0%
URL
TL;DR
- 传统
BEV 算法中 View Transform 都是通过 LSS 实现 Image View 到 BEV View 的转变,这种视角转换方法依赖于图像视角的深度估计(显式(例如 BEVDepth)或隐式(例如 LSS / BEVDet 等))。
- 本文提出一种新的通过时空注意力机制实现的
View Transform 方法,在 Neuscenes 数据集上取得了不错的 3D 目标检测成绩(略差于 BEVDet4D)。
Algorithm
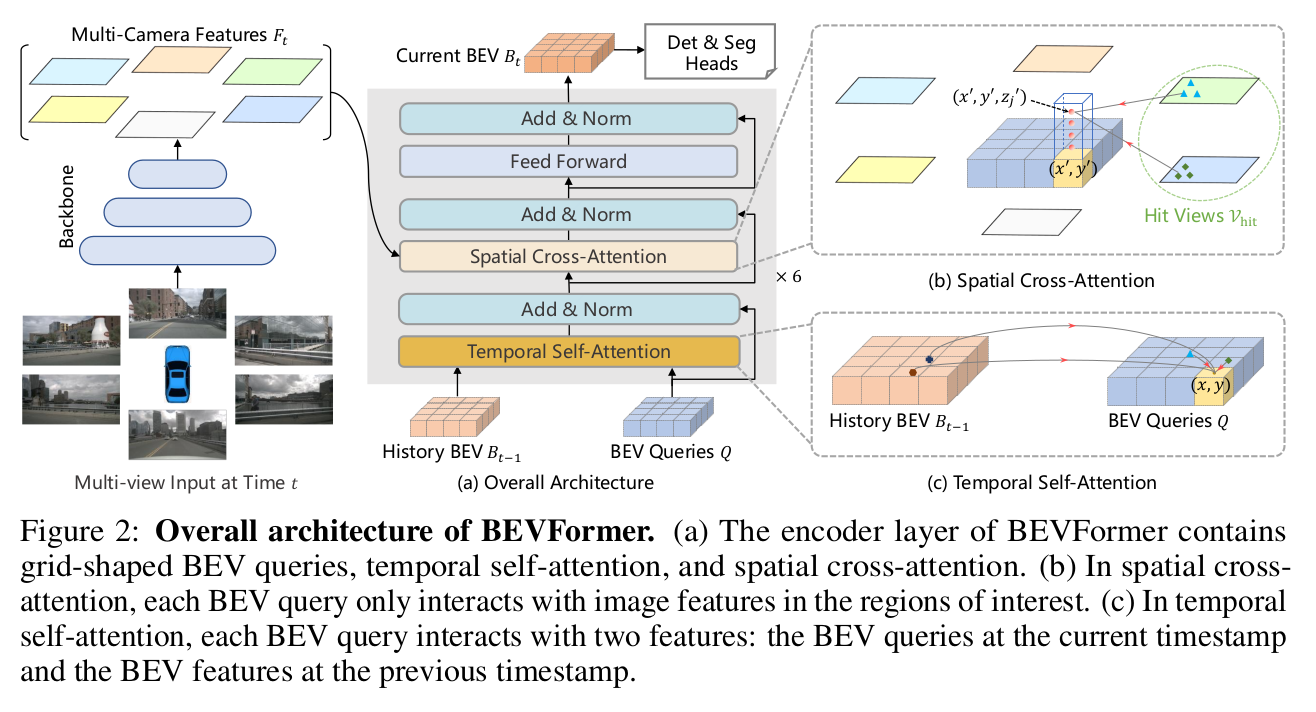
整体架构
1. 输入
- 输入包含两部分,分别是:
- 环视图(
6 张)
BEV Queries(shape = [num_voxel, dim])History BEV Feature(上一帧的 BEV Feature 输出,shape = [num_voxel, dim])
2. 输出
- 输出为当前帧的
BEV Feature(shape = [num_voxel, dim]),记作 Bt
- 暂时不考虑任务头
3. 网络模块
- 图像特征提取
6 张图片单独做 CNN base 特征提取,输出记作 Ft
- 时序信息融合:
- 将构造的
BEV Queries(记作 Q),和上一帧的 BEV Feature(记作 Bt−1)做 Self-Attention
- 其中
Q 作为 Query,Bt−1 作为 Key / value,做 Attention 运算
- 虽然这里的
Query / Key / Value 并不同源,但依然被称为是 Self-Attention 而不是 Cross-Attention,是因为 Q 和 Bt−1 都属于 BEV 语义
- 输出记作
Q'
- 空间交叉注意力(视角转换)
- 此步骤是本文的重点,
BEVFormer 通过这一步将透视图特征转换为俯视图特征
- 输入为:
- 做
Cross-Attention 运算,其中:
Q' 作为 Queries- Ft 作为
Key / Value
- 用预设的无意义且可学习的
BEV Queries 去查询图片总体特征,得到 BEV Feature 输出,记作 Bt
- 任务相关头
- 输入为:
BEV Feature
- 输出为:
BEV 视角下的检测 / 分割等任务预测结果
- 模型结构:可以是
CNN base 也可以是 Transformer base 的
- 以上提到的所有
Attention 过程都需要额外添加 Position embedding
Thought
- 过程并不复杂,只要看过经典的
DETR,都熟悉这种套路:预设一个无意义的(随机初始化但可学习) pattern 序列作为 Query 去查询 image features,得到有意义的结果(或者说是可监督的结果)
- 后续的部分工作对其改进是:将随机初始化预设的
Query 有意义化(例如通过一个轻量化 2D 检测头预检测,得到 proposal 并编码为 Query)