URL
- paper(en): https://arxiv.org/abs/2303.18223
- paper(cn):https://github.com/RUCAIBox/LLMSurvey/blob/main/assets/LLM_Survey_Chinese.pdf
TL;DR
- 一篇关于大模型的综述,截止到 2023 年 9 月 ,对现有的大模型做了较为详细的梳理。
Survey
1. Introduction
LLM (large language model)和PLM (pretrain language model)主要有三个区别:LLM表现出一些令人惊讶的涌现能力,这些能力可能在以前较小的PLM中没有观察到。LLM将彻底改变人类开发和使用人工智能算法的方式,与小型PLM不同,访问LLM的主要方法是通过提示接口(例如GPT-4 API)。LLM的发展不再明确区分研究和工程。训练LLM需要在大规模数据处理和分布式并行训练方面具有丰富的实践经验。
- 本文主要从四个方面介绍
LLM的进展:- 预训练:如何训练出一个有能力的
LLM - 适配微调:如何从有效性和安全性两个角度有效地微调预训练的
LLM - 使用:如何利用
LLM解决各种下游任务 - 能力评估:如何评估 LLM 的能力和现有的经验性发现
- 预训练:如何训练出一个有能力的
2. Overview
2.1 大语言模型的涌现能力
LLM 的涌现能力(Emergent Abilities)被正式定义为:在小型模型中不存在但在大型模型中产生的能力,这里介绍三种典型涌现能力:
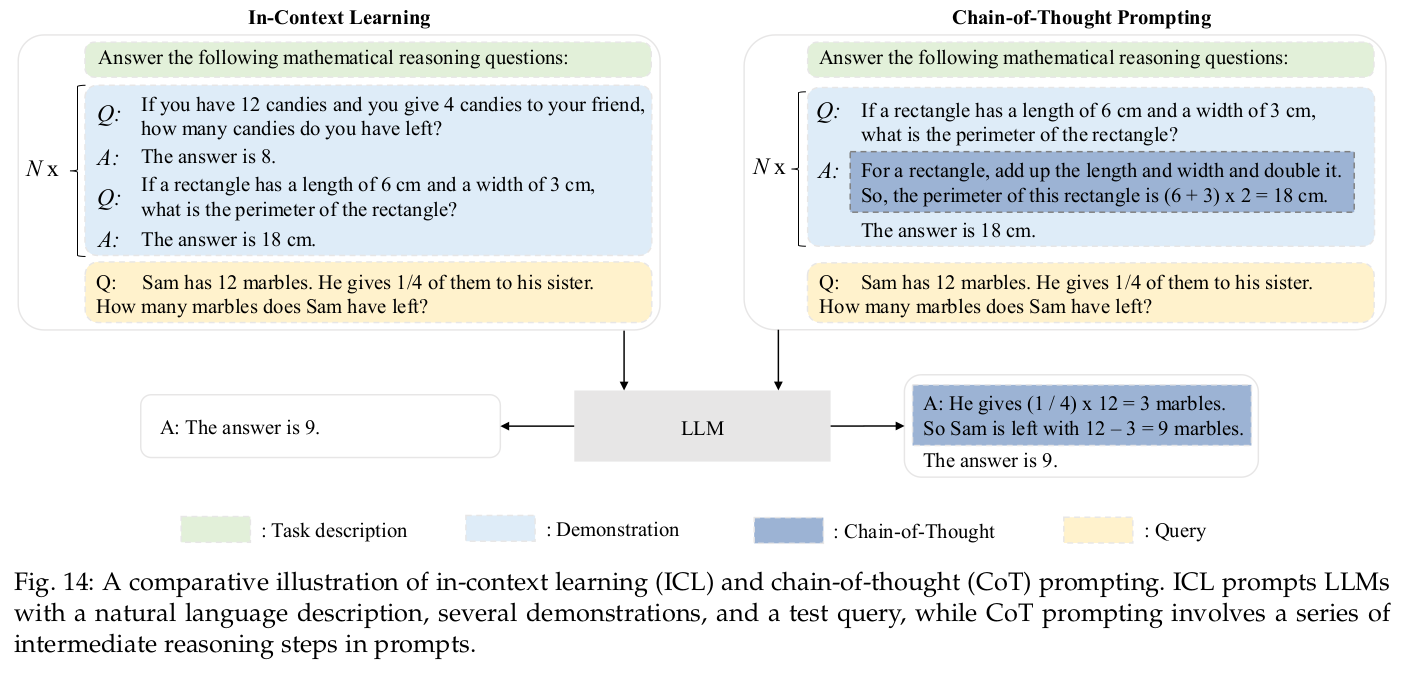
1. In-context learning(上下文学习)
ICL能力是由GPT-3正式引入的:假设已经为语言模型提供了一个自然语言指令和/或几个任务演示,它可以通过完成输入文本的单词序列的方式来为测试实例生成预期的输出,而无需额外的训练或梯度更新。
2. Instruction following(指令遵循)
- 通过使用自然语言描述的混合多任务数据集进行微调(称为指令微调),
LLM在未见过的以指令形式描述的任务上表现出色。
3. Step-by-step reasoning:(逐步推理)
- 通过使用思维链(
Chain-of-Thought, CoT)提示策略,LLM可以通过利用包含中间推理步骤的提示机制来解决这类任务,从而得出最终答案。
2.2 大语言模型的关键技术
LLM 的关键技术主要分为以下五个方面:
1. Scaling(扩展)
Transformer语言模型存在明显的扩展效应,更大的模型/更大的数据规模/更多的训练计算通常会导致模型能力的提升。
2. Training(训练)
- 分布式训练算法是学习
LLM网络参数所必需的,其中通常联合使用各种并行策略。 - 为了支持分布式训练,已经发布了一些优化框架来促进并行算法的实现和部署,例如
DeepSpeed和Megatron-LM。 - 此外,优化技巧对于训练稳定性和模型性能也很重要,例如预训练以克服训练损失激增和混合精度训练等。
3. Ability eliciting(能力引导)
- 在大规模语料库上预训练之后,
LLM具备了作为通用任务求解器的潜在能力。 - 然而,当
LLM执行一些特定任务时,这些能力可能不会显式地展示出来。 - 作为技术手段,设计合适的任务指令或具体的
ICL策略可以激发这些能力。
4. Alignment tuning(对齐微调)
InstructGPT设计了一种有效的微调方法,使LLM能够按照期望的指令进行操作,其中利用了 基于人类反馈的强化学习技术(RLHF),采用精心设计的标注策略,它将人类反馈纳入训练循环中。
5. Tools manipulation(操作工具)
- 利用外部工具可以进一步扩展
LLM的能力。例如,LLM可以利用计算器进行准确计算,利用搜索引擎检索未知信息,这种机制可以广泛扩展LLM的能力范围。
2.3 GPT 系列模型的演进
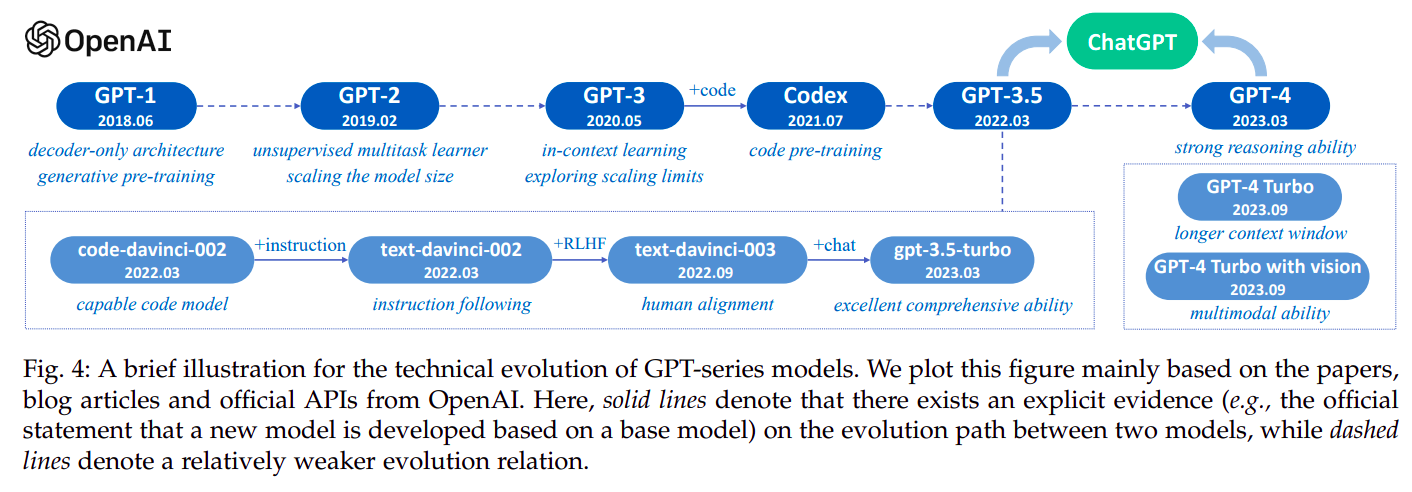
1. GPT-1: 2018 年
2018年,OpenAI发布了GPT-1,代表生成式预训练(Generative Pre-Training)。GPT-1是基于生成型的、仅含有解码器的Transformer架构开发的,并采用了无监督预训练和有监督微调的混合方法。GPT-1为GPT系列模型建立了核心架构,并确立了对自然语言文本进行建模的基本原则,即预测下一个单词。
2. GPT-2: 2019 年
- 将参数规模增加到了
15亿,并使用大规模的网页数据集WebText进行训练。 - 它旨在通过无监督语言建模来执行任务,而无需使用标记数据进行显式微调。
- 尽管
GPT-2旨在成为一个无监督的多任务学习器,但与监督微调的SOTA方法相比,其整体性能仍然较差。
3. GPT-3: 2020 年
- 参数规模增加到了
175亿,引入了ICL的概念,它是以小样本或零样本的方式使用LLM。ICL可以指导LLM理解以自然语言文本的形式给出的任务。 GPT-3不仅在各种NLP任务中表现出色,而且在一些需要推理或领域适配能力的特殊设计的任务中也表现出色。GPT-3可以被视 为从PLM到LLM进化过程中的一个重要里程碑。它通过实证证明,将神经网络扩展到大的规模可以大幅增加模型的能力。OpenAI为了提高GPT-3的性能,使用了两种策略:- 使用代码数据进行训练:
- 原始的
GPT-3模型(在纯文本上进行预训练)的一个主要限制在于缺乏复杂任务的推理能力,例如完成代码和解决数学问题。 OpenAI在2021.07推出了Codex,这是一个在大量GitHub代码上微调的GPT模型,Codex可以解决非常困难的编程问题,并且在数学问题上有显著的性能提升。- 实际上,
GPT-3.5模型是在基于代码的GPT模型(code-davinci-002)的基础上开发的。
- 原始的
- 与人类对齐:
InstructGPT在2022.01提出,以改进GPT-3模型与人类对齐能力,正式建立了一个三阶段的基于人类反馈的强化学习(RLHF)算法。- 除了提高指令遵循能力之外,
RLHF算法对于缓解有害或有毒内容的生成问题十分有效,这对于LLM在实践中的安全部署至关重要。 OpenAI在对齐研究中的方法,总结了三个有前途的方向:- 使用人类反馈训练
AI系统 - 协助人类评估
- 做对齐研究
- 使用人类反馈训练
- 使用代码数据进行训练:
4. ChatGPT: 2022 年
- 它是以类似
InstructGPT的方式进行训练的(在原始文章中称为“InstructGPT 的姊妹模型”),但专门针对对话能力进行了优化。 ChatGPT训练数据是通过将人类生成的对话(扮演用户和AI两个角色)与InstructGPT数据集结合起来以对话形式生成。ChatGPT在与人类的交流中表现出卓越的能力:- 拥有丰富的知识库
- 擅长解决数学问题
- 准确追踪多轮对话中的上下文
- 与人类的价值观保持一致以确保被安全使用
ChatGPT支持了插件机制,进一步通过已有工具或应用扩展了ChatGPT的功能。
5. GPT-4: 2023 年
- 将文本输入扩展到多模态信号,性能有大幅提升。
GPT-4对于具有恶意或挑衅的提问的响应更加安全,并采用了多种干预策略来减轻语言模型的可能问题,如幻觉、隐私和过度依赖。
3. 大语言模型公开可用资源
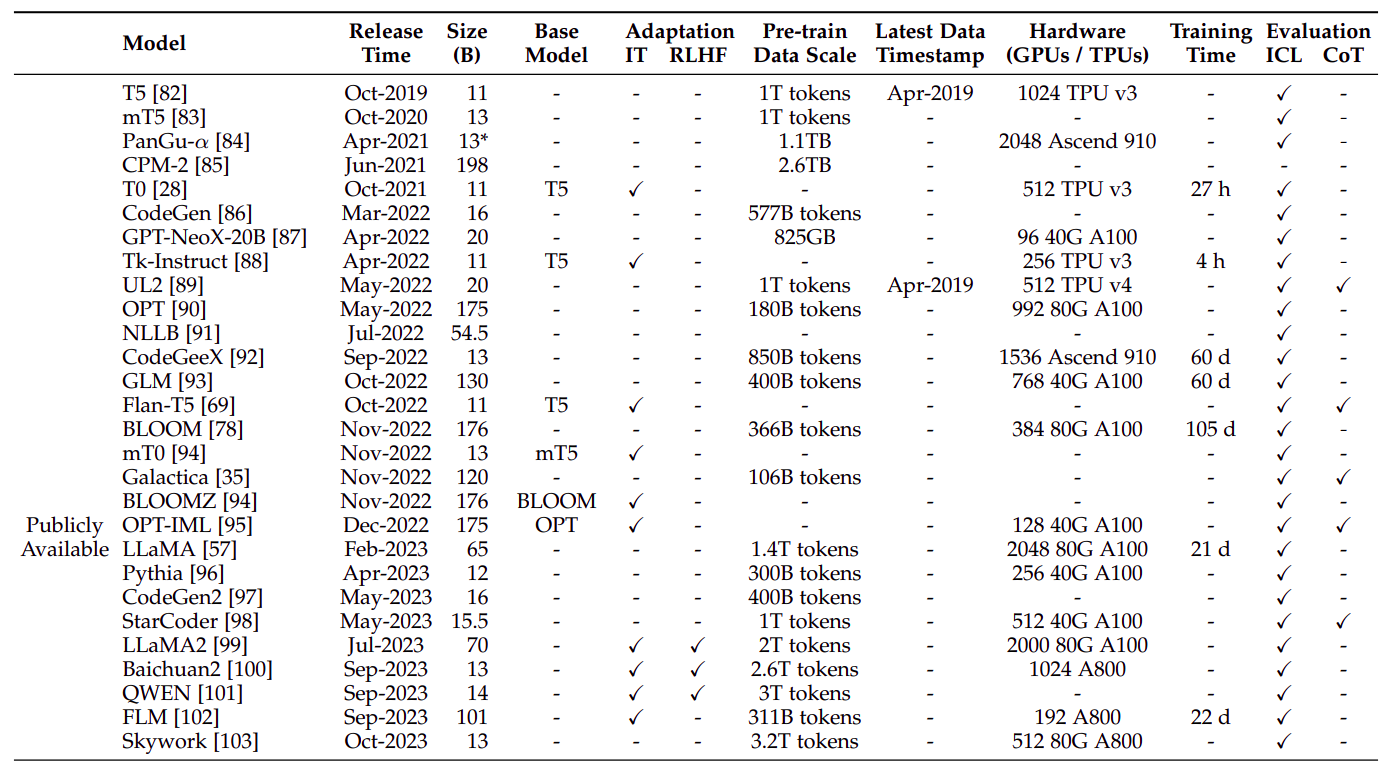
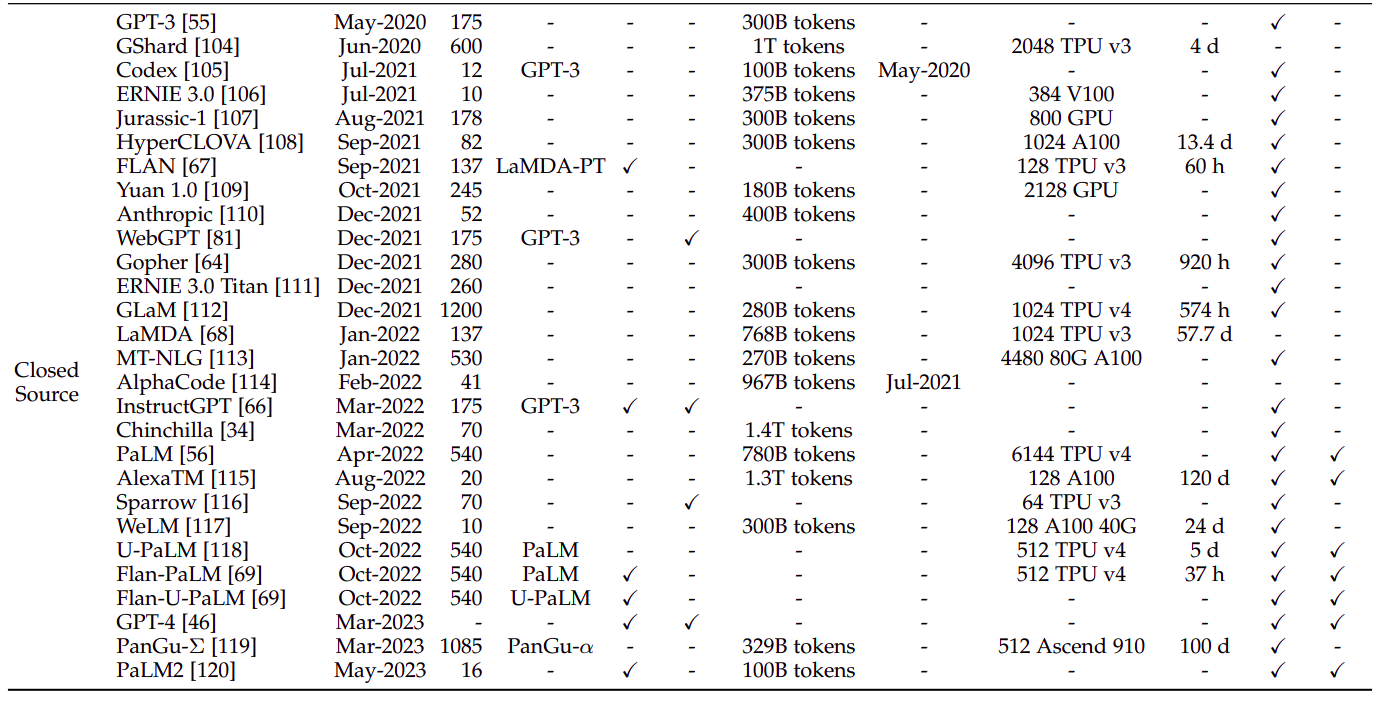
3.1 公开可用的模型检查点或 API

3.2 常用预训练语料库
常用的用于预训练的语料库有:
1. Books
BookCorpus是之前小规模模型(如GPT和GPT-2)中常用的预训练数据集,包含超过11,000本电子书,涵盖广泛的主题和类型(如小说和传记)。Gutenberg是更大的数据语料库,包含超过70,000本文学作品,包括小说、散文、诗歌、戏剧、历史、科学、哲学和其他公共领域的作品。- 在
GPT-3中使用到的Books1和Books2是比Gutenberg大的多的语料库,但并未开源。
2. CommonCrawl
CommonCrawl是最大的开源网络爬虫数据库之一,能力达到了百万亿字节级别,已经被广泛运用于训练LLM。- 由于网络数据中存在大量的噪音和低质量信息,因此使用前需要进行数据预处理。目前有四个较为常用的基于
CommonCrawl的过滤数据集:- C4
- CC-Stories
- CC-News
- RealNews
3. Reddit Link
Reddit是一个社交媒体平台,用户可以在上 面提交链接和帖子,其他人可以通过“赞同”或“反对”投票。高赞的帖子通常被认为对多数用户是有帮助的,可以用来创建高质量的数据集。WebText就是一个著名的基于Reddit的 语料库,它由Reddit上高赞的链接组成,但尚未公开。- 作为替代,有一个易于获取的开源替代品叫做
OpenWebText。 - 另一个从
Reddit中提取的语料库是PushShift.io.
4. Wikipedia
Wikipedia是一个在线百科全书,包含大量高质量的文章,涵盖各种主题。其中大部分文章都采用解释性写作风格(并支持引用),覆盖了多种不同语言和广泛的知识领域。
5. Code
- 为了收集代码数据,现有工作主要是从互联网上爬取有开源许可证的代码。代码数据有两个主要来源:
- 包括开源许可证的公共代码库(例如
GitHub) - 与代码相关的问答平台(例如
StackOverflow)
- 包括开源许可证的公共代码库(例如
Google公开发布了BigQuery数据集,其中包括各种编程语言的大量开源许可证代码片段, 是一个典型的代码数据集。
6. Other
The Pile是一个大规模、多样化、开源的文本数据集,有超过800GB数据,内容包括书籍、网站、代码、科学论文和社交媒体平台等。它由22个多样化的高质量子集构成。ROOTS由各种较小的数据集(完全为1.61 TB的文本)组成,涵盖了59种不同的语言(包含自然语言和传统语言)。
7. 一些经典模型使用的预训练语料库
GPT-3(175B)是在混合数据集(共3000亿token)上进行训练的,包括:CommonCrawlWebText2Books1Books2Wikipedia
PaLM(540B)使用了共包含7800亿token的数据集,包括:- 社交媒体对话
- 过滤后的网页
- 书籍
Github- 多语言维基百科
- 新闻
LLaMA使用了更多的数据预训练,其中LLaMA(6B)和LLaMA(13B)的训练数据大小为1.0万亿token,而LLaMA(32B)和LLaMA(65B)使用了1.4万亿token,包括:CommonCrawlC4GithubWikipedia- 书籍
ArXivStackExchange
3.3 常用 Fine-tuning 语料库
1. instrction tuning (指令微调) 常用数据集
instrction tuning (指令微调) 过程可将预训练好的多任务模型在 Zero-shot 任务上表现更好。
NLP task datasetP3 (Public Pool of Prompts)- 一个涵盖各种自然语言处理任务的
Prompted英文数据集集合,Prompt是输入模板和目标模板的组合。 - 模板是将数据示例映射到自然语言输入和目标序列的函数。例如,在自然语言推理(
NLI)数据集的情况下,数据示例将包括Premise(前提)、Hypothesis(假设)和Label(标签) 字段。 - 输入模板可以定义为:“如果
{Premise}为真,则{Hypothesis}也为真吗?”,而目标模板可以定义为:选择的选项为Choices[label]。这里的Choices是特定于Prompt的元数据,包含对应于标签为包含(0)、中性(1)或矛盾(2)的选项yes、maybe、no。
- 一个涵盖各种自然语言处理任务的
FLAN使用的instrction tunning数据集FLAN实际上是google的 《Finetuned Language Models Are Zero-Shot Learners》提出的模型,该模型用了大量的自然语言理解(NLU)和自然语言生成(NLG)任务数据集做指令微调。
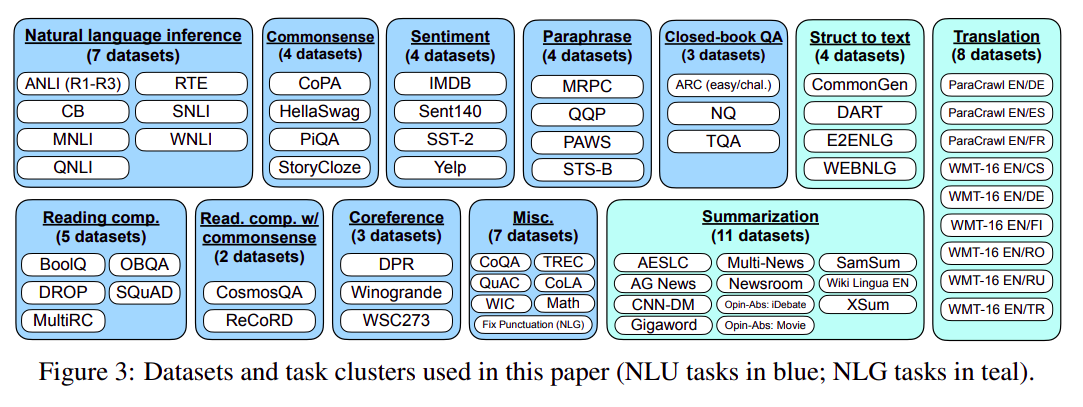
- 指令微调后的模型在
Zero-shot任务上表现更好。
Daily chat datasetShareGPT:由用户资源上传的和ChatGPT或GPT4的对话,总量大约90,000组对话。OpenAssistant:多语言的人类和AI助手的对话,包含35种语言,66,497组对话和461,292个人类标注。Dolly:由Databricks公司制作的15,000条英文人类对话,包含7大子类:- 头脑风暴
- 内容生成
- 信息提取
- 摘要
- 分类
- 开卷考试的质量保证 (
closed-book quality assurance) - 闭卷考试的质量保证 (
open-book quality assurance)
- 合成数据
Self-Instruct-52K:一个由Self-Instruct框架生成的指令遵循数据集,共82,000个实例包含约52,000条指令。Alpaca:一个用于训练和评估指令遵循型语言模型的集合,它包含了52,000条独特的指令和相应的输出,这些数据是基于OpenAI的text-davinci-003模型自动生成的。Baize:是一个开源的多轮对话数据集,它通过让ChatGPT自我对话生成,旨在为训练和评估对话模型提供高质量的语料资源。对话全部为英文,共包含111.5K个实例。
2. Alignment(对齐) 常用数据集
Alignment(对齐)过程的目的是让 LLM 对齐人类的价值观和偏好。Alignment 数据集需要是高质量的、有帮助的、诚实的、无害的。
HH-RLHF:是由 Anthropic 公司收集的,用于训练和评估强化学习中的偏好(或奖励)模型的数据集,包含约169K实例。这个数据集包含两部分:- 有益和无害性的人类偏好数据
- 红队对抗数据
SHP:包含385,000条人类偏好的数据集,这些偏好是对18个不同主题领域中问题/指令的回答进行的。PKU-SafeRLHF:由北京大学团队开发的,用于支持和推动安全强化学习(RLHF)技术的研究和发展的数据集。这个数据集是目前为止最大的多轮RLHF数据集之一,规模达到100万条,包含了一系列安全偏好的标注,这些标注覆盖了侮辱、歧视、犯罪、心理伤害、悲观情绪、色情、隐私等多种维度,用于对RLHF技术进行细粒度的约束价值对齐。Stack Exchange Preferences:是一个从Stack Overflow数据转储中提取的问答对数据集,它被设计用于偏好学习(preference learning)。这个数据集包含了大量的问题和答案,其中答案基于得票数进行了评分。数据集的大小超过了20GB,并且包含了数百万条问题和答案对。Sandbox Alignment Data是一个由大型语言模型(LLM)生成的对齐数据集,包含约169K个实例,它包含了来自模拟社交互动环境SANDBOX的反馈。在SANDBOX中,模型模拟了人类社会中的交互,通过这种方式生成的对话数据被用来训练和评估语言模型,使其更好地符合人类的价值观和社交规范。
3.4 常用代码库资源
1. Transformers
- 一个使用
Transformer架构构建模型的开源Python库,由Hugging Face开发和维护。它具有简单和用户友好的API,方便使用和定制各种预训练模型。
2. DeepSpeed
- 由
Microsoft开发的深度学习优化库(与PyTorch兼容),已用于训练多个LLM,例如MTNLG和BLOOM。它提供了各种分布式训练优化技术的支持,例如内存优化(ZeRO技术、梯度检查点)和管道并行。
3. Megatron-LM
- 由
NVIDIA开发的深度学习库,用于训练LLM。它提供了丰富的分布式训练优化技术,包括模型和数据并行、混合精度训练和FlashAttention。这些优化技术可以大大提高训练效率和速度,并实现GPU间的高效分布式训练。
4. JAX
- 由
Google开发的用于高性能机器学习算法的Python库,允许用户在带有硬件加速(例如GPU或TPU)的情况下进行数组的高效运算。它可以在各种设备上进行高效计算,还支持自动微分和即时编译等特色功能。
5. Colossal-AI
- 由
HPC-AI Tech开发的用于训练大规模人工智能模型的深度学习库。它基于PyTorch实现,并支持丰富的并行训练策略。
6. BMTrain
- 由
OpenBMB开发的用于以分布式方式训练大规模参数模型的高效库,强调代码简洁、低资源占用和高可用性。
7. FastMoE
- 一种专门用于
MoE(即混合专家)模型的训练库。
8. vLLM
- 一个快速、内存高效、易用的
LLM代码库,用于LLM的推理和服务。
9. DeepSpeed-MII
DeepSpeed Model Implementations for Inference,一个比vLLM更快的模型推理服务框架。
10. DeepSpeed-Chat
- 基于
DeepSpeed的一键式训练RLHF,提速15倍。
4. 预训练
预训练为 LLM 的语言理解和生成能力奠定了基础。
4.1 数据收集和处理
1. 数据来源
- 通用文本数据
WebpagesConversation textBooks
- 专用文本数据
- 多语言文本
- 科学文本
- 代码
2. 数据处理
一个好用的数据处理代码库是 Data-Juicer
- 质量过滤
为删除语料库中的低质量数据,通过有两种方式:基于分类器的方法 和 基于启发式的方法- 基于分类器的方法
- 通常采用高质量文本(例如
wikipedia)作为正样本,候选文本作为负样本,训练二分类器,用于给出一个文本的质量分数。 - 预计分类器的质量过滤方法可能会 无意识的删除口语化、方言、社会语言的文本。
- 通常采用高质量文本(例如
- 基于启发式的方法
启发式方法通常采用一系列预设的规则来过滤低质量文本,具体的方法有:- 基于语言的过滤:例如删除小语种文本等。
- 基于度量的过滤:例如基于困惑度(
perplexity)来检测和删除不自然的文本。 - 基于统计的过滤:例如根据标点符号的分布、符号和单词的比例等删除。
- 基于关键词的过滤:例如删除
HTML标签、超链接、模板等。
- 基于分类器的方法
- 数据去重
- 现有研究表明,重复数据会降低语料库的多样性,可能导致训练过程不稳定,从而影响模型性能。
- 三种粒度的数据去重:
- 句子级
- 文档级
- 数据集级
- 隐私去除
- 预训练数据大多来自网络,可能包含敏感隐私信息,存在隐私泄露风险。因此需要从数据集中删除
personally identifiable information(可识别个人信息,PII)。 - 一种有效的删除方法是通过规则(例如:关键字识别)来检测和删除可识别各人信息(例如:姓名、电话、地址等)。
- 现有研究表明,
LLM在隐私攻击下的脆弱性可能归因于预训练数据中存在重复的可识别个人信息。
- 预训练数据大多来自网络,可能包含敏感隐私信息,存在隐私泄露风险。因此需要从数据集中删除
- 分词(
Tokenization)
分词也是数据预处理的关键步骤,它的目的是将原始文本分割成词序列,随后用作LLM的输入。常用的分词方式有以下三种:BPE (Byte-Pair Encoding tokenization)字节对编码,计算过程如下:- 首先将文本拆分成字母和分隔符,并统计每个字母或分隔符出现的频率。
- 计算任意两个字母/分隔符合并后出现的频率,找到最高频的字母/分隔符对合并,重新统计词频并更新词表。
- 重复第二步,直到词表大小满足要求。
- 特点:
- 简单高效
- 贪心算法,每一步都选择频数最大的相邻字符进行合并,这种做法可能不一定是全局最优、频数也不一定是最好的合并指标。
- 适合拉丁字母组成的语言,不适合汉字、日韩文字等。
WordPiece tokenization,计算过程如下:- 首先将文本拆分成字母和分隔符。
- 不同于
BPE选择合并后词频最大的词作为Subword,WordPiece基于语言模型似然概率的最大值生成新的Subword,具体的基于语言模型似然概率的定义如下:- ,句子
S由n个子词组成。 - 则句子
S的似然概率定义为: - 其中
P()表示一个训练好的语言概率模型。
- ,句子
- 找到合并后可以使得句子的似然概率最大的子词合并,更新词表,重复这个过程。
Unigram LM,计算过程如下:Unigram和BPE以及WordPiece有个很大的不同是:BPE和WordPiece都是初始化小词表逐步变大直到满足词表大小要求。Unigram LM是初始化大词表逐步删词直到满足词表大小要求。
Unigram LM删词的根据和WordPiece一致,都是基于语言模型似然概率
3. 预训练数据对大语言模型的影响
与小规模的 PLM 不同,由于对计算资源的巨大需求,通常不可能对 LLM 进行多次预训练迭代。因此,在训练 LLM 之前构建一个准备充分的预训练语料库尤为重要。
目前,不同的 LLM 模型预训练采用不同的预训练策略,下图是一些模型的预训练数据分布图:
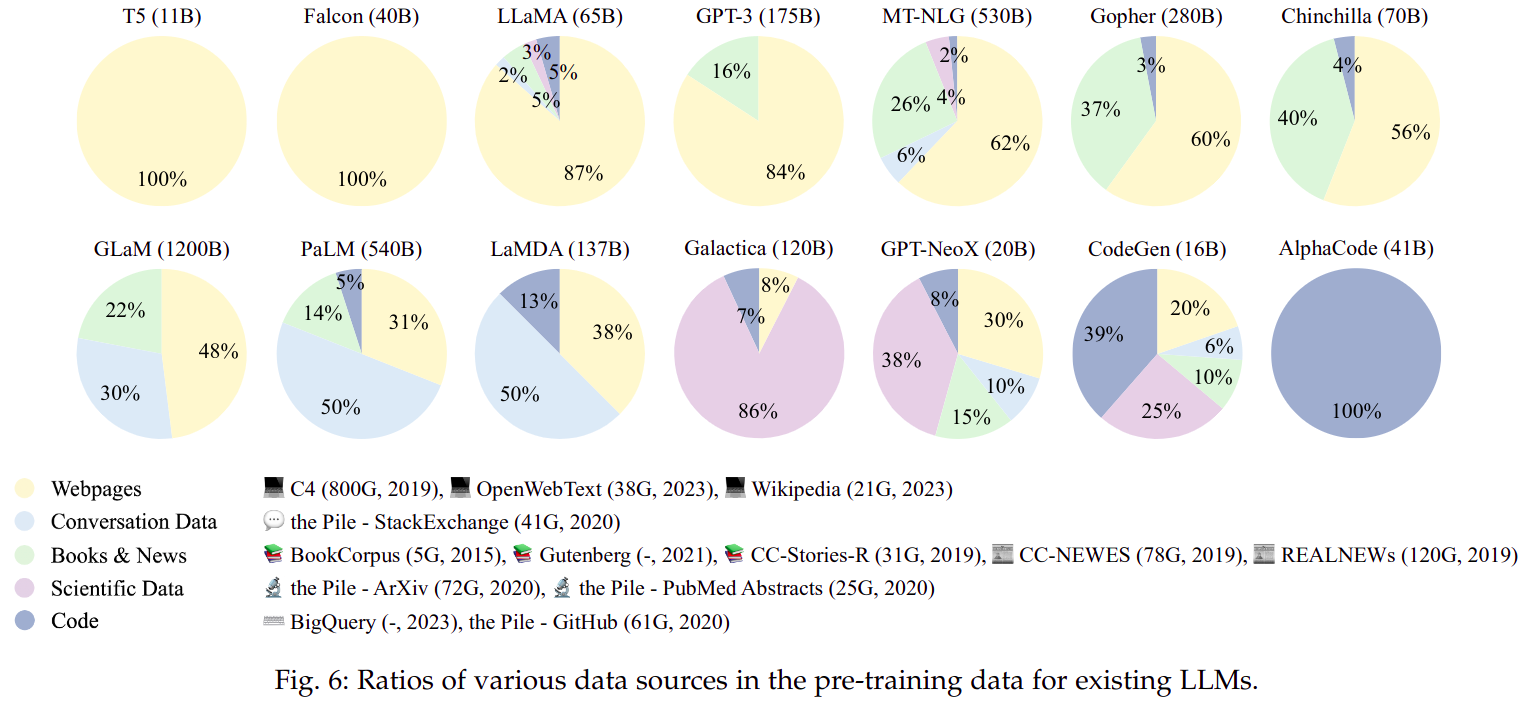
不过,存在几个有效的混合策略:
- 增加数据的多样性(
diversity)
预训练阶段,数据的多样性比数据的质量更重要,有实验表明,删除语料库中的多样性数据(例如:Webpages)比删除语料库中的高质量数据(例如:学术语料库)对模型的影响更大。 - 可以通过数据混合实验优化数据混合策略
- 在大模型上做数据混合实验是非常昂贵且耗时的,通过会在小模型上测试不同的数据混合策略的优劣,再将小模型测试得到的结果用在大模型上。
- 但小模型得到的数据混合策略结论在大模型上可能是不成立的,越大的小模型得出来结论越可信。
- 先用
general数据训练模型通用能力,再用skill-spcific数据训练模型专业能力- 不同的数据训练的模型有不同的能力,比如:
- 用代码训练的模型对数学和编程更擅长。
- 用书籍训练的模型更擅长从文本中捕捉长期依赖。
- 先训练
basic skill再训练target skill比直接训练target skill模型表现更好
- 不同的数据训练的模型有不同的能力,比如:
4.2 架构设计
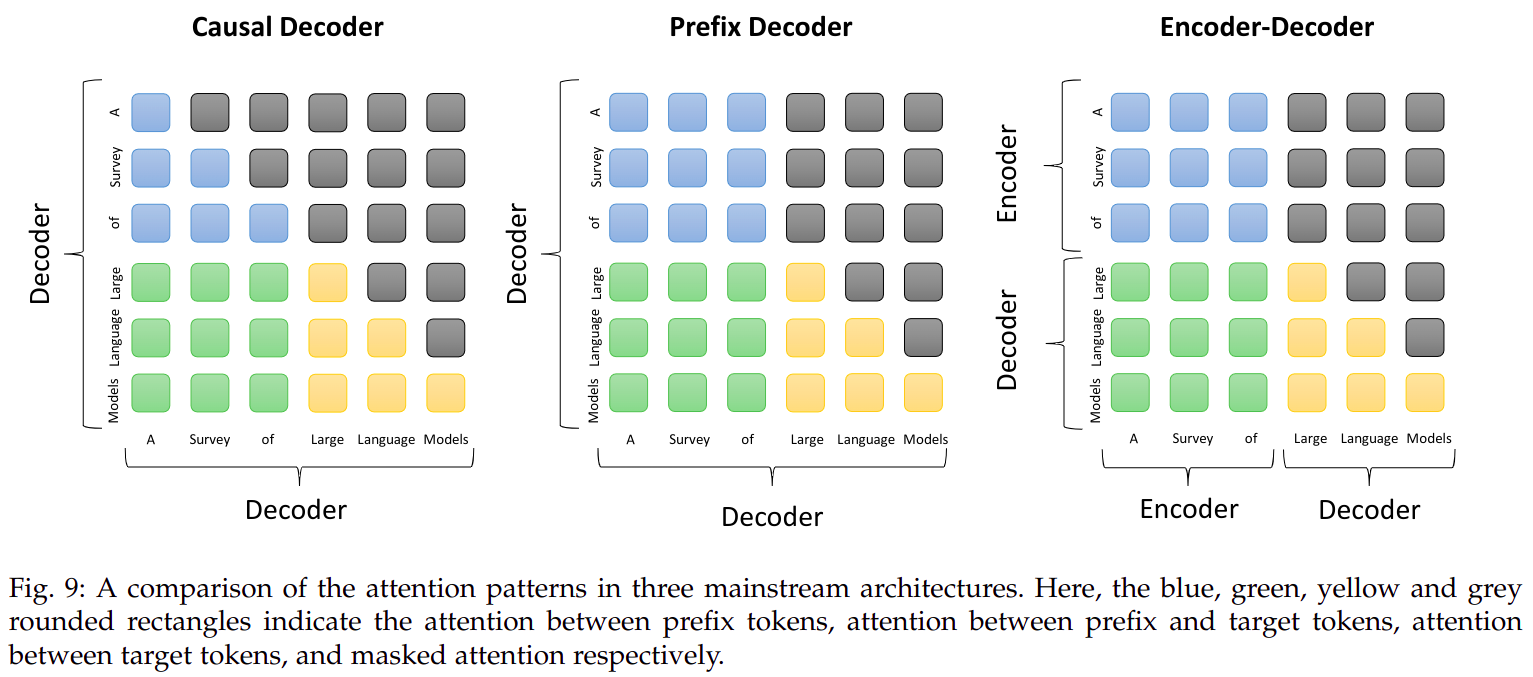
1. 典型结构
Casual Decoder结构- 参考
GPT博客 中的Hello, world!续写例子
- 参考
Encoder-Decoder结构- 参考
T5博客 中的Hello, world!英语翻译法语的例子
- 参考
Prefix Decoder结构- 是对
Encoder-Decoder和Casual Decoder的折中,在prefix前缀文本中使用双向注意力,在生成后续序列时使用单向注意力 - 用到
Prefix Decoder的模型有:U-PaLMGLM等
- 是对
Mixture-of-Experts(混合专家)结构- 优势:是一种灵活的模型参数扩展方法;性能提高明显;
- 劣势:由于路由操作复杂等原因,训练容易不稳定;
- 传言
GPT-4使用了MOE结构
Emergent Architectures(新兴结构)
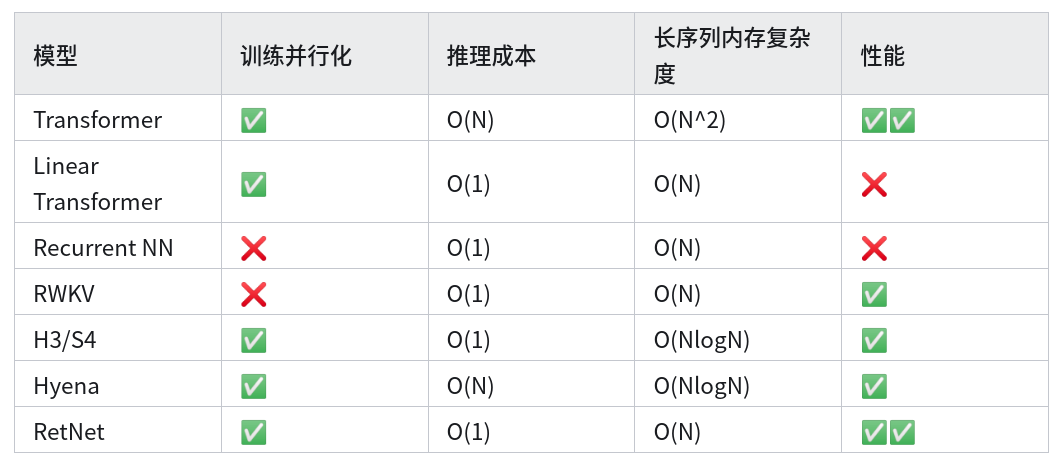
- 现有架构存在的问题:
Transformer架构一个很大的问题是推理时复杂度较高,每一个token需要计算和之前的每一个token计算相关性- 相比之下,
RNN架构推理的复杂度就很低,每一个token只需要和上一个token以及一个不断更新的hidden state计算相关性(本质是hidden state在某种程度上存储了之前所有token的信息) - 但
RNN数据依赖问题非常强,导致训练难以并行化,且通常效果较差
- 一些新兴架构包括:
H3/S4RWKVHyenaMambaRetNet
- 这些新兴架构几乎无一例外的想做同一件事:像
Transformer一样可以并行训练 + 像RNN一样高效推理,且效果可以和Transformer媲美 - 状态空间模型
SSM论文HiPPO可参考 这篇论文
- 现有架构存在的问题:
2. 配置细节

- 归一化方法
- LayerNorm
LayerNorm和BatchNorm只有两个差别,为了简化,假设Channel = 1即feature shape = N, 1, H, W:- 训练时差别:
BatchNorm统计整个feature map的均值和标准差(scalar),然后在整个feature map做标准正态化;同时记录(滑动平均算法)到running_mean / running_var参数中LayerNorm统计每一个样本的均值和标准差(均值和标准差都是长度为N的vector),然后每个样本逐个做标准正态化;均值标准差用完即扔,无需记录
- 推理时差别:
BatchNorm推理时不需要计算feature的均值和标准差,而是使用训练统计得到的running_mean / running_var,因此是个静态行为,可以被前面的Conv2d运算吸收LayerNorm推理阶段和训练阶段运算方式基本一致
- 训练时差别:
- RMSNorm
- 假设输入
shape为N, C, L分别表示batch / feature_dim / seq_length
- 其中,
k / b都是可学习的per channel向量 - 和
LayerNorm相比RMSNorm有如下优势:- 更小的计算开销:
RMSNorm不需要计算输入数据的均值,因此减少了计算量,使得模型训练更加高效。 - 训练速度更快:由于减少了计算量,
RMSNorm在训练过程中的速度通常比LayerNorm更快。 - 性能相当或更好:尽管
RMSNorm的计算更简单,但它在保持与LayerNorm相当性能的同时,甚至可能在某些情况下提供更好的性能。 - 保留重要的不变性:
RMSNorm保留了输入数据的均方根比例不变性,这有助于模型在面对不同尺度的输入数据时保持一致的性能。 - 隐式学习率适应:
RMSNorm通过归一化输入数据的RMS,为模型提供了一种隐式的学习率适应能力,有助于模型在训练过程中更好地调整参数。
- 更小的计算开销:
- 假设输入
- DeepNorm
DeepNorm可以看做是一种增强型LayerNorm,对LayerNorm改动较小,但效果惊人,DeepNorm用在Post-LN架构上替代传统LayerNorm运算,可稳定训练,可训练深度超过 1,000 层的TransformerDeepNorm对LayerNorm的改动如下:
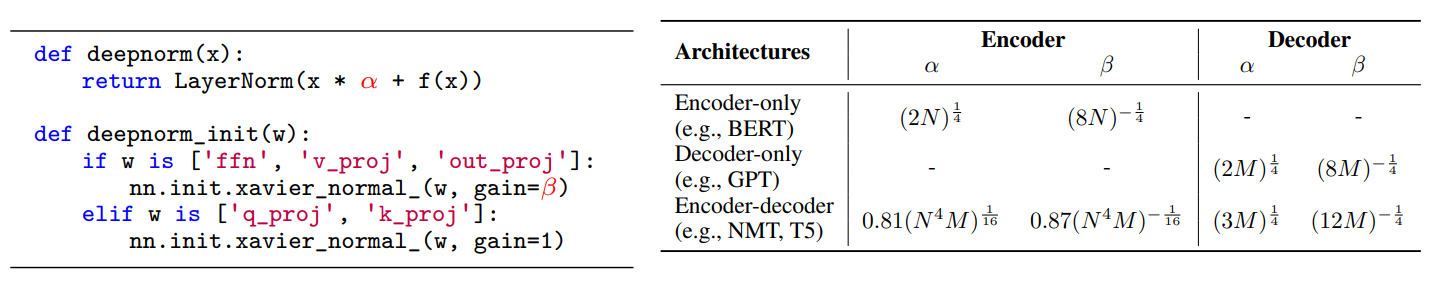
- LayerNorm
- 归一化位置
- Pre-LN
Pre-LN是一种Transformer架构,计算公式是:
- Post-LN
Post-LN是另外一种Transformer架构,计算公式是:
- Sandwich-LN
Sandwich-LN是Pre-LN的改进,公式为:
- Pre-LN
- 激活函数
- GeLU
- 其中
erf表示高斯误差函数,值域是[-1, 1] GeLU是LLM中使用最广泛的激活函数
- 其中
- Swish
- SwiGLU
- GeGLU
- GeLU
- 位置编码
- 绝对位置编码
- 用在传统
Transformer上,有两种:- 位置编码(
position encoding):使用正弦得到位置编码
- 其中
- 分别表示位置 对应的位置编码向量的第 位置的值
- 表示第 个位置
- 表示向量维度
- 其中
- 可学习位置编码(
position embedding):使用可学习的embedding编码:position_embedding = nn.Embedding(max_seq_length, d_model)
- 位置编码(
- 绝对位置编码
position embedding通常会element-wise加到输出token embedding作为Transformer输入,即:
表示token embedding, 表示position embedding
- 用在传统
- 相对位置编码
- 从计算方法来说,相对位置编码需要:
- 先构造相对位置矩阵:
- 可学习 的相对位置偏置表:
shape = [2 * n - 1, 2 * n - 1, num_head] = [5, 5, num_head]- 其中,坐标
[i, j, k]表示第k的self-attention头上 和 的相对位置
- 先构造相对位置矩阵:
- 从使用方法来说:
- 相对位置编码不再需要显式的将
position embedding加上token embedding作为Transformer输入 - 而是将相对位置编码加到
self-attention上,即- 表示 和 的
self-attention score - 表示 和 的相对位置
- 表示 和 的
- 因此也被称为
RelativePositionBias(相当于self-attention的bias)
- 相对位置编码不再需要显式的将
- 可以参考
ALiBi博客
- 从计算方法来说,相对位置编码需要:
- 旋转位置编码
RoPE- 是一种不可学习的
position encoding位置编码方式,编码本身是绝对位置编码,但通过self-attention之后,key和query会产生相对位置关系 - 计算过程:
- 首先以固定间隔角度计算旋转矩阵,矩阵中每个元素是复数形式,
shape = [max_seq_len, d_model] - 对计算
self-attention之前的key / query分别进行 旋转(本质是和旋转矩阵做复数乘法,然后再转换到实数空间),此步骤不改变key / query的shape - 然后做标准的
self-attention
- 首先以固定间隔角度计算旋转矩阵,矩阵中每个元素是复数形式,
- 是一种不可学习的
- 总结
- 绝对位置编码:
position embedding和token embedding的shape相同,作用在query / key / value生成之前 - 旋转位置编码:
position embedding和token embedding的shape相同,作用在self-attention之前,只作用在key / query上,不对value生效 - 相对位置编码:
position embedding和token embedding的shape不同,和attention map的shape相同,作用在self-attention生成的注意力矩阵上
- 绝对位置编码:
- 绝对位置编码
- Attention 方式
- full attention
- 就是标准的
self-attention,即
- 在
LLM语境下通常n >> d,softmax是非线性运算,所以需要先计算 ,这决定了full attention的计算复杂度为 ,因此full attention复杂度也被称为softmax计算复杂度 - 假如没有
softmax,那么 可以通过结合律先计算 ,然后再计算 ,计算复杂度退化为 ,变成了线性复杂度
- 就是标准的
- sparse attention
- 在标准
self-attention的基础上,提前生成一个固定的二值的sparse attention mask,将self-attention的计算复杂度变成 - 固定的二值的
sparse attention mask可以有多种形式,比如:
1
2
3
4
5
6
7
8
9
101, 0, 0, 0, 0, 0, 0, 0, 0, 0 | 1, 0, 0, 0, 0, 0, 0, 0, 0, 0
0, 1, 0, 0, 0, 0, 0, 0, 0, 0 | 1, 1, 0, 0, 0, 0, 0, 0, 0, 0
0, 0, 1, 0, 0, 0, 0, 0, 0, 0 | 1, 1, 1, 0, 0, 0, 0, 0, 0, 0
1, 0, 0, 1, 0, 0, 0, 0, 0, 0 | 0, 1, 1, 1, 0, 0, 0, 0, 0, 0
0, 1, 0, 0, 1, 0, 0, 0, 0, 0 | 0, 0, 1, 1, 1, 0, 0, 0, 0, 0
0, 0, 1, 0, 0, 1, 0, 0, 0, 0 | 0, 0, 0, 1, 1, 1, 0, 0, 0, 0
1, 0, 0, 1, 0, 0, 1, 0, 0, 0 | 0, 0, 0, 0, 1, 1, 1, 0, 0, 0
0, 1, 0, 0, 1, 0, 0, 1, 0, 0 | 0, 0, 0, 0, 0, 1, 1, 1, 0, 0
0, 0, 1, 0, 0, 1, 0, 0, 1, 0 | 0, 0, 0, 0, 0, 0, 1, 1, 1, 0
1, 0, 0, 1, 0, 0, 1, 0, 0, 1 | 0, 0, 0, 0, 0, 0, 0, 1, 1, 1 - 在标准
- Multi-query/grouped-query attention
- 简单来说,
MQA是将标准MHA中的key / value的Multi-Head Attention退化成Single-Head,query保持不变 GQA是将Multi-Head分组,每个组内是MQA- 具体可以参考 Multi-query attention 和 Grouped-query attention 两篇博客
- 简单来说,
- Flash attention
- 简单来说
Flash attention和Flash attention v2是标准self-attention的完全等价的高效实现,通过更合理的实现大幅降低了SRAM和HBW之间的IO量,从而大幅加速训练 / 推理速度 - 详细分析可参考 flash attention 和 flash attention v2 两篇博客
- 简单来说
- Paged attention
Paged attention的目的是解决生成式模型kv cache占用太多显存导致显存利用率低的问题,kv cache详细分析可参考 这篇博客Paged attention通过类似分页内存管理的方法管理kv cache显存,随着序列变长,动态分配显存,显存物理空间不连续,最多只浪费一页,极大提高了显存利用率,使得可以运行更大的batch size
- full attention
3. 预训练任务
- Language modeling(语言建模)
- 语言建模任务是给定一个序列 ,使得 此极大似然估计最大,其中
- 语言建模预训练任务是
LLM最常用的预训练任务,在很多下游任务上甚至无需fine-tuning
- Denoising Autoencoding(去噪自编码)
- 去噪自编码是在一个句子中随机替换
token为噪声,然后训练模型去恢复原始信息
- 去噪自编码是在一个句子中随机替换
- Mixture-of-Denoisers(混合降噪器)
MoD是出自Google UL2大模型,此大模型使用了MoD作为预训练任务,是前面提到的两种预训练任务的组合
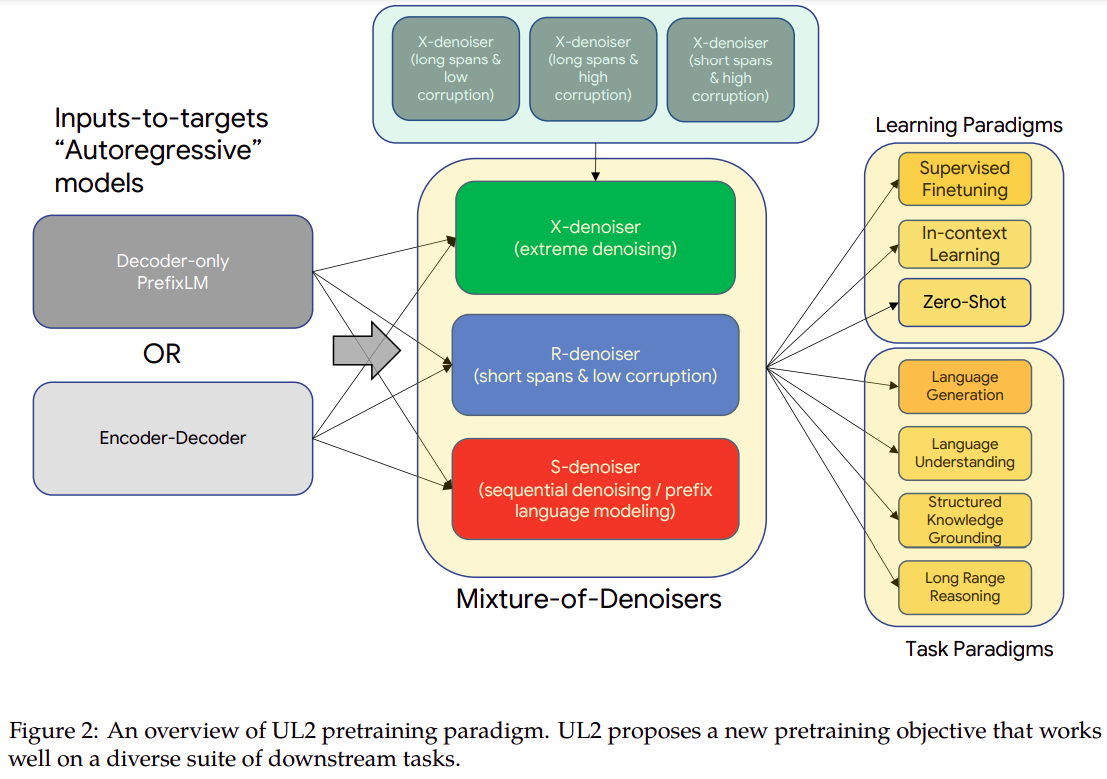
4. 长文本建模
长文本建模是指模型在推理阶段实际输入的序列长度比训练阶段更长,即 train short, test long,主要有两种范式:
- 扩展位置嵌入(
Scaling Position Embeddings)- 直接模型微调:通过多阶段逐步增加上下文长度来适应长文本。
- 位置插值:通过调整位置索引来扩展上下文窗口,相比直接模型微调更有效。
- 位置截断:截断超出预定义窗口长度的位置索引,保留局部位置关系。
- 基础修改:通过调整基础值来改变波长,以适应更长的文本。例如修改
RoPE的旋转角度间隔等。 - 基础截断:截断超出特定范围的基础值,避免在更大位置索引处出现分布外的旋转角度。
- 适应上下文窗口(Adapting Context Window)
- 并行上下文窗口:将输入文本分割成多个段,独立编码并修改注意力掩码以访问先前段的令牌。
- Λ 形上下文窗口:基于
LLMs倾向于更多关注起始和最近的令牌,采用选择性保留初始和最近令牌的注意力掩码。 - 外部记忆:存储过去的键(
keys)在外部记忆,并使用k-最近邻搜索方法检索最相关的令牌。
5. 解码策略
- 背景
- 对于绝大多数的文本生成任务,
language modeling解码策略就足够了,即预测下一个概率最大的词,这种解码策略也被称为Greedy search language modeling解码策略对于比如机器翻译、文本总结等任务是够用的,但是对于比如故事生成、对话等任务就有问题,会输出大量重复的、无意义的文本- 因此,一种简单有效的策略是根据输出的词表中每一个词的概率随机选择一个词(即从
argmax变成softmax),这种策略被称为Random sampling
- 对于绝大多数的文本生成任务,
Greedy search的改进Beam search:集束搜索可以缓解模型预测陷入局部最优解,beam size通常设置在3 ~ 6之间,太大会降低模型效果Length penalty:对于集束搜索的搜索空间进行长度惩罚,最终加权选择最优生成序列
Random sampling的改进
Random sampling是根据预测概率随机选,因此每个词都有可能被选中(即使概率很低),这可能会导致输出完全不合逻辑的文本序列,因此需要改进Temperature sampling- ,其中
t代表温度 - 是对
softmax得到概率分布的优化,加入了温度系数,可有效缓解随机采样导致的采样到不合理值的问题 - 当
t = 1时,退化为random sampling - 当
t趋近于0时,退化为greedy search
- ,其中
top-k sampling- 只保留可能性最高的
k种取值 - 概率重新归一化后根据概率随机选
- 只保留可能性最高的
top-p sampling(nucleus sampling)- 只保留累计概率不超过
p的最小集;也就是按照预测概率降序,保留累计概率小于p的样本 - 概率重新归一化后根据概率随机选
- 只保留累计概率不超过
contrastive search- 参考 这篇博客
- 道理上讲得通,但模型推理阶段计算量翻了一倍
typical sampling- 参考 这篇博客
top-p算法的升级版本
-
- 参考 这篇博客
- 算是一种动态自适应
top-p算法,参考了typical sampling
6. 解码效率
作为主流的 GPT-like LLM,解码(推理)可以分为两个阶段:
prefill stage- 预装填阶段,即将
input / prompt输入到模型中计算hidden state的阶段 - 此阶段的计算访存比比较高,以
A100 80GB GPU + LLaMA-13B为例,计算访存比为113.78(硬件理论最高效计算访存比为156)
- 预装填阶段,即将
incremental decoding stage- 增量解码阶段,即累加上一轮输出持续解码直到
<EOS>或max_length - 此阶段计算访存比比较低,以
A100 80GB GPU + LLaMA-13B为例,计算访存比为1.97
因此,通过优化解码效率主要是针对incremental decoding stage,对于增量解码阶段的优化主要有两个方向:
- 增量解码阶段,即累加上一轮输出持续解码直到
- 减少数据
IO- 这里的数据
IO是指HBM和SRAM之间 Flash Attention通过分块计算Attention,可大幅降低数据IO量Multi-Query Attention和Grouped-Query Attention通过共享/分组共享KV来减小IO
- 这里的数据
- 解码策略优化
7. 实际设置
T5- 默认使用贪心解码算法
- 对于翻译和总结任务,使用
beam size = 4的beam search,长度惩罚系数0.6
GPT-3- 对于所有任务,使用
beam size = 4的beam search,长度惩罚系数0.6
- 对于所有任务,使用
Alpaca- 对于开放式生成任务,使用随机解码,
top-k (k = 50)和top-p (p = 0.9)以及0.7的温度
- 对于开放式生成任务,使用随机解码,
LLaMA- 对于问答任务,使用贪心解码算法
- 对于代码生成任务,使用随机解码,温度设置为
0.1和0.8(分别为Pass@1和Pass@100)
Open-AI API- 支持多种解码方式:
greedy search:通过设置温度为0beam search:设置best_oftemperature sampling:设置temperaturenucleus sampling:设置top-p
- 支持多种控制重复度的方法:
- 设置
presence_penalty - 设置
frequency_penalty
- 设置
- 支持多种解码方式:
8. 架构选择
- 目前
causal decoder是主流的大模型架构,主要原因有两点:- 有证据表明,对于没有
fine-tuning的情况下,causal decoder表现比encoder decoder架构更好,即对于zero-shot / few-shot任务,causal decoder效果更好 scaling law在causal decoder中表现明显,对于encoder decoder的研究缺乏
- 有证据表明,对于没有
4.3 模型训练
1. 训练配置
Batch Training- 对于
Language model pre-training任务(例如bert等),通常用较大的batch size,例如2048 examples或者4M tokens,这样通常可以提高训练稳定性和吞吐量。 - 对于
LLM任务(例如GPT-3 / PaLM),引入了动态batch size的做法,GPT-3在训练过程中会将batch size从32K tokens逐步增加到3.2M tokens,动态batch size可提高LLM训练稳定性
- 对于
Learning RateLLM的训练通常采用warmup+decay的训练策略warmup过程通常占总训练step数量的0.1% - 0.5%,学习率逐步从0提高到最大值,最大值通常在5e-5 ~ 1e-4之间(GPT-3是6e-5)。decay过程通常使用cosine decay策略,在剩余的training step中逐步将learning rate降低到最大值的10%
Optimizer- 通常使用
Adam / AdamW / Adafactor优化器中的一种 - 对于
Adam / AdamW,超参数配置为 ,GPT-3就使用了这组配置。 Adafactor优化器相比Adam / AdamW,优点是训练过程更省显存,超参数配置为 ,k表示训练步数,PaLM / T5就使用了Adafactor优化器。
- 通常使用
- 训练稳定化
LLM训练不稳定是常见情况,可以会导致训练崩溃- 通常做法有:
weight decay 0.1gradient clipping to 1.0
- 损失函数尖峰(
loss spike)也会导致训练不稳定,通常做法有:- 模型回退到
loss spike出现之前最近一次checkpoint,且弃用导致loss spike的数据,PaLM / OPT使用了这种方法 GLM模型发现Embedding layer不正常梯度容易导致loss spike,因此缩小了embedding layer gradient
- 模型回退到
2. 可拓展性训练技术
LLM训练会有两个技术难题:训练吞吐量的增加 和 加载大模型到显存,解决方法包含以下几种(以下几种并不冲突,可以同时使用):3D ParallelismData parallelism- 主流框架都已有实现(例如
pytorch的ddp) - 划分数据到不同
GPU,每个GPU独立前向反向 - 每个
step中gradient都需要聚合一次,以确保每个GPU上参数更新保持一致
- 主流框架都已有实现(例如
Pipeline parallelismTensor parallelismTensor parallelism是把模型一层的参数切成多份,每份独立计算,因此也叫做Model parallelism。- 即
Pipeline parallelism是横向把模型切成几段,而Tensor parallelism是纵向把模型切成几段。 - 以 矩阵乘运算为例,
Tensor parallelism是将A纵向切分为 放到不同的GPU上独立运算,则 Tensor parallelism需要分析每个算子的数据依赖情况,比如矩阵乘的右矩阵可以按列划分,但不可以按行划分。- 目前一些开源框架都支持了
Tensor parallelism,例如Megatron-LM(可参考 这篇博客) 和Colossal-AI
ZeRO- 通过分片存储等方法降低冗余,
ZeRO-DP和ZeRO-R可参考 这篇博客 FSDP是PyTorch官方提出和实现的类似于ZeRO的算法,全称是Fully Sharded Data Parallel。
- 通过分片存储等方法降低冗余,
- 混合精度训练
Format Bits Exponent Fraction FP32 32 8 23 FP16 16 5 10 BF16 16 8 7 FP16和FP32混合训练是比较常见的操作,但最近有研究发现FP16会造成模型精度降低。BF16是为了解决FP16造成精度降低而提出的数据类型,全称是Brain Floating Point,这种数据类型牺牲了表达精度,提高了表达范围。
- 总体训练建议
3D Parallelism- 在实际应用中,
3D Parallelism通常是联合使用的,例如BLOOM模型,是用了:4路Tensor Parallelism8路Data Parallelism12路Pipeline Parallelism
共384 (384=4 x 8 x 12)块A100 GPU训练得到的。
DeepSpeed、Colossal-AI、Alpa等开源库都对三种并行支持较好
- 在实际应用中,
- 减小显存占用
ZeRO和FSDP等算法可有效降低大模型训练过程中的显存占用,从而可以训练参数量非常大的模型。DeepSpeed、PyTroch、Megatron-LM等开源库都已集成此功能。
predictable scalingGPT-4提出的,在小模型上等效预测放大后模型的效果,对超大规模网络训练来说必不可少。
5. LLM 的适配微调
- 大模型在预训练结束之后,需要适配微调来使得大模型释放全部能力以及对齐人类的三观,主要的微调方式有两种:
Instruction Tuning(指令微调):用来提高或解锁大模型在某些方面的能力。Alignment Tuning(对齐微调):对齐人类三观。
5.1 Instruction Tuning 指令微调
Instruction Tuning可以大幅提高LLM的指令遵循能力,即让LLM可以解决具体的任务(指令)Instruction Tuning通常需要两步:- 收集指令数据:通常是构造结构化数据
- 使用收集到的指令数据用监督学习的方法微调
LLM
1. 格式化实例的构造
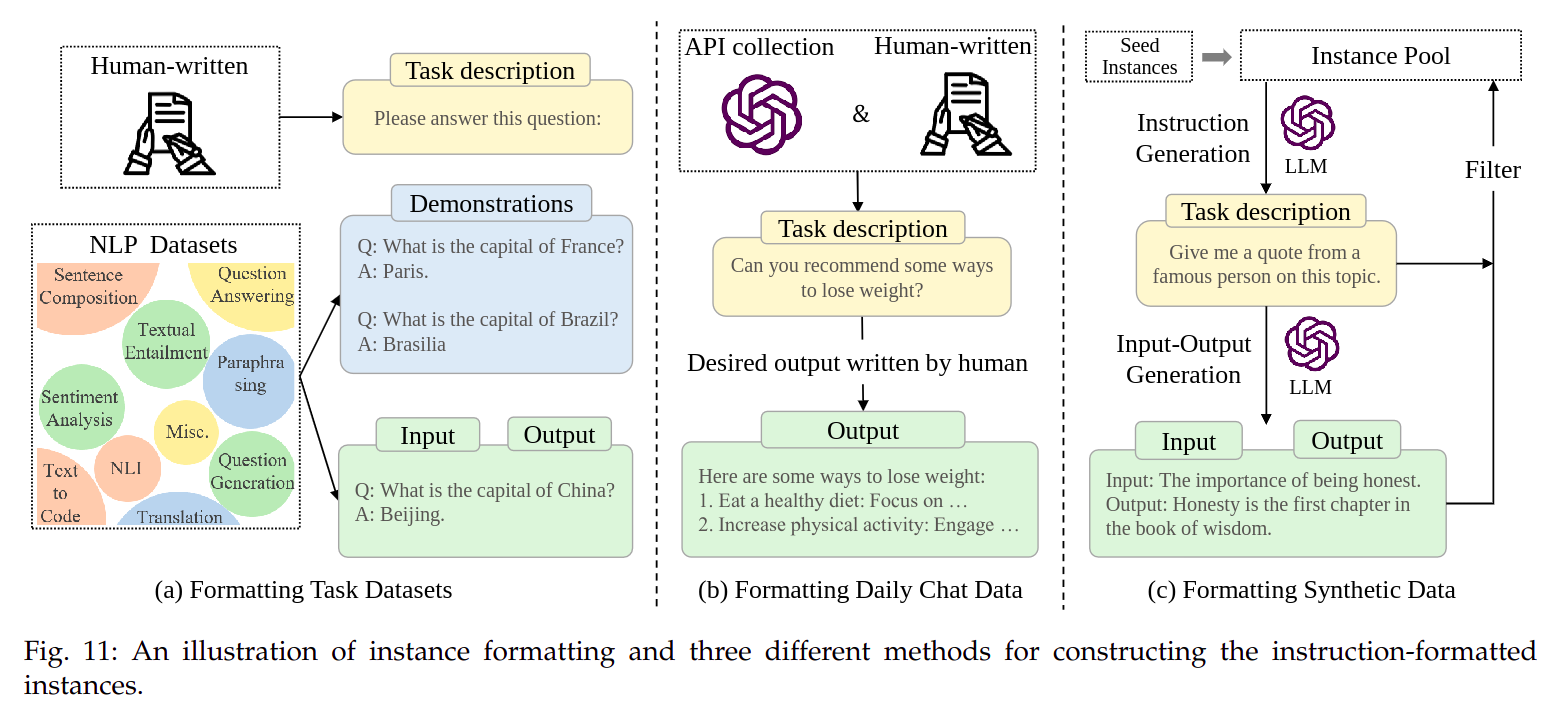
- 本文用三种(主要的)数据上格式化实例的构造举例:
- 格式化
NLP任务数据(如图11.a) - 格式化日常对话数据(如图
11.b) - 格式化人工合成数据(如图
11.c)
- 格式化
- 格式化
NLP任务数据- 这里的
NLP任务是指常见的自然语言任务,例如:- 文本总结(
text summarization) - 文本分类(
text classification) - 翻译(
translation)
- 文本总结(
- 格式化的
NLP任务数据通常由四部分组成:- 任务描述(
Task description) - 示例(
Demonstrations) - 输入
- 输出
- 任务描述(
- 任务描述部分很重要,去掉之后微调效果下降明显
PromptSource是个很好用的格式化NLP任务数据的开源工具,提供了很多任务模板,同时提供了一个开源Prompt集合数据集称为Public Pool of Prompts (P3)
- 这里的
- 格式化日常对话数据集
NLP数据集上的格式化实例缺乏Prompt的多样性,且和人类实际需求不匹配- 日常对话数据集主要包含两部分:
- 任务描述(
Task description) - 输出
- 任务描述(
- 这两部分都由人类完成,其中:
- 任务描述来自于
ChatGPT API收集到的问题以及人类标注员,内容包含:- 开放内容生成(
opened generation) - 开放问答(
open question answering) - 头脑风暴(
brainstorm) - 聊天(
chatting)
- 开放内容生成(
- 输出全部由人类标注员完成
- 任务描述来自于
- 格式化人工合成数据
- 以上两种数据集的格式化实例的方法要么需要大量的标注员,要么需要大量的手动收集,格式化人工合成数据是个半自动方法。
- 原理是通过将已收集的格式化数据输入到大模型中,让大模型给出相似的实例。
- 步骤:
- 首先用少量人工标注的格式化数据作为样本放入样本库
- 大模型从样本库中随机采样,仿照样本格式输出另外一个相似的实例
- 过滤生成实例的质量,如果没问题则加入样本库中,重复第一步
- 格式化数据过程中的关键因素
- 指令的缩放法则(
Scaling the instructions)- 指令微调数据集中涉及到的任务种类越多,多样性越丰富,效果就越好
- 一种任务中的实例数量不需要很多,大模型容易饱和
- 格式设计(
Formatting design)- 必须包含任务描述,任务描述对
LLM理解任务至关重要 - 适当数量的演示示例可以降低模型对指令工程的敏感性
- 引入
CoT (Chain-of-Thought)和非CoT数据会让LLM在需要多跳推理能力的任务和不需要多跳推理的任务上表现好 - 引入其他信息(例如: 避免的事项、原因和建议等)对
LLM性能影响较小或会产生负面影响
- 必须包含任务描述,任务描述对
- 总结
- 指令数据集的多样性和质量比数量更重要
- 标注员编写人类需求实例比特定于数据集的任务更有用,但人力成本较高
- 为减少人力成本,
LLM自动构建指令数据集是一种有效的方法
- 指令的缩放法则(
2. 指令微调策略
- 平衡数据分布
- 最简单的也是应用最广泛的方法是:混合所有数据,然后平等的采样每一个样本
- 有研究表明,对于高质量的数据集,应该适当提高其采样概率
- 需要设置采样上限,防止较大数据集主导整个指令微调过程
- 每个数据集所侧重的能力不同,用单一数据集微调无法全面增强模型容量,通常需要多种类型的数据混合微调,例如:
NLP任务数据集(FLAN v2)- 聊天数据集(
ShareGPT) - 合成数据(
GPT4-Alpaca)
- 预训练与指令微调联合训练
- 有些模型预训练阶段是个多任务模型,一个任务是常规预训练,另一个任务是指令对齐任务,例如
OPT-IML模型 - 有些模型预训练阶段的数据中混入了一小部分格式化后的指令对齐数据,在预训练过程中就完成了指令对齐,例如
GLM-130B和Galactica等
- 有些模型预训练阶段是个多任务模型,一个任务是常规预训练,另一个任务是指令对齐任务,例如
- 多阶段指令微调
- 指令微调数据集大体上分为两种:任务格式化指令对齐数据和日常对话指令微调数据
- 其中任务格式化指令数据通常数据量更大,数据集的平衡是非常重要的,因此通常需要非常小心的平衡两种数据
- 另外一种更简单的方法是将两种数据分成两个阶段分别训练,例如:先用任务格式化指令数据微调,然后再用日常对话指令数据微调
- 实际应用中为了防止能力遗忘问题(
Capacity forgetting issue),通常在日常对话指令数据微调过程中加入少量任务格式化指令数据
- 一些其他微调技巧
- 多轮对话数据的高效微调方法
- 对于人机多轮对话数据,通常的做法是将其拆分成多组问答对,然后每对对话数据单独训练,这种训练方式会有对话内容重叠的问题
- 一种高效的多轮对话数据微调方法是将整个对话一次送入
LLM微调,且只对 机器输出的对话部分计算损失
- 建立
LLM的自我认知- 为
LLM建立自我认知对于部署应用LLM很有必要,例如:名称、开发者和隶属关系 - 一种实用的方法是 构建自我认知相关的微调指令,也可以加入带有自我认知相关的提示前缀,例如:”以下是人类和
AI助手之间的对话“
- 为
- 多轮对话数据的高效微调方法
3. 指令微调的作用
- 提升模型表现
- 指令微调已经成为提升模型能力和解锁模型部分能力的重要方法
- 大模型和小模型都可以在指令微调过程中获得收益,模型越大收益越大
- 经过指令微调过的小模型比没有经过指令微调的大模型效果更好
- 指令微调不止可以用于
LLM,预训练NLP模型也可以用 - 此外指令微调的计算代价和数据量和预训练过程相比很小
- 任务泛化
- 大量研究表明,指令微调可以使大模型在见过和没有见过的任务上都表现良好(也可以认为指令微调可以使大模型获得任务泛化的能力)
- 指令微调甚至可以缓解大模型的部分缺点,例如重复生成
- 指令微调可以让大模型泛化到跨语言种类的相似任务上,例如
BLOOMZ-P3是在BLOOM上仅用纯英文数据P3微调得到的,经测试发现在多语种语句补全任务上,BLOOMZ-P3比BLOOM提升超过50%,表明即使用纯英文数据做指令微调,可以提高大模型在其他语言上的表现 - 研究表明,仅用纯英文数据做指令微调,即可解决多语种任务的性能
- 任务专业化
- 在专业领域指令数据上上做指令微调,大模型可以变成专业模型,例如:在医疗、法律、金融等指令微调数据集上做微调
4. 指令微调经验性的分析
- 指令微调数据集
- 任务相关的指令数据
- 常用的数据集是
FLAN-T5包含1836个任务的超过15M条指令数据
- 常用的数据集是
- 日常对话指令数据
- 常用的数据集是
ShareGPT,包含63K条真实用户指令
- 常用的数据集是
- 合成指令数据
- 常用的数据集是
Self-Instruct-52K包含52K条指令对共计82K个实例的输入输出
- 常用的数据集是
- 任务相关的指令数据
- 微调效果提升策略
- 提升指令的复杂性
- 可以参考
WizardLM设计,通过增加约束、提高推理步骤、提高输入复杂度的方式,逐步提高指令的复杂性
- 可以参考
- 提升指令数据集话题的多样性
- 合成数据通常会有话题多样性差的问题,可以通过更强的
LLM对其进行话题多样性扩写,例如用ChatGPT扩写Self-Instruct-52K数据
- 合成数据通常会有话题多样性差的问题,可以通过更强的
- 提升指令数据量
- 在指令质量不下降的情况下,尽可能提高指令数据量
- 平衡指令的困难程度
- 指令太简单或太复杂都会影响模型微调,容易出现训练不稳定或过拟合的问题
- 需要去除数据集中太简单或太复杂的指令
- 可以通过用
LLaMa推理指令输出的困惑度来对指令的困难程度排序,删除过难过易的样本
- 提升指令的复杂性
- 实验设置和结果分析
- 本节是
Survey的作者亲自做的指令微调实验的设置和结果分析 - 实验设置
- 模型:对
LLaMa做指令微调,包括LLaMa-7B和LLaMa-13B两个模型 code base:[YuLan-Chat](https://github.com/RUC-GSAI/YuLan-Chat)一个作者实验室开源的代码- 硬件环境:一台
8卡A800-80G GPU服务器 - 超参数:和
[Stanford Alpaca](https://github.com/tatsu-lab/stanford_alpaca)指令微调超参数相同(Stanford Alpaca是一个基于LLaMa的指令跟随模型) - 微调配置:分成
Chat setting和QA setting两个微调配置Chat setting:- 利用来自日常对话的用户指令和请求做微调
- 微调实验:
baseline(对照组):在Self-Instruct-52K上微调的LLaMa-7B和LLaMa-13B模型- 实验组:用上面提到的更科学的数据集和数据集混合方法得到的指令微调数据
benchmark:[AlpacaFarm evaluation set](https://github.com/tatsu-lab/alpaca_farm)- 对比方法:对于
benchmark的每一条数据,用实验组和对照组的两个模型分别推理给出结果,让ChatGPT评判哪个更好,最后比较胜率
QA setting:- 利用来自已有的
NLP任务的问答数据集做微调 benchmark:[MMLU (Massive Multitask Language Understanding)](https://arxiv.org/abs/2009.03300)和[BBH (BIG-Bench Hard)](https://arxiv.org/abs/2210.09261)数据集
- 利用来自已有的
Prompt:- “The following is a conversation between a human and an AI assistant. The AI assistant giveshelpful, detailed, and polite answers to the user’s questions.\n[|Human|]:{input}\n[|AI|]:”.
- 在微调训练和
benchmark推理时都加
- 模型:对
- 结果分析
NLP任务格式化指令数据对QA setting任务有效,对Chat setting任务无效- 混合多种不同的指令数据对提高模型理解能力有帮助
- 提高指令的复杂性和多样性主导了指令微调效果的提升
- 简单提高指令的数量可能没有收益,平衡指令的困难程度也不总是有效的
- 模型越大,指令微调效果越好
- 指令微调建议
- 提前准备计算资源(
GPU) - 用
Alpha开源库做微调 - 选择合适的开源预训练
LLM模型和指令微调数据集,开始微调 - 如果计算资源有限,可以考虑
LoRA等微调方式 - 对于部署,可考虑使用低比特量化等方法减小计算量
- 提前准备计算资源(
- 本节是
5.2 Alignment Tuning 对齐微调
1. 背景和对齐标准
- 背景
- 大模型在很多
NLP任务中表现出非凡的能力,但有时会生成一些负面的内容,例如:- 伪造虚假信息
- 追求不正确的目标
- 生成错误、误导或带有偏见的表达
- 出现这种问题的原因通常是在预训练数据中混入了负面内容,但预训练数据太大,清洗是不现实的
- 因此才出现了对齐微调,对齐微调的目标是
3H(helpfulness / honesty / harmlessness) - 对齐微调可能会损伤大模型原有的生成能力,这也被称为
alignment tax(对齐税)
- 大模型在很多
- 对齐标准
Helpfulness帮助性- 尽可能简洁高效的帮助人类解决任务或回答问题
- 当需要更高层次的阐明时,大模型应展现出提出相关的问题来获取额外信息的能力,并且在这个过程中表现出适当的敏感度、洞察力和审慎性
- 做帮助行为对齐是一件有挑战的事,因为很难精确定义和衡量用户的意图
Honesty诚实性- 应该给出诚实的回答而不是伪造的信息
- 为避免产生任何形式的欺诈和虚假陈述,大模型应该适当传达出其输出的不确定性
- 模型应该了解自身的能力边界
- 与
Helpfulness和Harmlessness相比,Honesty更客观,因此对齐需要的人力付出会更少
Harmlessness无害性- 模型输出不应包含冒犯或歧视
- 当模型被诱导做出危险行为时,应礼貌的拒绝
- 但如何定义有害涉及到使用模型的用户、问题类型以及上下文
- 总结
- 以上三种对齐标准都比较主观,都是基于人类感知定义的,因此直接量化然后去优化是比较难的
- 一种有效的方法是:红队对抗,即让人类对于输入产生违反上述对齐标准的输出,然后让模型将这些作为反面教材去优化
2. 收集人类反馈
人类反馈在对齐微调大模型的过程中至关重要
- 人类标注员应如何选择
- 基本要求:
- 学历好:至少本科学历
- 英文好:英语母语
- 为了减小研究员和标注员的不匹配,需要研究员和标注者分别标注少量样本,然后选择标注员中和研究员标注相似性高的作为后续标注员
- 在标注员中选择一个优秀的超级标注员团队,这个团队更高优先级的为大模型标注对齐数据
- 基本要求:
- 如何收集人类反馈
- 基于排序的方法
- 最早的标注方式是:仅选择候选列表中标注员认为最优的选项,且由于每个标注员的偏好不同,这会导致人类的反馈不准确或不完整
- 基于排序的方法是:系统会自动从候选列表中选择两个选项,标注员选择哪个更好,系统根据标注员的选择对整个候选列表排序,这样可以有效降低不同标注员偏好不同导致的偏差,标注信息更完整
- 基于问题的方法
- 标注员回答研究员提问的问题,这种类型的标注信息细节丰富,涵盖了对齐标准和其他约束
- 基于规则的方法
- 通过人为书写的规则自动判断模型输出是否有毒有害
- 基于排序的方法
3. RLHF 人类反馈的强化学习
RLHF系统- 包含三个关键组成部分
- 一个用于对齐微调的预训练
LLM - 一个基于人类反馈训练的奖励模型
- 一套强化学习算法
- 一个用于对齐微调的预训练
- 预训练模型作为对齐的起点
InstructGPT 175B是在预训练的GPT-3上对齐的GopherCite 280B是在Gopher上对齐的
- 奖励模型用于评价人类对模型输出的偏好程度
- 使用人类偏好数据,可以是一个
LM的微调,也可以是LM从头训练 - 通常比
LLM参数量少,例如OpenAI用6B GPT-3作为Reward Model,DeepMind用7B Gopher作为Reward Model
- 使用人类偏好数据,可以是一个
- 强化学习算法用奖励模型的信号去微调预训练大模型
- 近端策略优化算法
PPO (Porximal Policy Optimization)比较常用
- 近端策略优化算法
- 包含三个关键组成部分
RLHF关键步骤
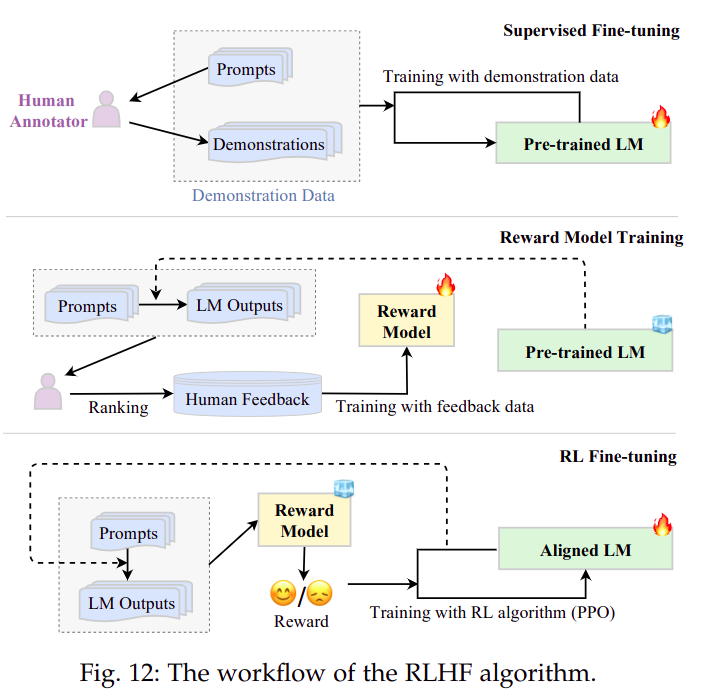
- 有监督微调
- 通常以“指令 —— 输出”数据对形式构造,做有监督微调
- 通常由人类标注员标注得到,需要包含较丰富的多样性
- 在一些特定场景的
RLHF中,此步骤可以跳过
- 训练奖励模型
- 通常由
LM生成对每个指令生成一系列输出,由人类标注员对输出进行 偏好排序 作为训练数据 - 奖励模型实际是在模仿人类标注员的偏好
- 通常训练得到的奖励模型更偏向于无害但无帮助的回答,这被称为 规避问题(evasion problem)
- 最近有一些工作用
AI Agent代替标注员对LM的输出进行偏好排序(RLAIF)开始套娃,AI Agent的排序原则是预设的指令对齐原则,这种方式的优势是:- 可以缓解规避问题,生成无害且有帮助的回答
- 降低对标注员的依赖,降本增效
- 通常由
- 强化学习微调
- 用强化学习的方式对第一步微调后的
LM进行训练,其中强化学习的各个要素分别为:- 策略(
policy):微调后的LM - 动作空间(
action space):LM的词表 - 状态(
state):目前生成的token序列 - 奖励(
reward):由第二步训练得到的RM提供 - 为了防止模型退化(逐渐偏离预训练行为),通常在奖励函数中加入一项惩罚项,例如:
InstructGPT通过在奖励函数中加入当前模型输出和微调之前的模型输出之间的KL散度,缓解模型的退化问题 - 通常重复迭代第二步(
RM的训练)和本步(强化学习微调),可以得到较好的模型
- 策略(
- 用强化学习的方式对第一步微调后的
- 有监督微调
RLHF实践策略
成功实现RLHF是比较困难的,这里提供一些实践上的策略和技巧- 奖励模型如何有效训练
- 大的奖励模型在评判大模型输出质量方面更优
- 在实践中,奖励模型有小模型(例如:
InstructGPT用6B GPT作为奖励模型)和大模型(和对齐模型一样大或者更大的模型作为奖励模型)两条路线,其中大模型路线在评判LLM输出质量方面更优 - 可以用
LLM预训练过程中的检查点参数初始化RM,这样可以缓解由于预训练数据不一致导致的对齐策略不匹配问题,LLaMa 2就是这么做的 - 大的奖励模型训练容易过拟合,用人类标注的对齐数据的提示词首选响应作为正则化项可以缓解过拟合
- 在实践中,奖励模型有小模型(例如:
- 训练一个满足所有对齐标准的奖励模型很难,可以用多个对齐模型的组合来实现,每个对齐模型只关注部分对齐标准
- 例如每个奖励模型只关注一项标准,然后用某种策略(例如平均或加权)组合每一种奖励模型的奖励值作为最终奖励
- 使用这种方法可以手动条件每一项对齐标注的严格程度(通过调节权重)
- 大的奖励模型在评判大模型输出质量方面更优
- 强化学习过程如何有效训练
- 强化学习通常是不稳定且超参数敏感的,因此需要在强化学习前模型已经得到充分的有监督训练
- 常用的方法是:
- 收集多样性较为丰富的对齐数据输入,通过采样策略让
LLM对每个输入推理得到N个输出 - 用奖励模型评判
N个输出,得到最优的输出 - 用“输入 —— 最优输出”数据对有监督训练
LLM,知道模型的表现不再提升(收敛)
- 收集多样性较为丰富的对齐数据输入,通过采样策略让
- 需要有部分人类标注的对齐数据
benchmark用来真实地评价模型对齐效果 - 通常需要奖励模型和强化学习优化过程的多轮迭代
- 强化学习过程如何高效训练
- 强化学习过程和奖励模型训练多轮迭代会带来巨大的存储和计算开销
- 可以将奖励模型部署在单独的服务器上,通过
API调用 - 对齐模型对于每个指令需要同时输出多组候选输出,用集束搜索算法(
beam search)效率更高,且可以提高输出的质量和多样性
- 奖励模型如何有效训练
RLHF的过程监督RLHF的监督可以分为两种:- 对结果监督:监督
LLM对于输入指令的完整输出 - 对过程监督:更细粒度的监督
LLM的输出过程,例如输出的每个句子、每个单词、每个推理步等
- 对结果监督:监督
- 过程监督数据集:
PRM800KPRM800K是OpenAI开源的RLHF过程监督数据集,可以用其训练PRM (Process-supervised Reward Model)过程监督奖励模型PRM800K包含:12K个过程标注的数学问题75K个由LLM生成的解法800K个过程正确性标签,标签分为:Positive正面Negative负面Neutral中性
- 过程监督可以和专家迭代强化学习算法(
Expert Iteration (EXIT))结合
4. 不用 RLHF 的对齐
RLHF做对齐微调的痛点- 需要训练被对齐模型和奖励模型,同时需要频繁推理参考模型(对齐前的模型,不训练,用于防止对齐过程导致模型退化),存储和计算代价大
RLHF过程中常用的PPO算法非常复杂,且对超参数敏感
- 不用
RLHF的对齐如何做?- 用
SFT代替RLHF,即用基于有监督微调代替基于人类反馈的强化学习 - 这种方法假设
LLM可以从对齐数据集中学习到对齐行为 - 这种方法包含两个关键:构建对齐数据集 和 设计微调损失函数
- 用
- 构建对齐数据集
对齐数据集的构建主要包含三种方法:基于奖励模型的方法、基于大模型的生成方法 和 基于大模型的互动方法- 基于奖励模型的方法
- 基于大模型生成的方法
Constitutional AI将人类监督映射为一组原则(自然语言指令的集合),让LLM重复的用这组原则批判并修正自己的输出Self-Align是先用Self-Instruct方法生成多样性强的指令数据集,然后模型会被提示多个人类编写的原则,这些原则描述了期望的模型规则和行为,以生成符合3H标准的数据用于对齐训练FIGA采用正样本(LLM精炼后的输出)和负样本(原始到低质量输出)对比学习的方法,缓解了SFT只能用正样本监督学习的问题,使LLM能够深入理解哪些细粒度的修改实际上导致了良好的响应
- 基于大模型交互的方法
- 传统大模型训练都是孤立的,没有外部反馈信号来改进自己
Stable Alignment通过多个LLM交互来获得改进的反馈,从而实现自我改进
- 有监督对齐微调
有监督对齐微调有点类似于指令微调,主要的训练损失函数依然是Sequence-to-Sequence的交叉熵损失,但一些研究提出对主要训练目标的改机,并提出了一些辅助损失,可用于挖掘对齐数据集的潜力,提高对齐质量- 主要训练目标
CoT (Chain of Hindsight)对有监督微调数据集中的正负样本分别添加“一个有帮助的回答”和“一个没有帮助的回答”两种指令,且仅对有特殊掩码的响应标记计算损失Quark将模型响应数据(对齐监督训练数据)按对齐质量分成不同的分位数,每个监督数据前加入一个特殊的奖励token,用于表示响应的奖励等级DPO (Direct preference optimization)将大模型本身用于奖励模型,从而不需要显式的奖励模型FIGA定义细粒度对比学习损失
- 辅助训练目标
- 主要训练目标
- 总结
RLHF是用对齐数据训练一个RM,然后用RM指导模型微调(给模型的响应打分)SFT是直接用对齐数据微调模型- 二者对比来看,
RLHF学习的是响应级监督,而SFT学习的是token级监督 SFT微调的模型,在遇到对齐微调数据集之外的数据时,更倾向产生幻觉,尤其是在对齐微调数据集是由大模型生成的时候- 由于没有奖励模型做标注质量过滤,
SFT对标注质量更敏感 RLHF对缓解有害输出和增强模型能力方面非常有效,在LLaMa 2中,RLHF同时提高了模型的帮助性和无害性得分,并将其归功于RLHF实现了一种更优的 “LLM —— 人类” 交互方式RLHF实际上是通过鼓励LLM通过对比自己生成内容的 “好” 和 “不好” 评价,找到一种纠正策略;而不是像SFT一样,强制让模型去模仿 “好” 的外部内容(非自我生成)RLHF可以减轻幻觉行为,这一点在GPT-4中被证实- 传统强化学习的缺点,
RLHF一样不少,比如样本效率低下和训练稳定性差 RLHF的LLM必须先用SFT预训练收敛的参数初始化RLHF需要标注员参与到复杂的迭代过程中,不能像SFT一样标注和训练解耦RLHF的结果对实验过程细节非常敏感,例如:- 提示词的选择
- 奖励模型和
PPO的训练策略 - 超参数设置
SFT可以提高预训练模型的容量,RLHF可能会提高SFT的模型容量RLHF过程还比较原始,需要探索和优化的点还有很多
5.3 参数高效的模型适配微调
- 参数高效的微调方法
大模型参数量太多,微调全部参数对大多数用户不可实现,因此 参数高效的微调方法 主要是通过降低微调过程中可学习的参数量实现参数高效的微调,主要方法有四种,如图:
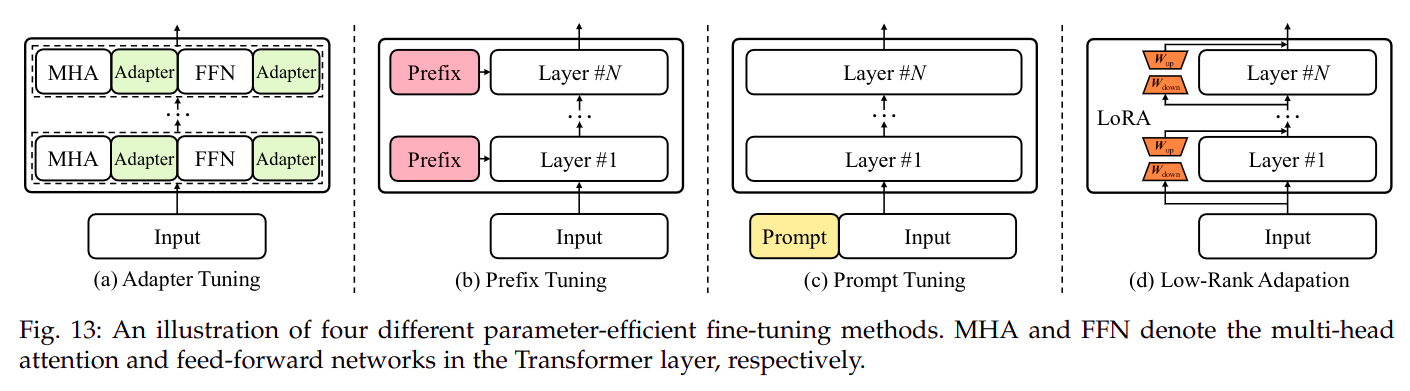
Adapter Tuning适配器微调- 适配器微调论文出自
2019年Parameter-Efficient Transfer Learning for NLP,是Bert时代的产物 - 本质是在 标准
Transformer模型预训练结束后,在每个Transformer block中加入两个Adapter block,其他参数冻结,只微调Adapter block Adapter block中包含降采样(Down project)算子,因此计算量和参数量都较小Adapter block在Transformer block中的位置以及Adapter block长什么样?
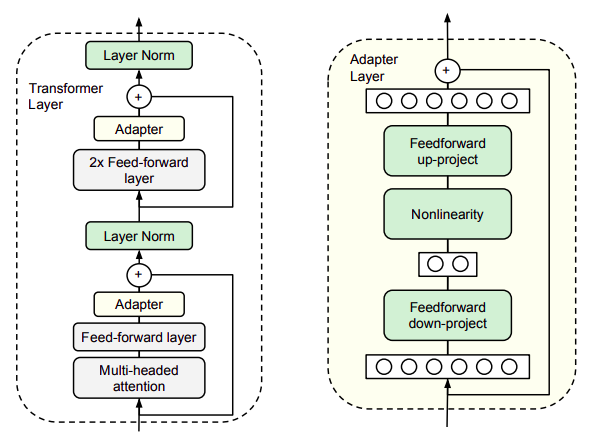
图中所有的绿色块表示微调过程中可训练的参数
- 适配器微调论文出自
Prefix Tuning/Prompt Tuning前缀微调- 前缀微调的基本假设是:预训练之后的大模型实际上已经完全具备解决任何下游任务的能力,只需要找到合适的提示词(不一定是词表中的词)即可。
- 开山之作是斯坦福的
Prefix Tuning,详细分析可参考 这篇博客 - 然后是清华大学提出的
P-Tuning,详细可参考 这篇博客 - 然后是谷歌对
Prefix Tuning的小修改版本,Prompt Tuning,详细分析可参考 这篇博客 - 清华大学还对
P-Tuning进行了升级P-Tuning v2,详细可参考 这篇博客
Low-Rank Adaptation (LoRA)- 具体参考 这篇博客