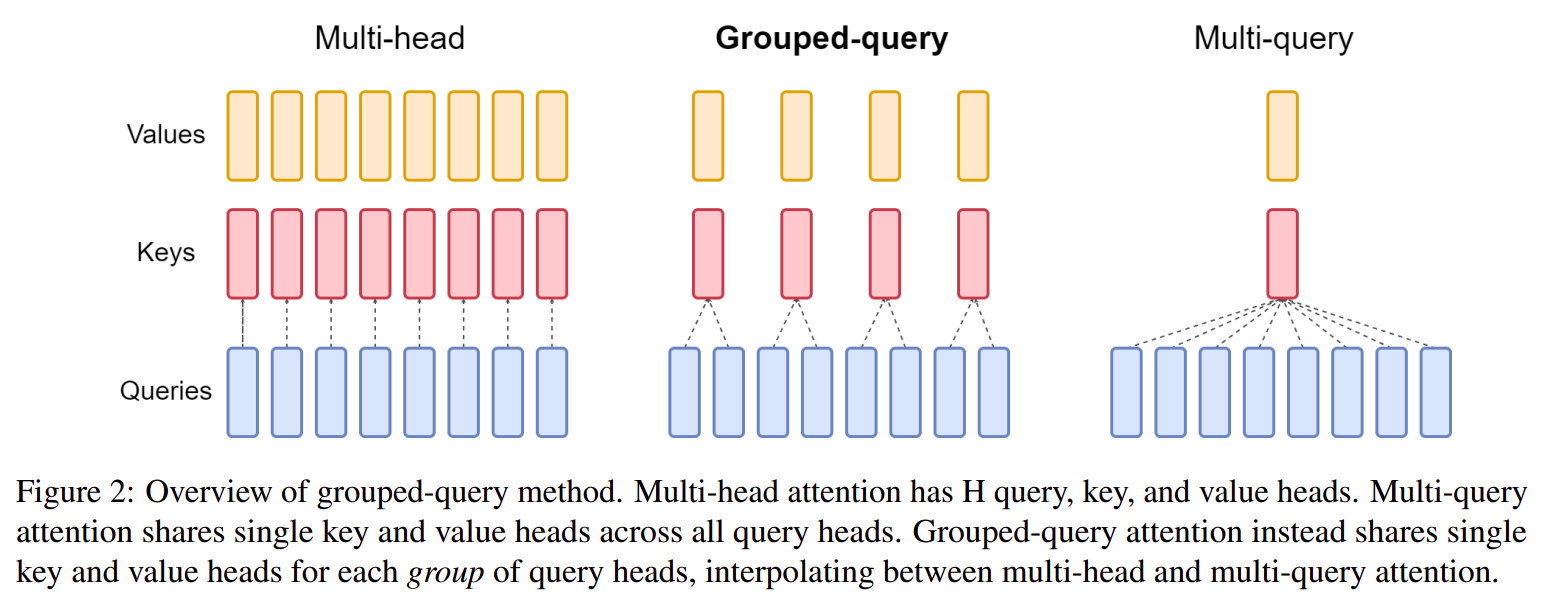
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| import torch
import torch.nn.functional as F
def multiquery_attention_batched(X, M, mask, P_q, P_k, P_v, P_o, num_groups):
assert 0 == P_q.size(0) % num_groups
heads_per_group = P_q.size(0) // num_groups
Q = torch.einsum("bnd,Hdk->bHkn", X, P_q).view(
-1, num_groups, heads_per_group, P_q.size(2), X.size(1)
)
K = torch.einsum("bmd,gdk->bgmk", M, P_k)
V = torch.einsum("bmd,gdv->bgmv", M, P_v)
logits = torch.einsum("bghkn,bgmk->bghnm", Q, K)
mask = mask.view(-1, num_groups, heads_per_group, mask.size(-2), mask.size(-1))
weights = F.softmax(logits + mask, dim=-1)
O = torch.einsum("bghnm,bgmv->bghnv", weights, V)
P_o = P_o.view(num_groups, heads_per_group, P_o.size(-2), P_o.size(-1))
Y = torch.einsum("bghnv,ghvd->bnd", O, P_o)
return Y
batch_size = 2
num_queries = 5
num_keys = 7
dim = 64
key_dim = 32
value_dim = 48
num_heads = 8
num_groups = 4
X = torch.randn(batch_size, num_queries, dim)
M = torch.randn(batch_size, num_keys, dim)
mask = torch.randn(batch_size, num_heads, num_queries, num_keys)
P_q = torch.randn(num_heads, dim, key_dim)
P_k = torch.randn(num_groups, dim, key_dim)
P_v = torch.randn(num_groups, dim, value_dim)
P_o = torch.randn(num_heads, value_dim, dim)
output = multiquery_attention_batched(X, M, mask, P_q, P_k, P_v, P_o, num_groups)
print(output.shape)
|