URL
TL;DR
- 作者团队训练了一个
96层Transformer共1750亿参数的超大模型(GPT2只有约15亿参数),在下游任务上无需fine-tuning即可得到很好的效果。 - 本质是
GPT2的放大版(参数量放大了一百多倍)
Algorithm
- 在下游任务上,可以使用
Zero Shot、One Shot、Few Shot三种方式推理模型,下图以英语翻译法语的例子介绍三者的区别:

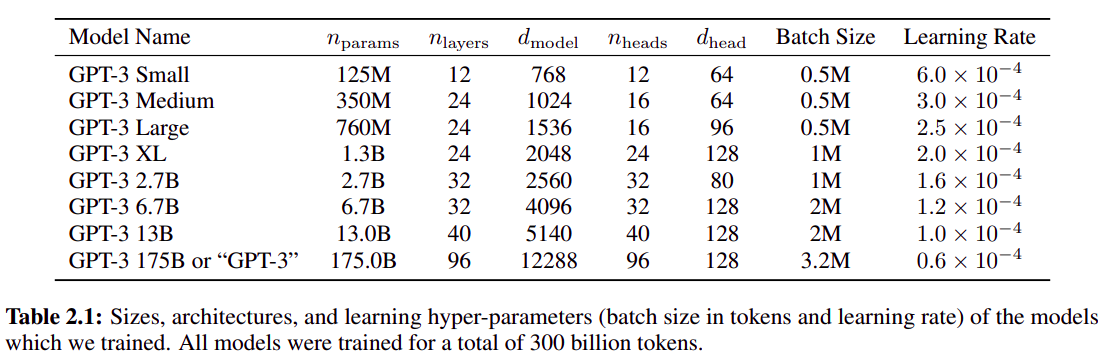
- GPT3 系列模型详细设置:
- GPT3 自监督训练数据:
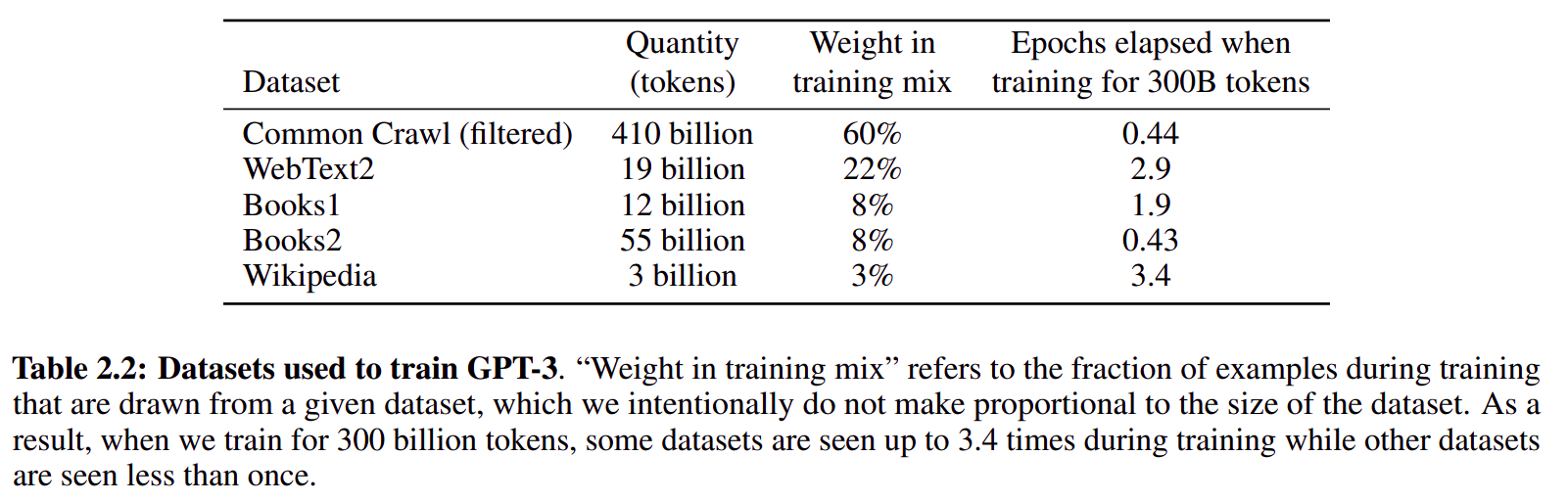
使用了
common crawl数据集,由于common crawl数据集很脏,所以训练是数据采样率并不高
- 下图是在几个下游任务上和 SOTA 算法的比较:
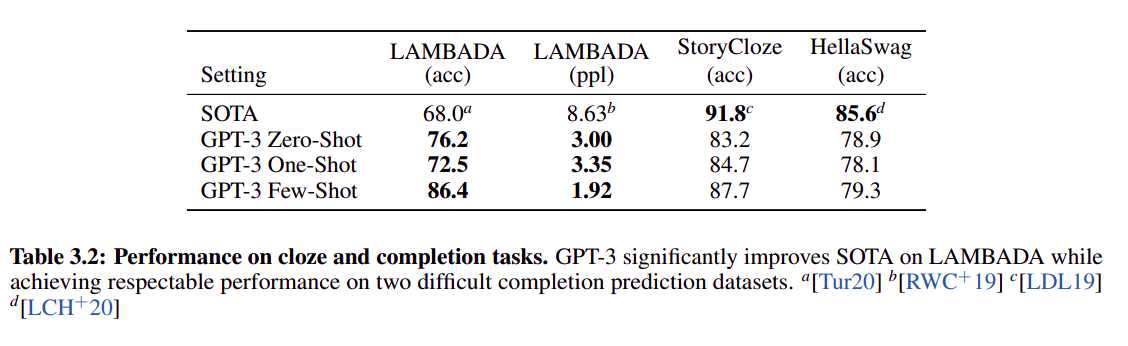
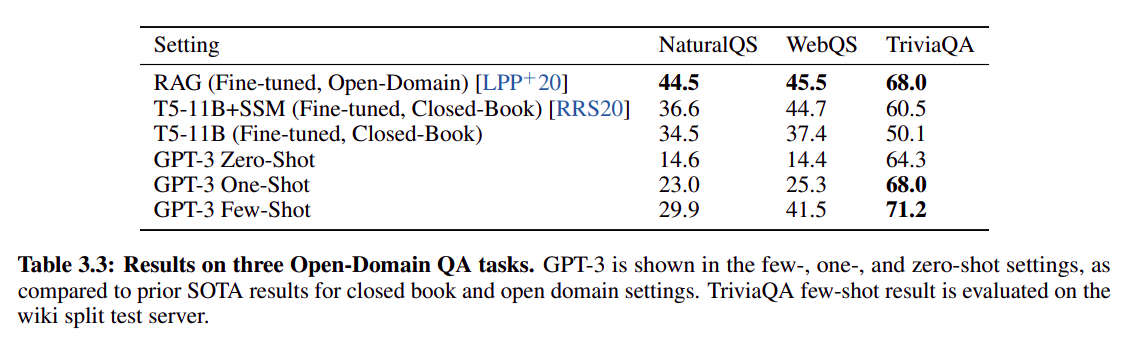
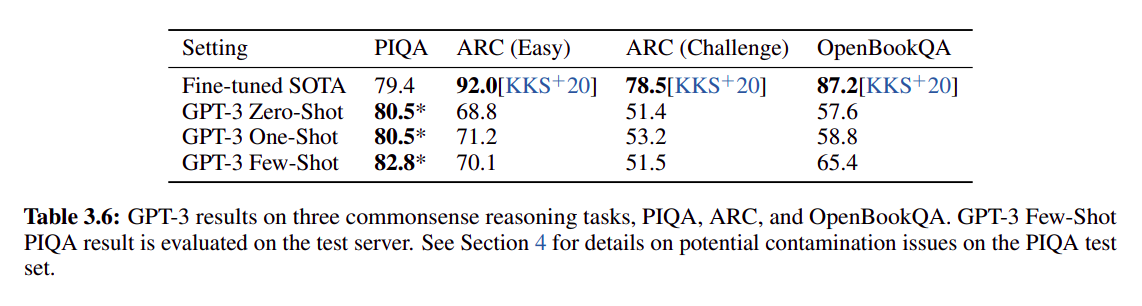
从普遍表现看,GPT3 few shot 效果 > one shot > zero shot,不一定比 SOTA 点高(SOTA 普遍使用了 fine tuning,直接比较不公平)
Thought
- 在某些任务上,
GPT3 few shot效果可媲美fine tuning SOTA,可以说明GPT3还是非常强大的 - 比上一代参数量提高一百多倍,开启了大模型时代…