URL
- paper: https://arxiv.org/pdf/2304.02643.pdf
- code: https://github.com/facebookresearch/segment-anything
- demo: https://segment-anything.com/demo
TL;DR
- 本文提出一种类似
chatGPT的交互式Zero-shot分割算法,用户给出一个prompt(支持 point / box / mask / text),模型会根据Prompt语义完成分割,无需在特定分割任务数据上fine-tuning(类似于GPT2和之后的系列模型) - 本文一个非常重要的理念是
Data Centric,即以数据为中心而不是以模型为中心,这一点和GPT系列也不谋而合- 传统视觉算法是在固定的数据集上修改模型结构实现模型效果的提升,实际是以模型为中心
- 数据为中心的算法通常固定模型结构,通过例如
RLHF(Reinforcement Learning from human feedback)的方法,使用模型辅助标注员高效标注大量数据(11 亿个 mask 区域),重复迭代提高效果
- 模型本身由三部分组成:
image_encoder:提取图片特征,使用的是ViT模型,在交互过程中只需要推理一次prompt_encoder: 提取prompt特征,将人的输入(例如点或框)编码到特征空间mask_decoder: 输入为图片特征和prompt特征,融合后输出分割mask
Algorithm
任务定义
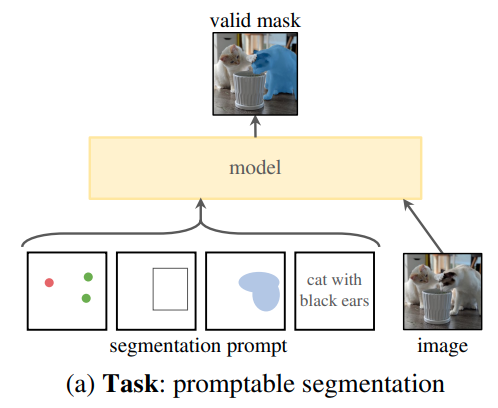
理论上支持 point / box / mask / text,但 demo 和 code 都只包含了 point / box / mask
模型结构
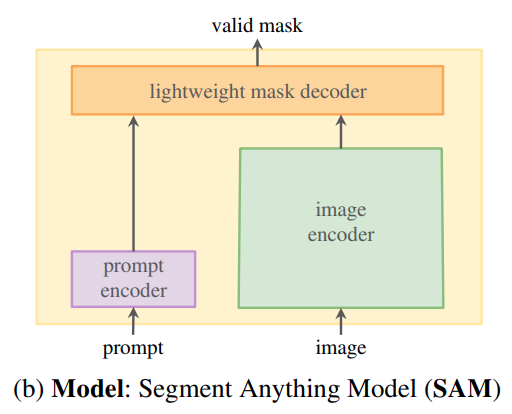
image encoder 是 VIT
prompt encoder 对于 box / point prompt 只是简单的位置编码;对于 mask 是几层简单的卷积
lightweight mask decoder 是轻量级 transformer
Data centric
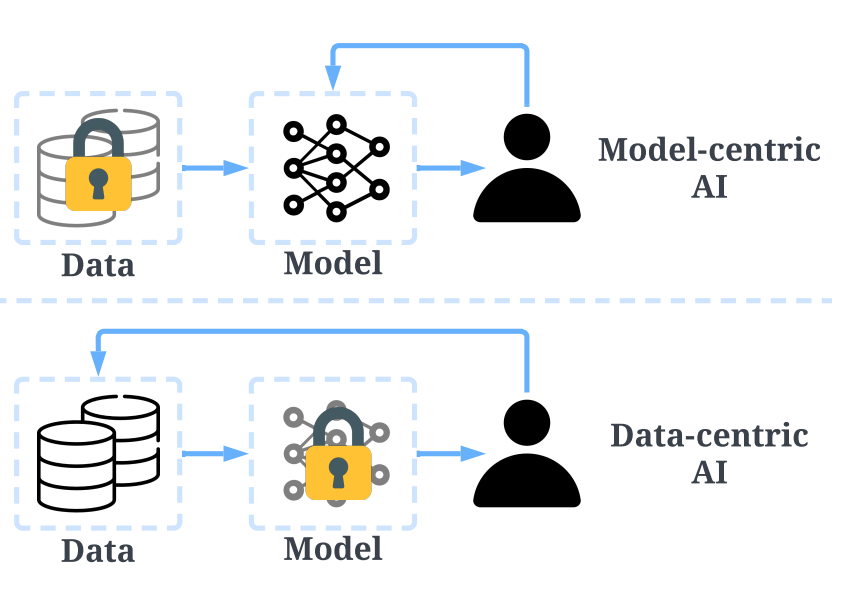
模型为中心和数据为中心的对比
使用效果

图中的框为用户输入的
prompt,模型会根据prompt输出分割结果
Thought
Data centric感觉一定是未来,但形式一定不会以RLHF形式存在,而更多的以自监督形式存在prompt未来会取代fine-tuning这个词