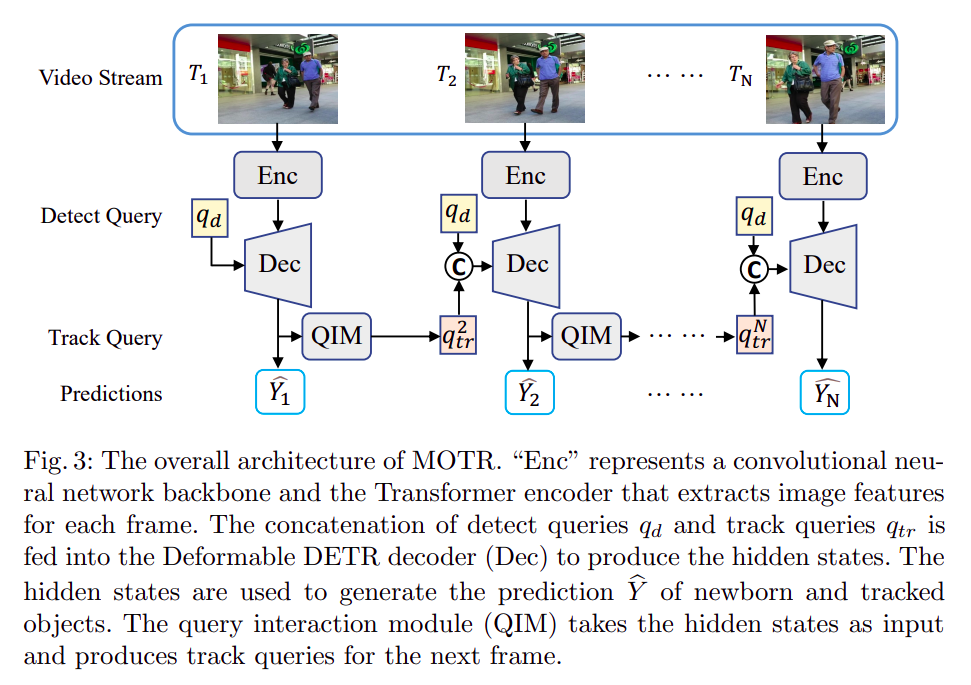
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| def process_frame(frame, detect_queries, track_queries=None, ground_truths=None):
frame_features = extract_frame_features(frame)
if track_queries is None:
hidden_states = deformable_detr_decoder(detect_queries, frame_features)
else:
queries = concatenate(track_queries, detect_queries)
hidden_states = deformable_detr_decoder(queries, frame_features)
predictions = predict(hidden_states)
track_queries = qim(hidden_states)
if ground_truths is not None:
loss = cal(predictions, ground_truths)
backpropagate(loss)
return predictions, track_queries
def process_video(video, ground_truths=None):
detect_queries = initialize_detect_queries()
track_queries = None
for frame in video:
predictions, track_queries = process_frame(frame, detect_queries, track_queries, ground_truths)
if ground_truths is None:
yield predictions
|