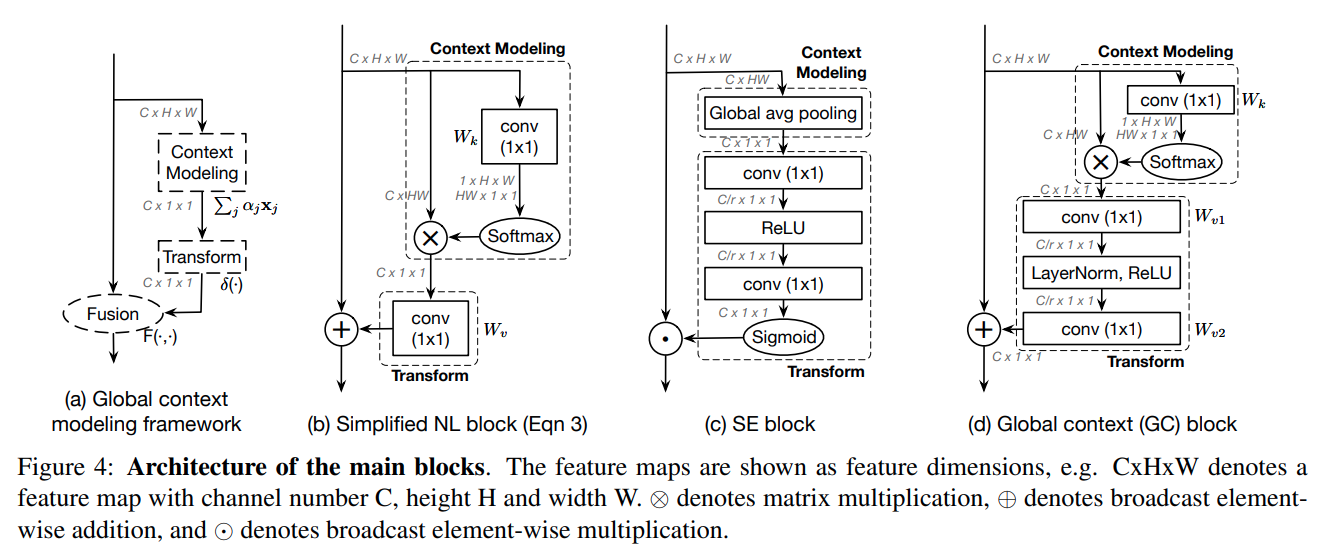
16. GCNet
GCNet的全称是Global Context Network,作者认为Non-local对全局信息把握的不够好,本文是简化版Non-local+SENet的缝合怪,Non-local的Spatial Attention和SENet的Channel Attention结合- paper: https://arxiv.org/pdf/1904.11492.pdf
- code: https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/gc_head.py
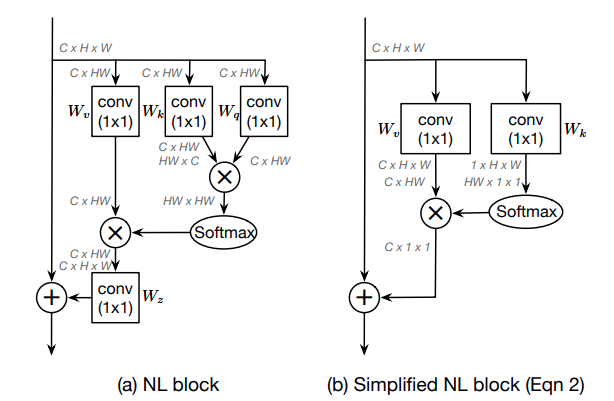
Non-local结构的化简
作者认为一个全局上下文建模结构如图 (a) 所示
图 (b) 为简化后的Non-local结构
图 © 是SENet结构
图 (d) 是本文提出的GC结构
decode head前后处理和FCN一致
17. OCRNet
- paper: https://arxiv.org/pdf/1909.11065.pdf
- code: https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/ocr_head.py
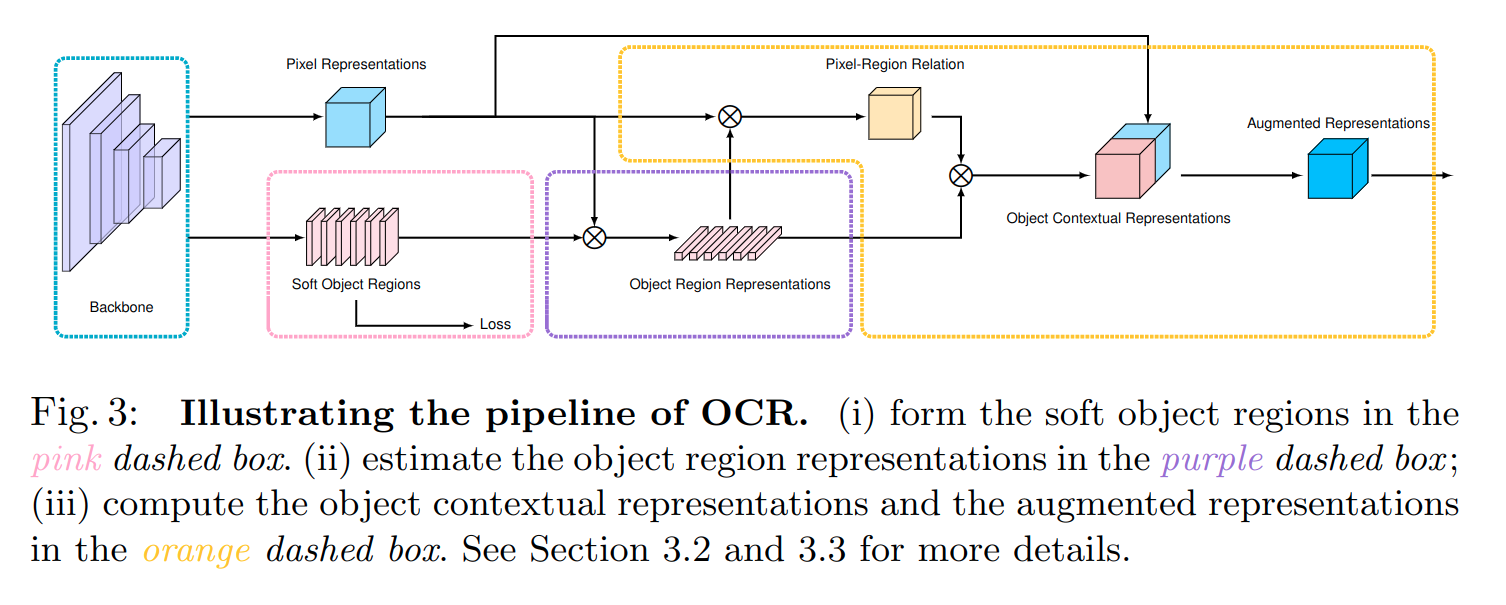
OCR的全称是Object Contextual Representations(目标上下文表征)而不是,和前面的模型结构不同,Optical Character Recognition(光学字符识别)OCRNet是一种Cascade Encoder Decoder结构的decode head,该算法依赖于其他算法输出的分割结果,如下图所示(OCRNet依赖于FCN的输出):
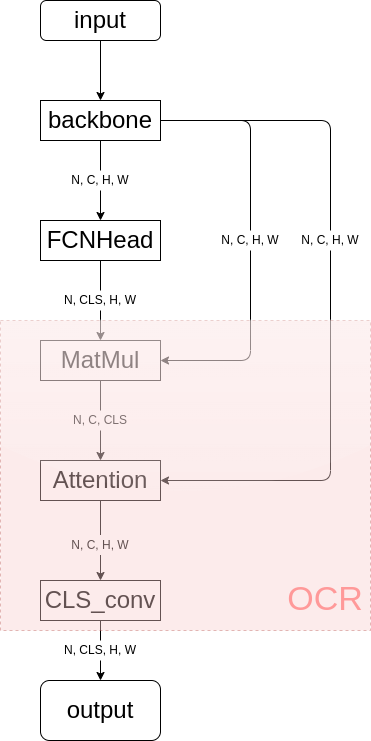
上图中粉红色的部分即为
OCRNet decode head
论文中给出的算法架构图,给中间结果赋予了可解释的含义
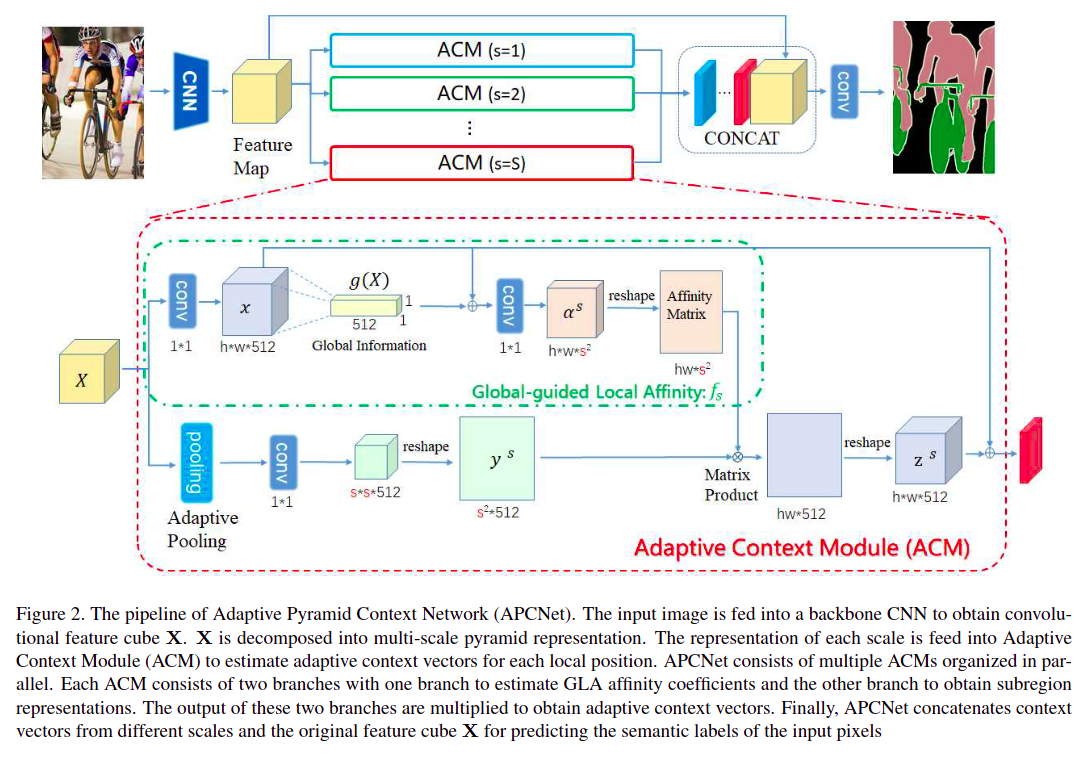
18. APCNet
APCNet的全称是Adaptive Pyramid Context Network(自适应金字塔上下文),该算法引入了Adaptive Context Modules(ACM)(自适应上下文模块),本质就是通过矩阵乘实现全局Attention- paper: https://openaccess.thecvf.com/content_CVPR_2019/papers/He_Adaptive_Pyramid_Context_Network_for_Semantic_Segmentation_CVPR_2019_paper.pdf
- code: https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/apc_head.py
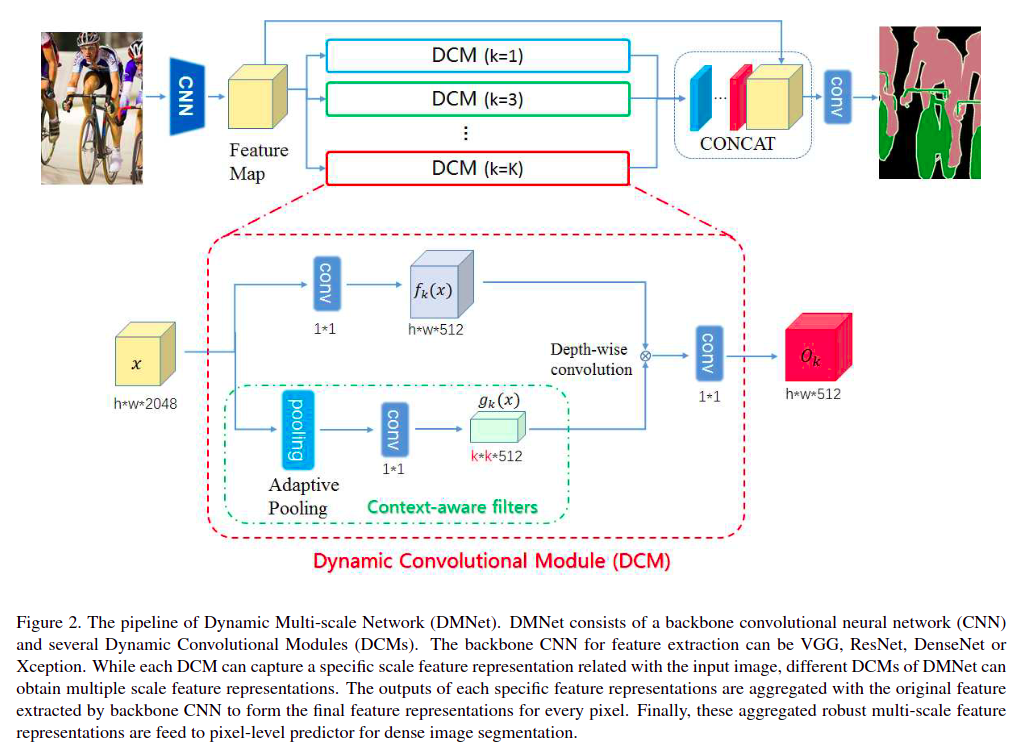
19. DMNet
DMNet的全称是Dynamic Multi-scale Filters Network,本文根据输入特征动态获得多种尺度的卷积核参数,本质也是一种全局Attention机制- paper: https://openaccess.thecvf.com/content_ICCV_2019/papers/He_Dynamic_Multi-Scale_Filters_for_Semantic_Segmentation_ICCV_2019_paper.pdf
- code: https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/dm_head.py
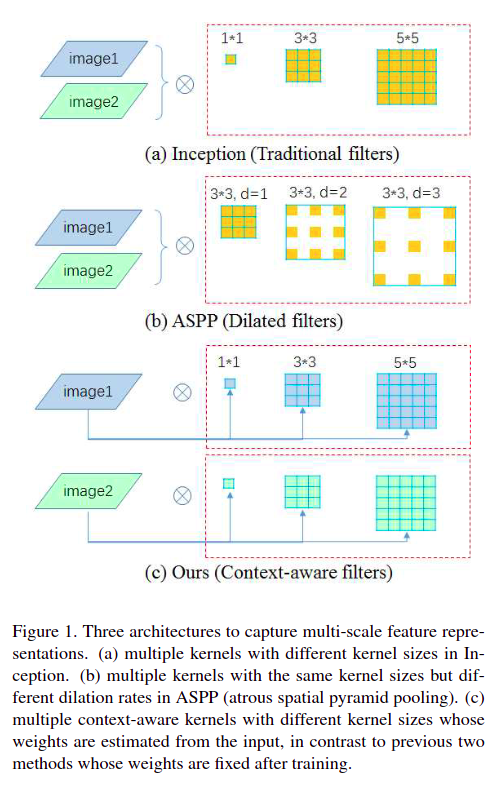
之前的网络结构都是通过空洞卷积或大卷积核实现多尺度
DMNet通过输入特征的Adaptive Pooling生成动态卷积核实现多尺度
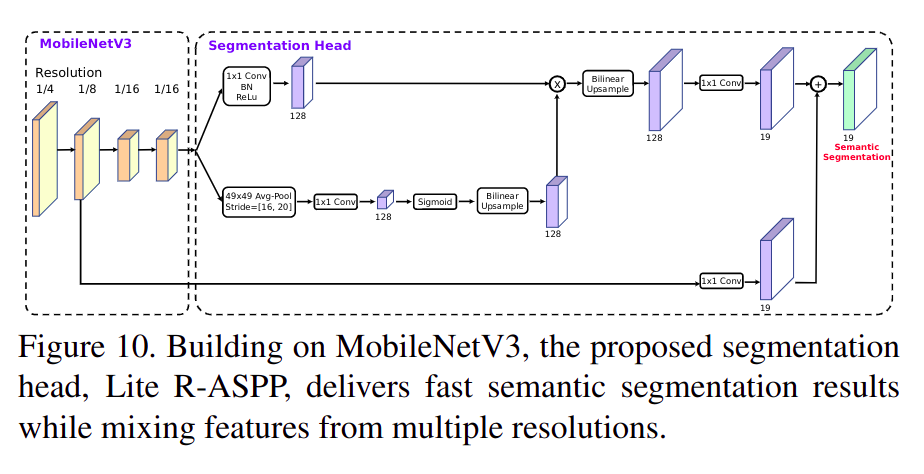
20. LRASPP
LRASPP全称是Lite Reduced Atrous Spatial Pyramid Pooling(轻量简化空洞空间金字塔池化),是在MobileNet V3论文中提出的结构,是和MobileNet V2提出的RASPP结构对比,更轻量效果更好;从实现上看LRASPP并没有空洞卷积和空间金字塔池化…,而是通过全局scale实现的Attention- paper: https://arxiv.org/pdf/1905.02244.pdf (
MobileNet V3) - code: https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/dm_head.py
21. ISANet
ISANet的全称是Interlaced Sparse Attention Network(交错稀疏注意力网络),通过feature map shuffle实现长范围和短范围的稀疏注意力。- paper: https://arxiv.org/pdf/1907.12273.pdf
- code: https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/isa_head.py
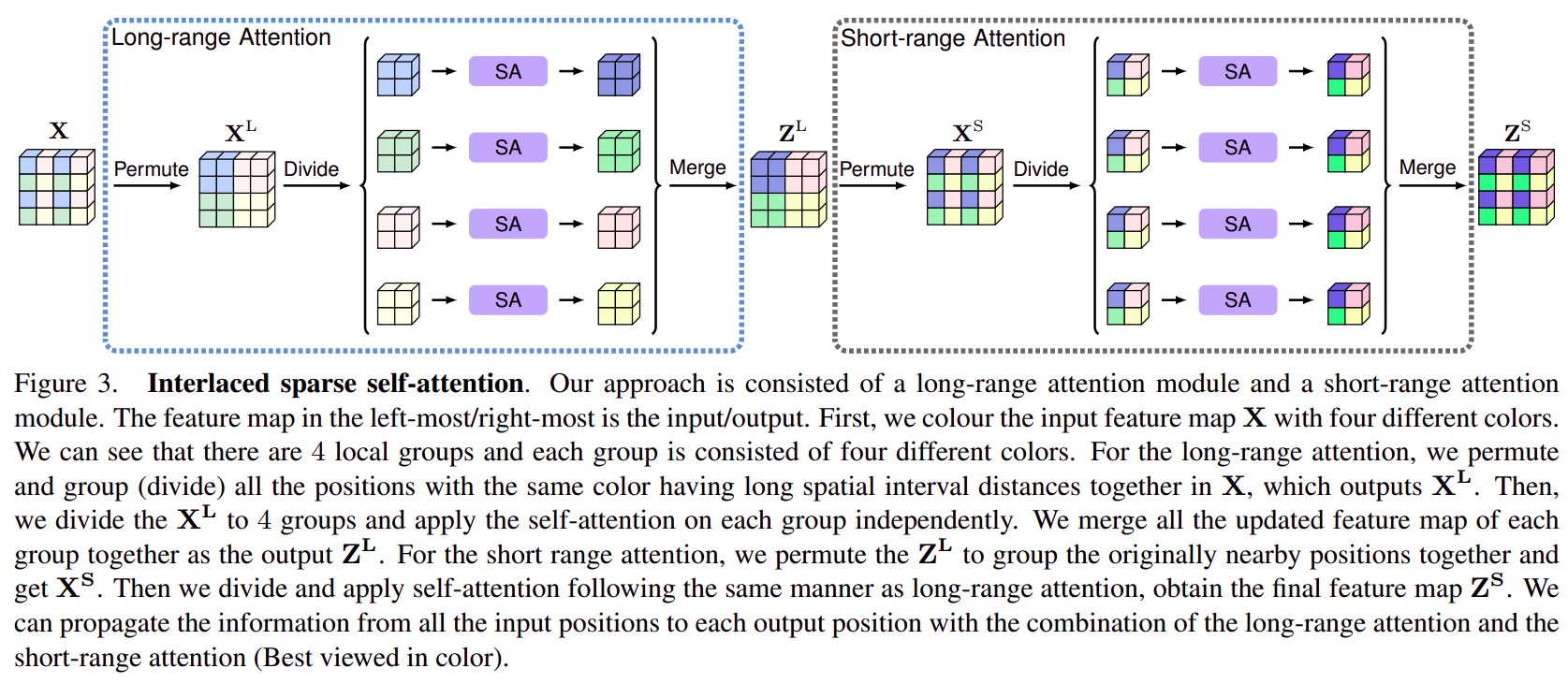
- 利用
feature map重排实现长范围或短范围的稀疏注意力。
22. DNLNet
DNL的全称是Disentangled Non-Local(分离Non-local),对原始Non-local做了改进,参数量和计算量更高,效果更好- paper: https://arxiv.org/pdf/2006.06668.pdf
- code: https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/dnl_head.py
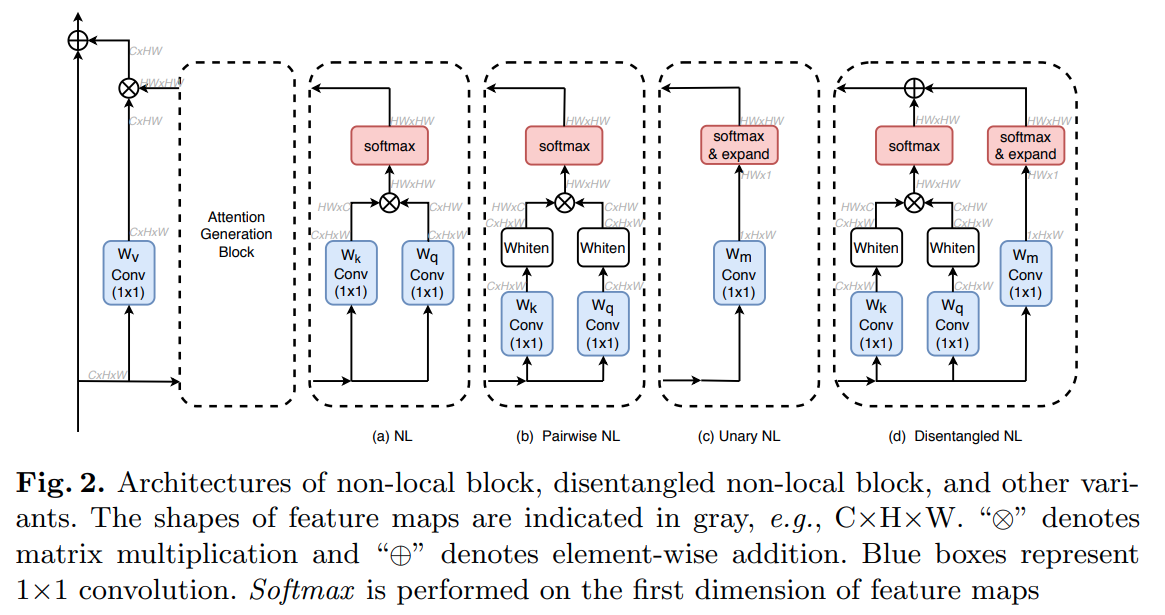
DNL结构(图 d)在原始Non-local结构(图 a)上做了如下改动:
- 加入了一元
Non-local分支Unary Non-local- 在二元分支矩阵乘之前加入了白化操作(
H*W维度减均值,相当于instance norm)
由于减了均值,所以二元分支上 “+” 这一点在Attention map上的索引heat map变干净很多(相当只学习残差)
这张图也从侧面反映了Non-local还是很强的,Attention不是在讲故事

23. BiSeNet
BiSeNet的全称是Bilateral Segmentation Network(双边分割网络),是一个分割专用的神经网络(包括专用backbone和decode head)- paper: https://arxiv.org/pdf/1808.00897.pdf
- code: https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/backbones/bisenetv1.py
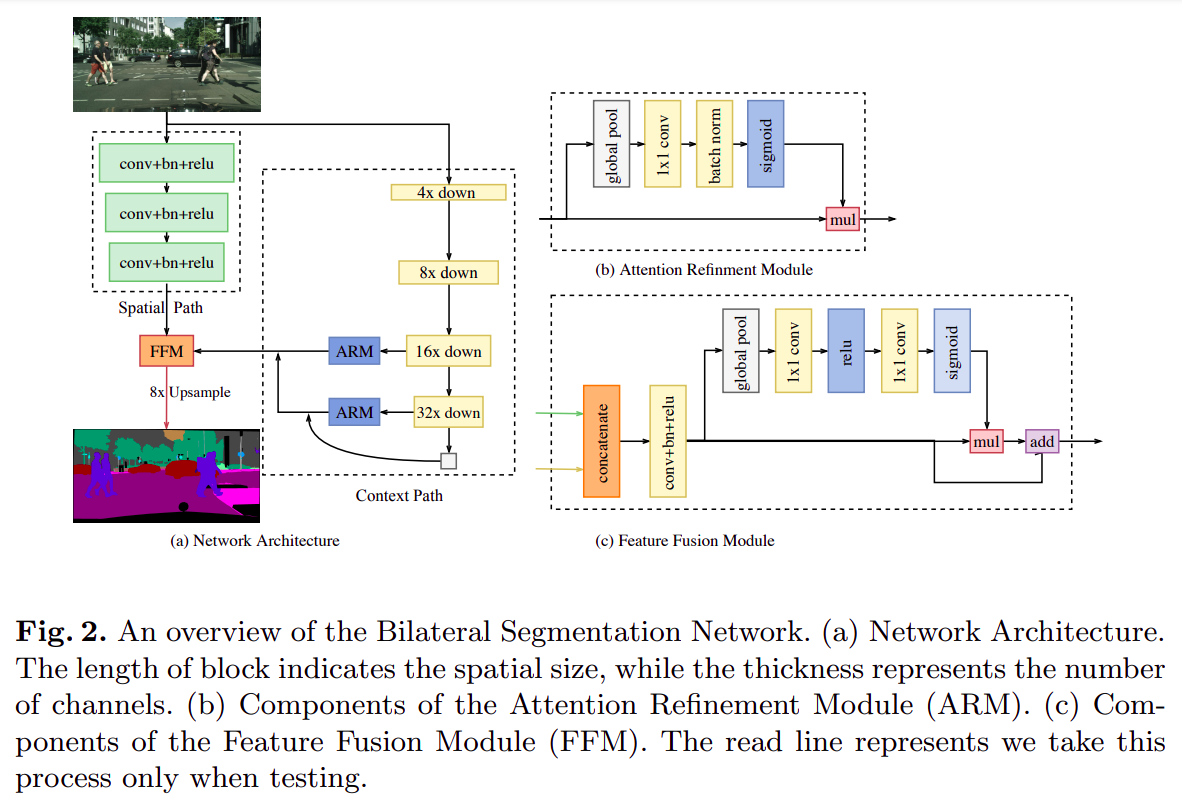
backbone主要分成两个分支spatial path和context path,本质就是在基础backbone的基础上加入了一个计算量(通道数)非常小的attention branch增加上下文信息,最后融合两通道特征送入decode headdecode head就是基础的FCN
24. BiSeNet V2
BiSeNet的改进版- paper: https://arxiv.org/pdf/2004.02147.pdf
- code: https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/backbones/bisenetv2.py
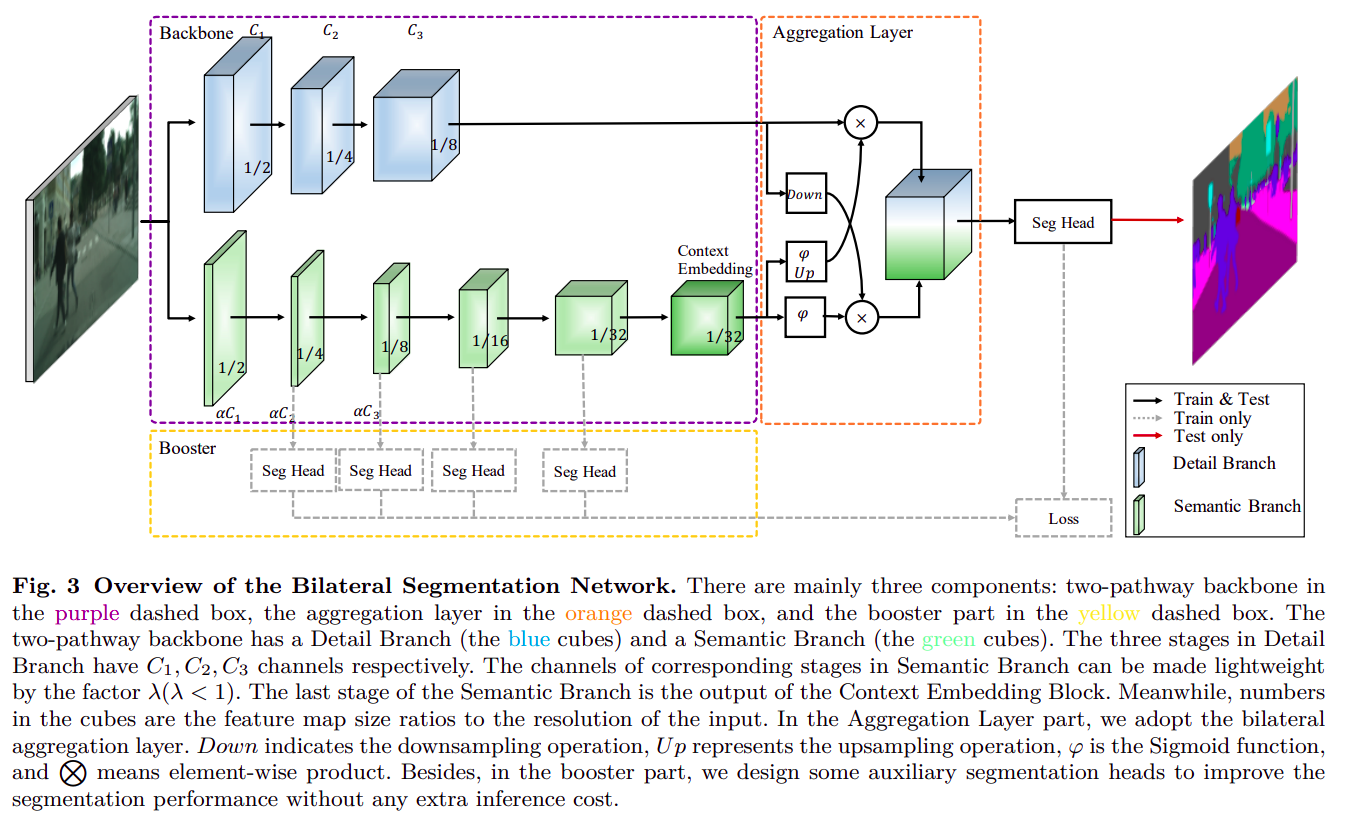
对
BiSeNet主要改进有:
context branch上增加了更多更复杂的模块,可更好收集上下文信息context branch上增加了更多监督,每个尺度上都有监督损失- 分支融合模块设计的更加复杂
25. SDTC
SDTC的全称是Short-Term Dense Concatenate network,在BiSeNet系列的基础上将context branch变成训练时的监督(或者说融合两路信息到一路上)- paper: https://arxiv.org/pdf/2104.13188.pdf
- code:
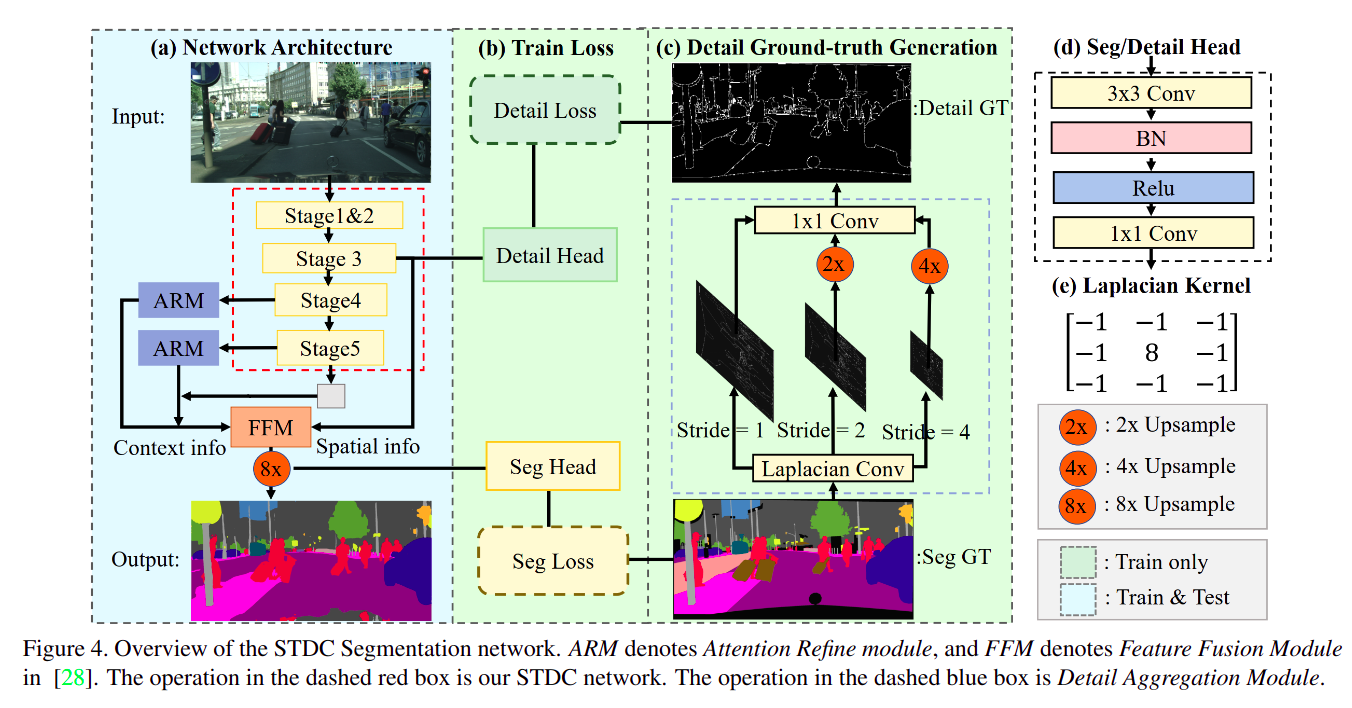
很新颖的 Loss 设计,效果和计算量都优于
BiSeNet系列
这就是SDTC模块
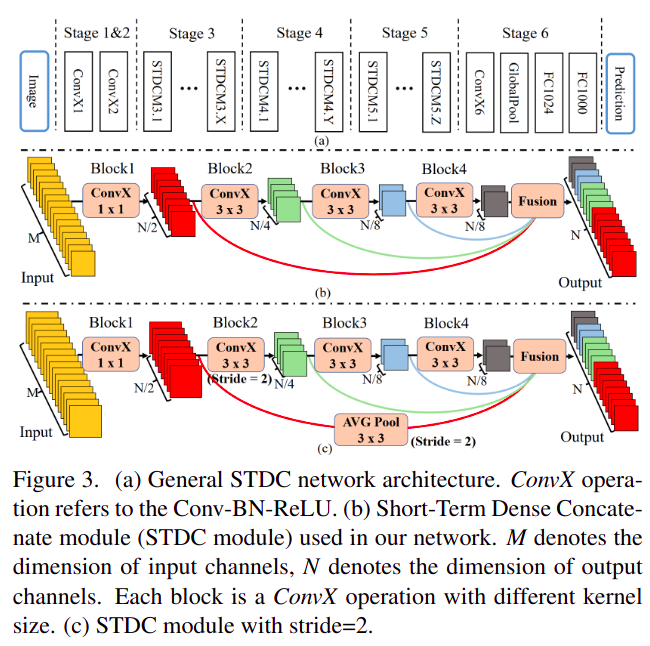
26. SETR
SETR的全称是Segmentation Transformer- paper: https://arxiv.org/pdf/2012.15840.pdf
- code:
- backbone: https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/backbones/vit.py
SETR_PUP_decode_head: https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/setr_up_head.pySETR_MLA_decode_head: https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/setr_mla_head.py
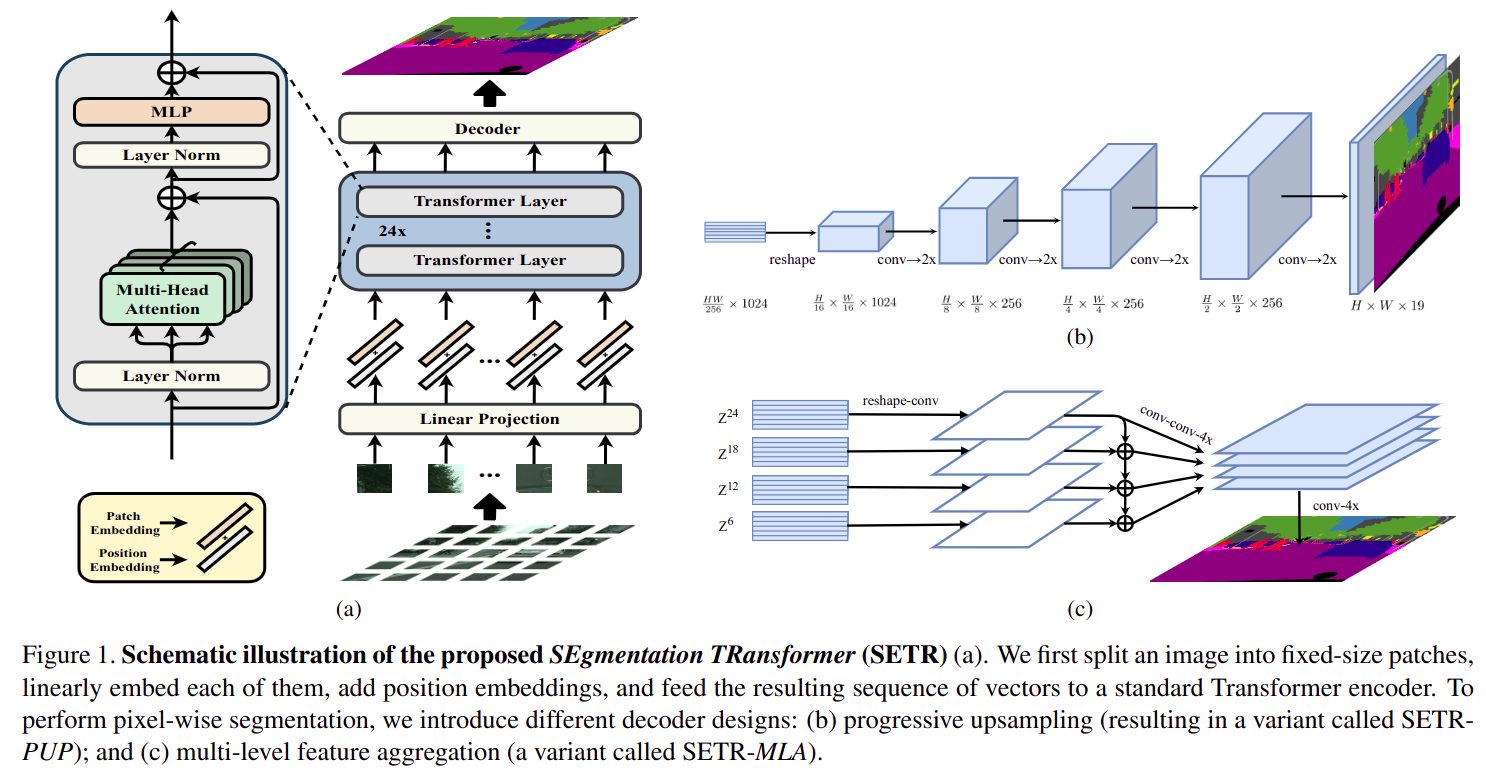
- 本质是
Vit(vision transformer)做backbone,FCN/ 类似FPN做decode head的分割算法- 为了缩减计算量,
Vit会将原图剪成多个patch(worth 16x16 words...),每个patch单独输入到 24 层Transformer Encoder中,每个patch内部独立做全局attention- 剪
patch带来的问题是:与其他CNN backbone + decode head结构不同,Transformer backbone + decode head结构中decode head需要顺序inference每个patch feature(注意图aDecoder输入为多个patch feature),最后拼回到整张图大小SETR_UPU decode head==sequence FCNSETR_MLA decode head==sequence FPN(Attention不改变输入宽高,所以不存在严格意义上的 多尺度,只是不同网络深度的特征)
27. DPTNet
DPTNet的全称是Dense Prediction Transformer Network,本质和SETR一样都是使用Vit做backbone- paper: https://arxiv.org/pdf/2103.13413.pdf
- code:
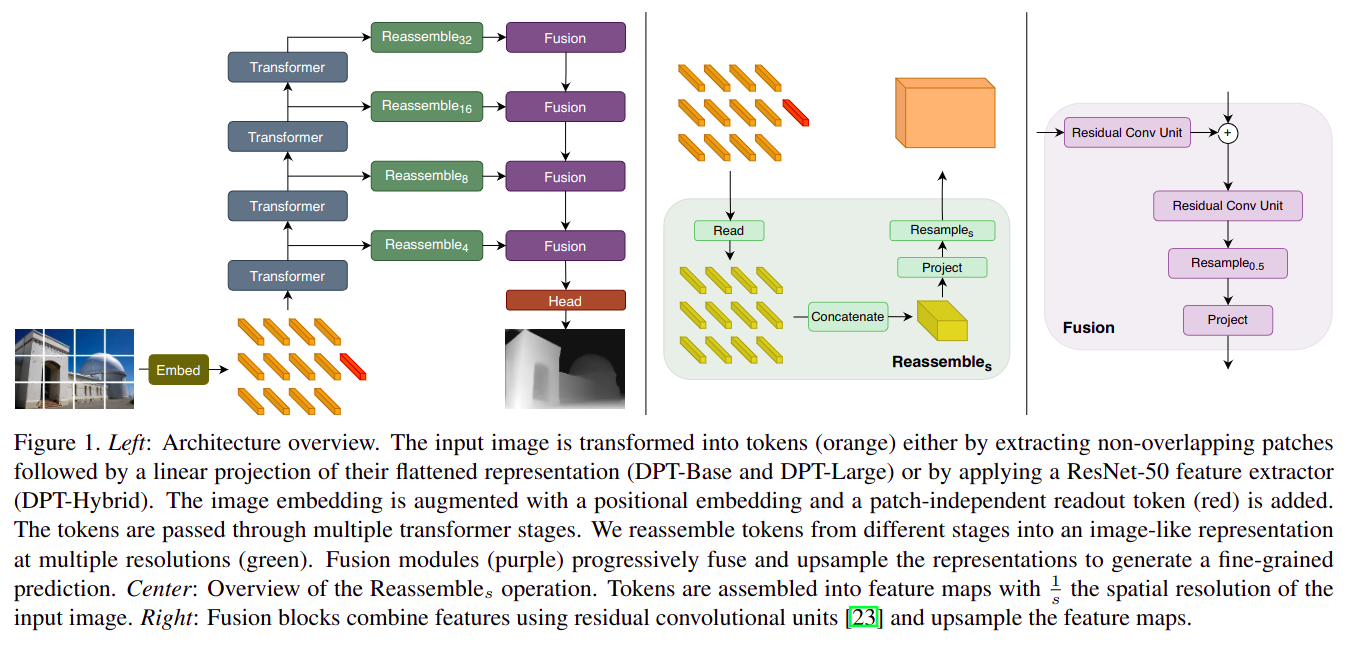
- 本质和
SETR一样都是使用Vit做backbone- 和
SETR不同的地方在于:
- 不同
backbone深度特征融合方式更复杂,更接近FPNdecode head不再是输入sequence patch feature,而是输入融合后的全图feature
28. Segmenter
Segmenter全称是Segmentation Transformer,用了纯Transformer架构而不是Transformer Encoder + CNN Decoder架构- paper: https://arxiv.org/pdf/2105.05633.pdf
- code:
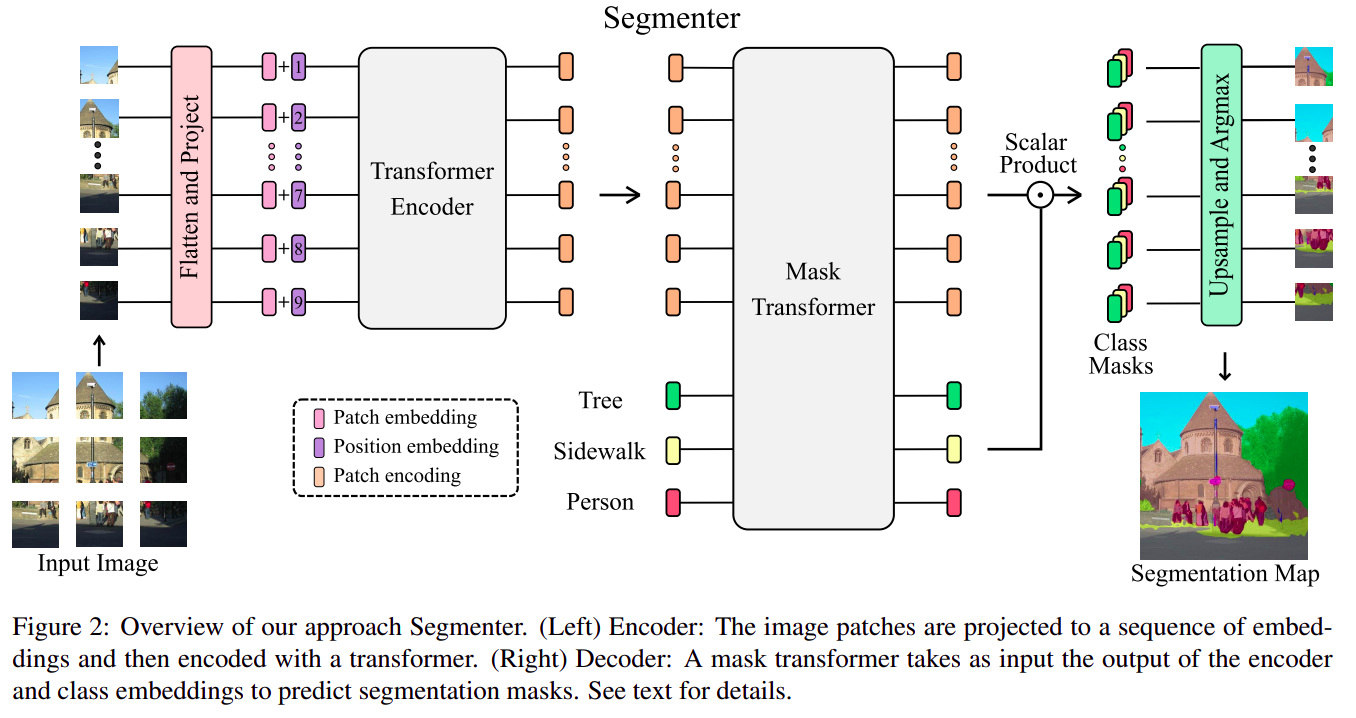
- 用了纯
Transformer架构(Transformer Encoder + Decoder),SETR和DPT都是Transformer Encoder + CNN Decoder
29. SegFormer
SegFormer全称也是Segmentation Transformer…,是NVIDIA对SETR的高效实现版,backbone和decoder head都进行了轻量化升级- paper: https://arxiv.org/pdf/2105.15203.pdf
- code:
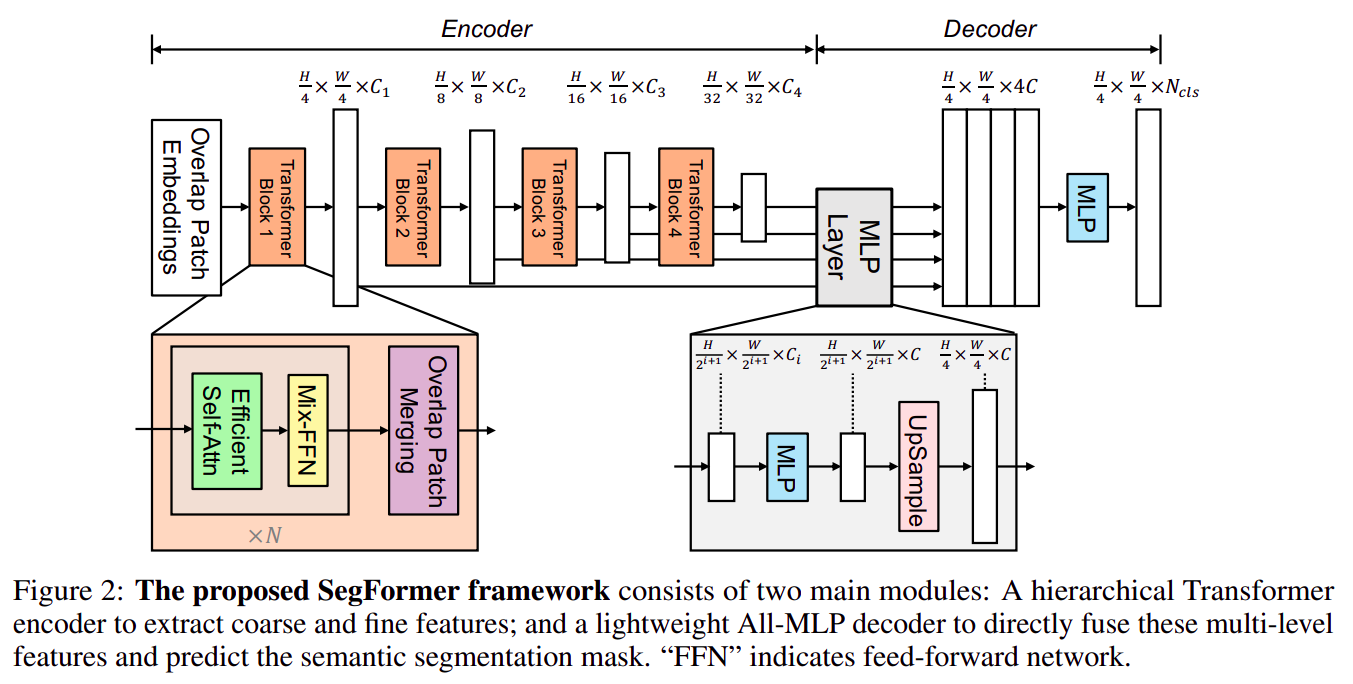
backbone不再是标准Transformer Encoder(Vit),而是改成了更轻量化的MixVisionTransformer(Mit)
Mit使用了更大的patch且patch之间存在overlapMit使用了coarse-to-fine的特征表示,随着Transformer Encoder变深feature map宽高变小Mit使用了更简单的Self-Attention公式Mit去掉了position embeding,使用了Mix-FFNdecode head使用了纯MLP,且很自然的融合了多尺度(真.多尺度)
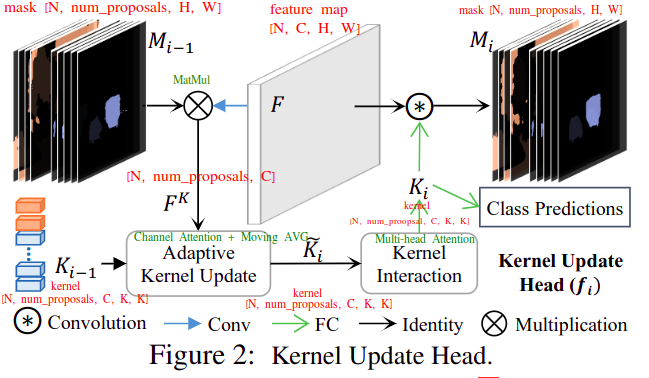
30. KNet
KNet的全称是Kernel Network,是一种跳出语义分割、实例分割、全景分割原有框架的一种新分割范式,用一组kernel去预测一个分割mask,最多预测num_proposals个(类似DETR的策略),训练时用最优匹配的方法计算损失函数;优点是在框架上统一了所有分割任务(语义分割、实例分割、全景分割),缺点decode head就是实现复杂,融合了Channel Attention + Multi-head Attention + RNN- paper: https://arxiv.org/pdf/2106.14855.pdf
- code: https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/knet_head.py
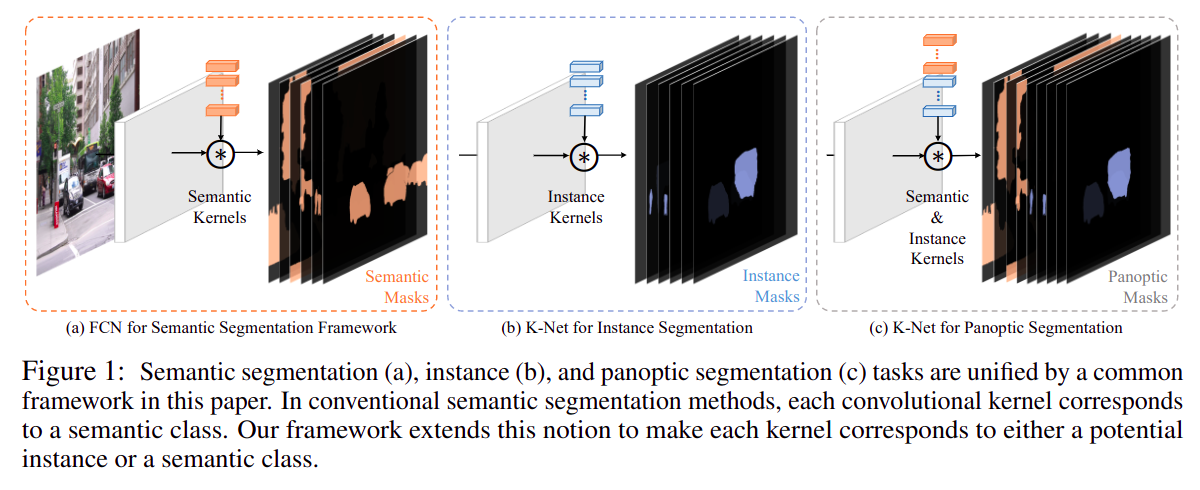
从框架上统一了三种分割方式
红字标出的是每个张量的shape
绿字标出的是每个计算过程实际是在做什么
上述过程会像RNN一样循环多次去更新kernel,使得结果更好(重复使用backbone的输出)