URL
TL;DR
BEVDet4D 是基于 BEVDet 加入了时序信息的一篇论文- 具体来说就是将上一帧的
BEV Feature 和本帧的 BEV Feature 对齐后 Concat 到一起送入 BEV Encoder 中进行 BEV 视角下的 3D 目标检测
BEVDet 论文中的 image encoder + view transformer 完全保持不变- 由于有两帧的信息,所以对速度的预测相较于单帧有较大提升
Algorithm
整体流程
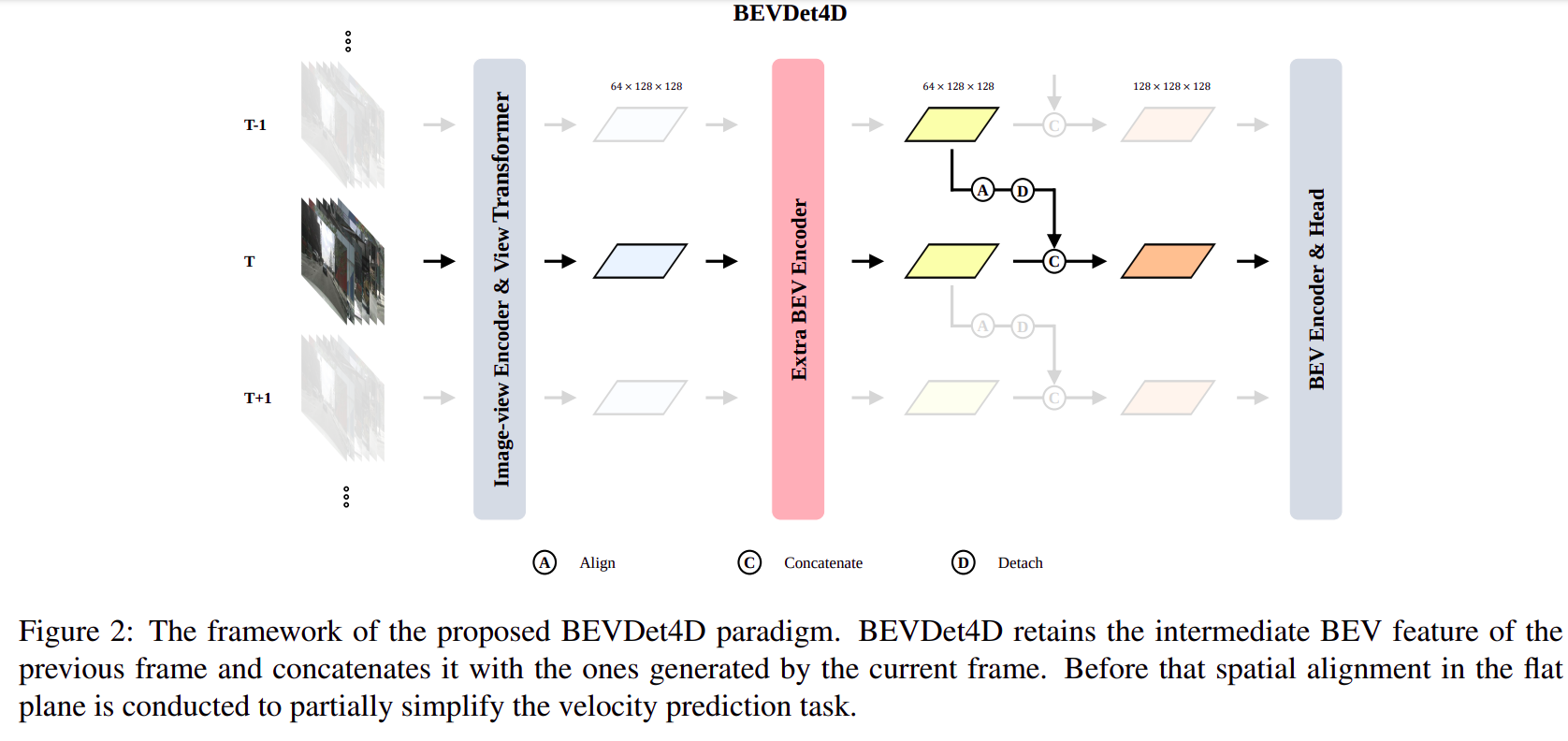
在 BEV Feature 层面(View Transformer 的输出)融合两帧信息
算法的伪代码表示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| class BEVDet4D:
def __init__(self):
self.image_view_encoder = ImageViewEncoder()
self.view_transformer = ViewTransformer()
self.bev_encoder = BEVEncoder()
self.head = DetectionHead()
self.previous_bev_feature = None
def spatial_alignment(self, feature):
aligned_feature = ...
return aligned_feature
def forward(self, current_image):
image_feature = self.image_view_encoder(current_image)
transformed_feature = self.view_transformer(image_feature)
current_bev_feature = self.bev_encoder(transformed_feature)
if self.previous_bev_feature:
aligned_previous_feature = self.spatial_alignment(self.previous_bev_feature)
fused_feature = concatenate(aligned_previous_feature, current_bev_feature)
else:
fused_feature = current_bev_feature
detections = self.head(fused_feature)
self.previous_bev_feature = current_bev_feature
return detections
bevdet4d = BEVDet4D()
detections = bevdet4d.forward(current_image)
|
result
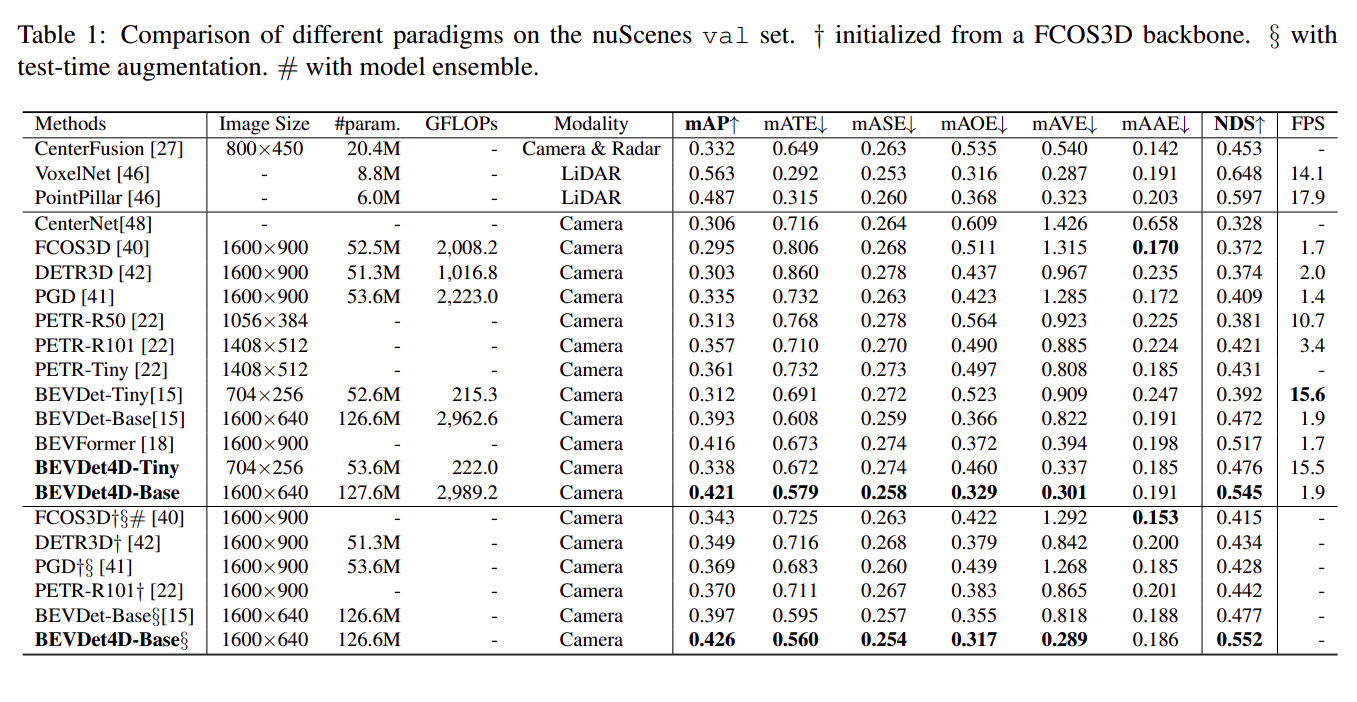
效果比 BEVDet 好了不少,尤其是 mAVE (速度误差)
Thought
- 没有很大的创新点,更像是
BEVDet 的一个使用 trick
BEVDet 的计算量主要分布在 image encoder 和 view transformer,所以复用上一帧的 BEV feature 即充分利用了上一帧的计算量,对当前帧引入的额外计算量也比较可控(BEV encoder 和 task head 都比较轻量)