URL
TL;DR
Faster RCNN 系列、SSD、YOLOv2~v5(注意 YOLOv1 不包括在内)都是基于 Anchor 进行预测的。- 本文提出一种 Anchor Free 的 one stage 目标检测方法,整个模型结构非常轻量,效果强大。
- 由于没有了 anchor,所以 fcos 可方便拓展到其他任务。
Algorithm
网络结构
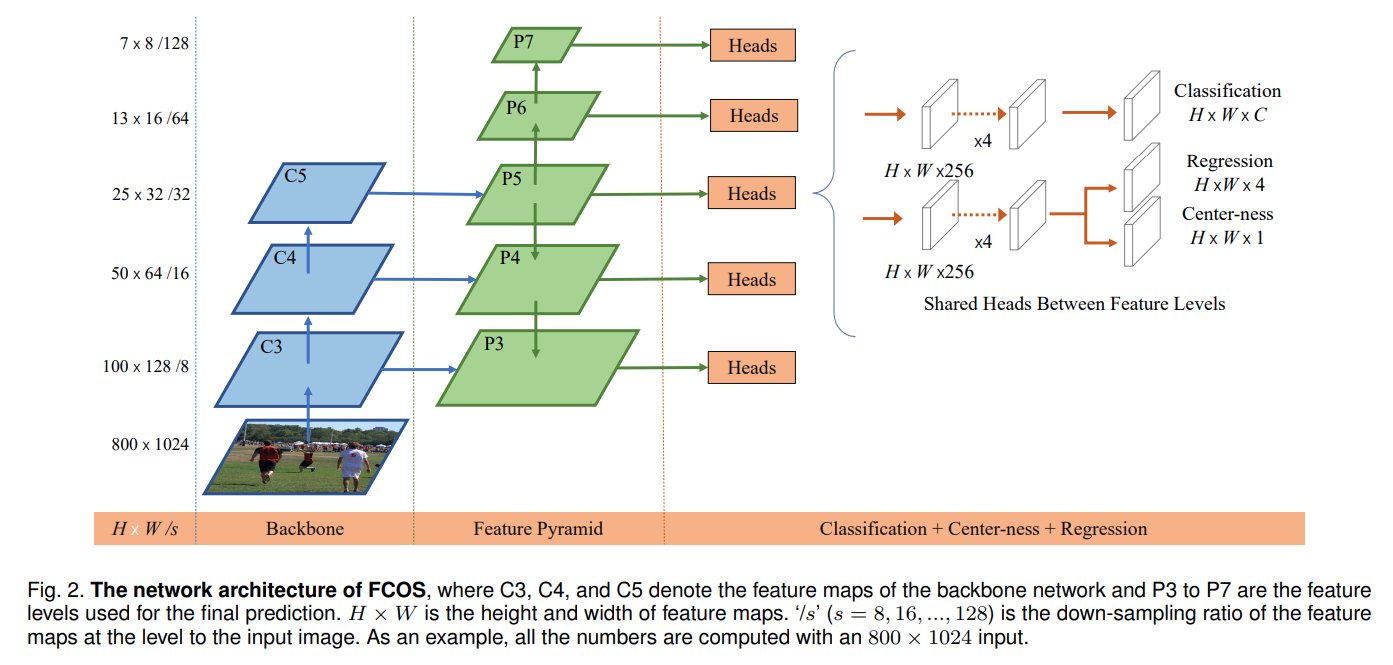
backbone + FPN 输出了 5 种尺度的 feature map 用于预测,由于是全卷积网络,所以 5 个输出头共享一份参数,对于每个尺度的 feature map 上的每一个位置 预测包括类别(N,Cls,H,W)、框的位置(N,4,H,W)和一个中心置信度(N,1,H,W)。- 由于共享输出头,所以本文作者 为每个输出头增加了不共享的 scale 参数,scale.shape == (num_of_level, 1)
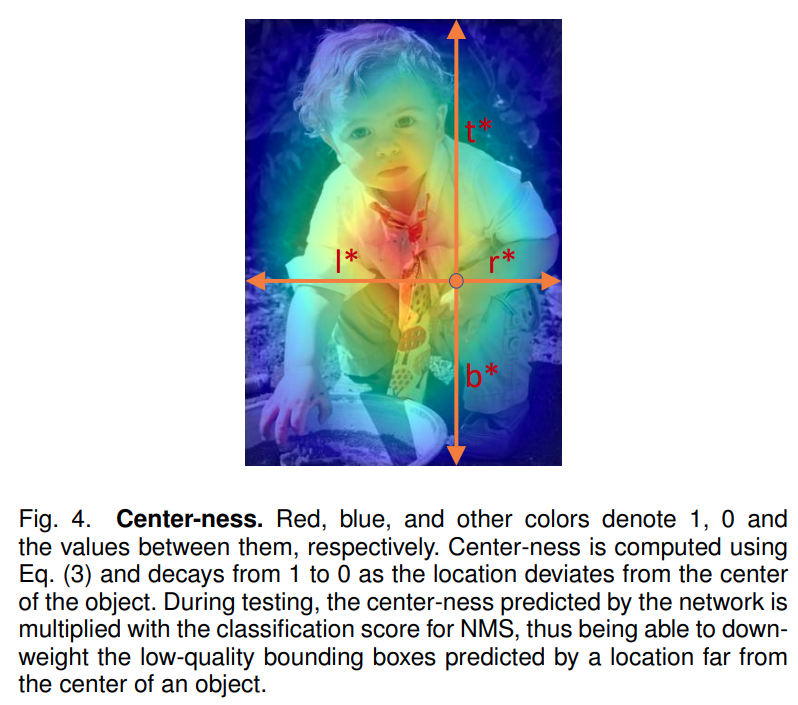
- 其中位置参数模型预测的是如上图所示的(l,t,b,r),即相对于 feature map 上的点到 GT 的上下左右偏移量。
centerness
- centerness=max(l⋆,r⋆)min(l⋆,r⋆)×max(t⋆,b⋆)min(t⋆,b⋆) ,即
GT bbox 内的点越靠近中心越大,越远离中心越小,取值范围 [0, 1],可视化 centerness 热力图如上图所示。
- 最终预测时,score 阈值过滤的是
centerness * score。
损失函数
L({px,y},{tx,y})=Npos1∑x,yLcls(px,y,cx,y⋆)+Nposλ∑x,yIcx,y⋆>0Lreg(tx,y,tx,y⋆)+Nposγ∑x,yIcx,y⋆>0Lctr(sx,y,sx,y⋆)
- 其中 px,y 表示在特征图点(x,y)处预测的每个类别的 score
- cx,y⋆ 表示在特征图点(x,y)处的真实类别(负样本类别为 0)
- tx,y 表示在特征图点(x,y)处预测的目标边界信息
- sx,y 表示在特征图点处预测的centerness
- Lcls 使用
focal loss 以平衡正负样本
- Lreg 使用
GIOU loss,且只对正样本计算
- Lctr 使用
focal loss,且只对正样本计算
正样本选择策略
- 与
anchor base 方法不同,fcos 对正样本的选择较为苛刻,仅当 feature map 上的某个点落入 gt bbox 中心区域(sub-box)时才被当做正样本 。
sub-box 的定义: (cx−rs,cy−rs,cx+rs,cy+rs) ,其中 (cx,cy) 表示 gt bbox 中心点在原始图上的坐标;s 表示 stride 即当前 feature map 相较于原图下采样倍数;r 表示 radius 半径超参数,在 coco 数据集上取 1.5。- 除了正样本之外,其他样本的
cls 类别都被置为 0(background),负样本只计算 cls loss,不计算 reg loss 和 centerness loss(也没法计算,有框才能计算)。
Ambiguous sample
anchor free 的检测方法绕不开一个天然的问题:如果一个 feature map 的特征点(x,y)同时是两个 GT bbox 的正例,应该如何预测,毕竟 fcos 每个特征点只预测一个框。- 本文缓解该问题的方法是:使用 FPN box 尺度分配 + center sampling。
FPN bbox 尺度分配是一个常用的解决 Ambiguity 问题的方法,越大的 feature map 负责检测越小的框。(将 Ambiguity 出现的概率从 23.16% 降低到 7.24%)center sampling:即上面提到的 sub-box 采样方法,radius = 1.5。(将 Ambiguity 出现的概率从 7.24% 降低到 2.66%)
Thought
FCOS 是一种很简单高效的 2D anchor free 物体检测算法,迁移性强,启发了后面的 FCOS3D 单目 3D 检测。