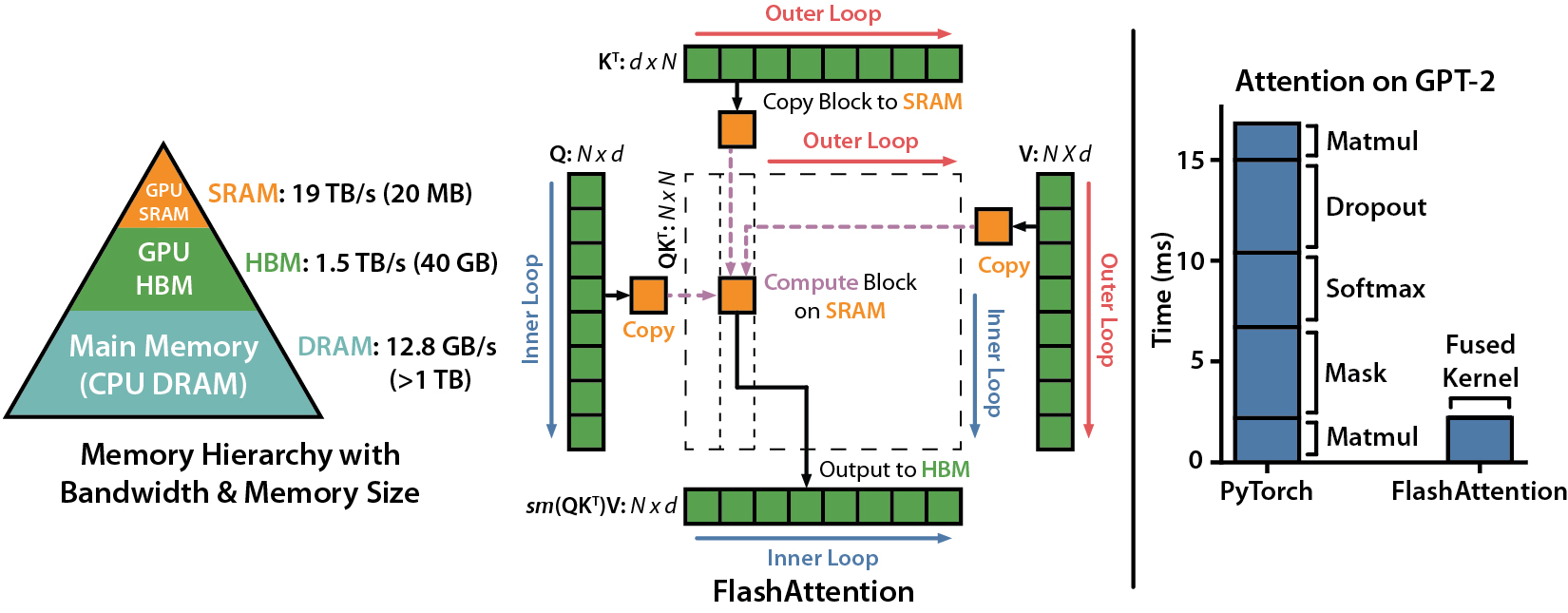
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| import torch
import math
BLOCK_SIZE = 1024
NEG_INF = -1e10
EPSILON = 1e-10
def flash_attention_forward(Q, K, V):
batch, seq_len, dim = Q.shape
O = torch.zeros_like(Q, requires_grad=True, device=Q.device)
l = torch.zeros((batch, seq_len, 1), device=Q.device)
m = torch.ones((batch, seq_len, 1), device=Q.device) * NEG_INF
Q_BLOCK_SIZE = min(BLOCK_SIZE, seq_len)
KV_BLOCK_SIZE = BLOCK_SIZE
Q = torch.split(Q, Q_BLOCK_SIZE, dim=1)
K = torch.split(K, KV_BLOCK_SIZE, dim=1)
V = torch.split(V, KV_BLOCK_SIZE, dim=1)
O = list(torch.split(O, Q_BLOCK_SIZE, dim=1))
l = list(torch.split(l, Q_BLOCK_SIZE, dim=1))
m = list(torch.split(m, Q_BLOCK_SIZE, dim=1))
Tr = len(Q)
Tc = len(K)
scale = 1 / math.sqrt(dim)
for j in range(Tc):
for i in range(Tr):
Qi_scaled = Q[i] * scale
S_ij = torch.einsum("... i d, ... j d -> ... i j", Qi_scaled, K[j])
m_ij, _ = torch.max(S_ij, dim=-1, keepdim=True)
P_ij = torch.exp(S_ij - m_ij)
mi_new = torch.maximum(m_ij, m[i])
l_ij = (
torch.sum(P_ij * torch.exp(m_ij - mi_new), dim=-1, keepdim=True)
+ EPSILON
)
P_ij_Vj = torch.einsum(
"... i j, ... j d -> ... i d", P_ij * torch.exp(m_ij - mi_new), V[j]
)
li_new = torch.exp(m[i] - mi_new) * l[i] + l_ij
O[i] = (O[i] * l[i] * torch.exp(m[i] - mi_new) + P_ij_Vj) / li_new
l[i] = li_new
m[i] = mi_new
O = torch.cat(O, dim=1)
l = torch.cat(l, dim=1)
m = torch.cat(m, dim=1)
return O, l, m
def flash_attention_backward(Q, K, V, O, l, m, dO):
pass
if __name__ == "__main__":
Q = torch.randn(2, 4096, 128, requires_grad=True).to(device="cuda")
K = torch.randn(2, 4096, 128, requires_grad=True).to(device="cuda")
V = torch.randn(2, 4096, 128, requires_grad=True).to(device="cuda")
out = flash_attention_forward(Q, K, V)
print(out[0].sum().item())
|