URL
TL;DR
- 本文利用了
Speculative decoding思想实现了一个SpecInfer大语言模型推理加速系统 - 和标准
Speculative decoding使用seq组织预测的token不同,SpecInfer使用tree数据结构组织预测的token SpecInfer中的target模型可以并行验证整个token tree的正确性,而不是token seq,且可以保证和原模型输出完全一致
Algorithm
增量式解码、序列式投机解码、树式投机解码三者对比
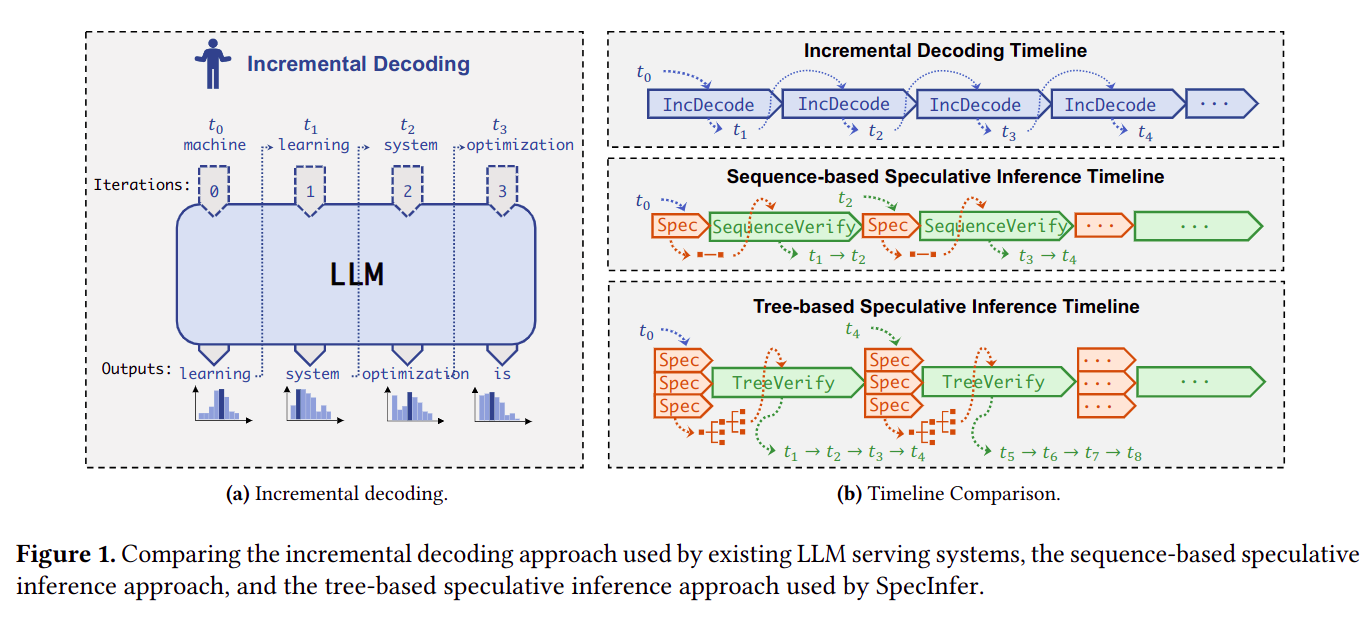
左图表示传统增量式推理
LLM的解码方式
右图从上到下依次表示:增量式解码、序列式投机解码、树式投机解码
候选树生成和验证流程
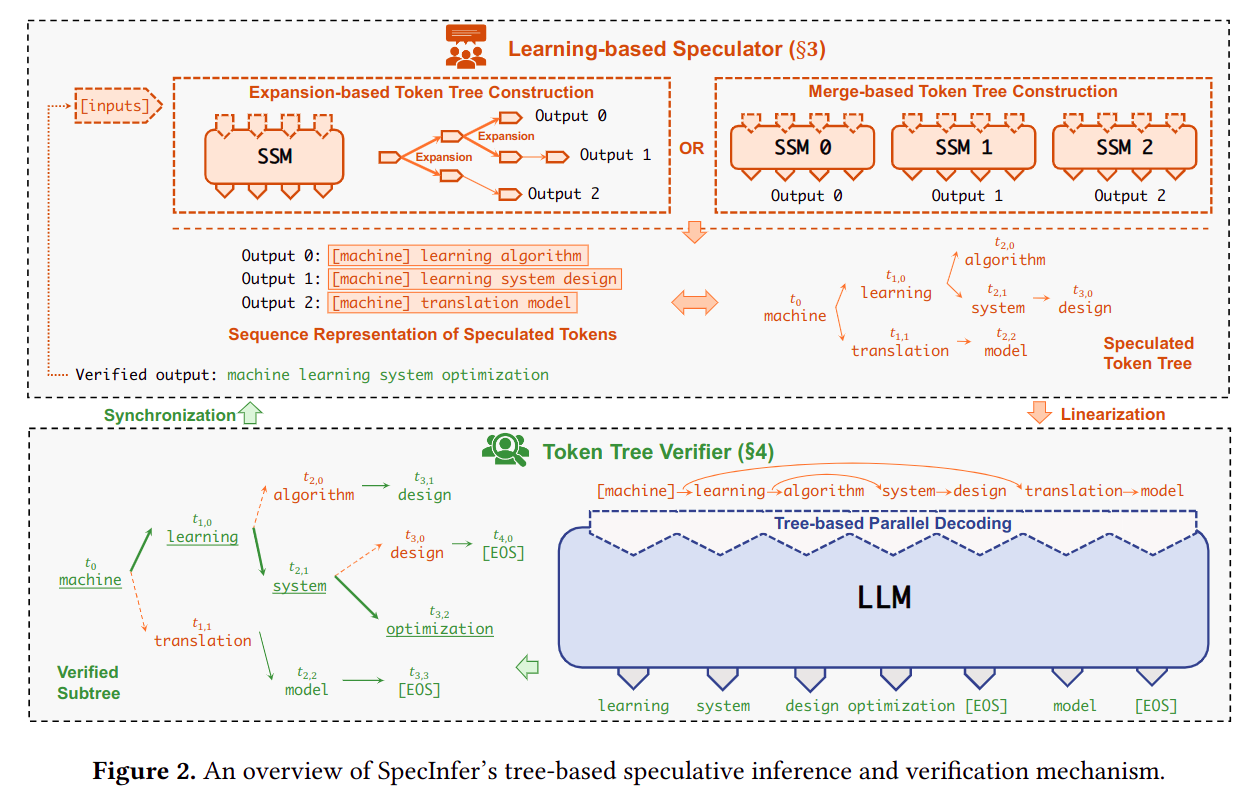
SSM (small speculative model)给出候选树
target model对候选树进行验证
如何对树式结构并行解码
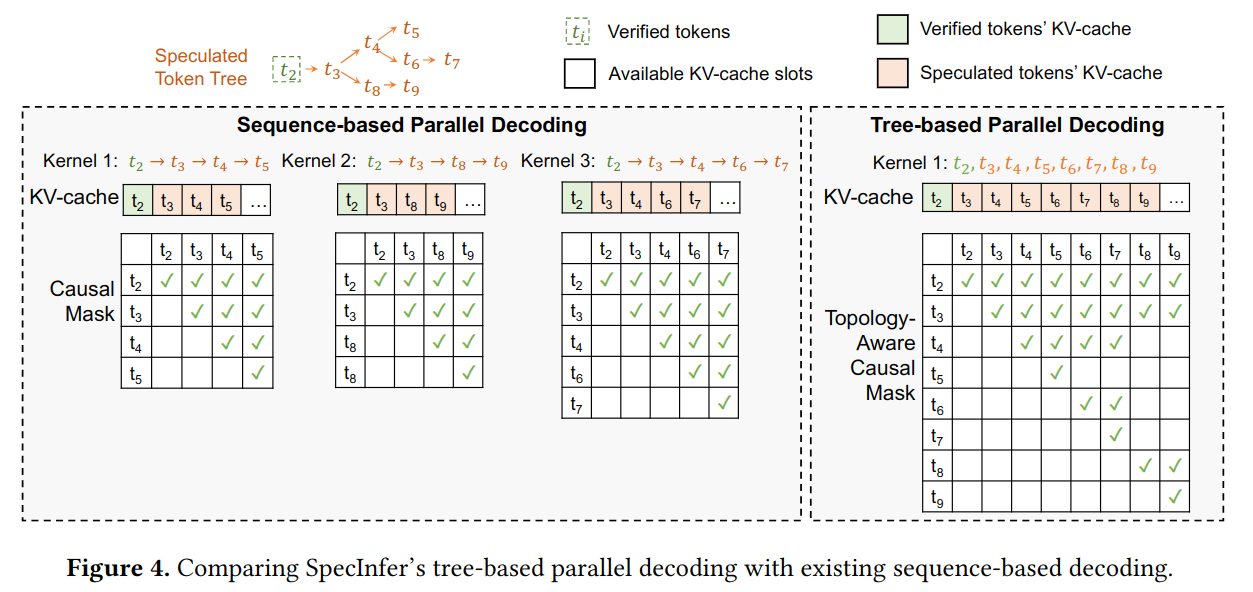
注意:这的 “并行” 是指可以一次解码一棵树而不需要将树深度优先搜索得到多组序列然后一一解码
- 使用
kv cache对解码过程进行加速是一个常见的方法,但树式结构无法直接使用kv cache(因为要动态剪枝,如图左侧所示) - 因此本文提出一种新颖的方法使得树式结构可以并行解码,这个方法包括两个改进:
- 对树进行 深度优先搜索,使得树变成一个序列
- 将传统的上三角
attention mask变成一个topology-aware mask,即通过mask来确定token两两之间的可见性(如图右侧所示),这种可见性包含:- 每个
token看不到之后的token(矩阵下三角置 ) - 每个
token看不到不在其拓扑路径上的token
- 每个
总体算法流程

- 先用
small speculate model推理sequence得到候选树 - 在使用
LLM树式并行解码sequence得到大模型预测结果 - 用贪心算法或随机匹配算法对候选树 逐个节点验证(接受或拒绝)
- 重复直到
<EOS>出现
贪心验证算法和随机验证算法

- 这里的两种算法和 https://zhangzhe.space/2024/08/14/Fast-Inference-from-Transformers-via-Speculative-Decoding/ 里的流程基本一致,不一样的地方仅仅在于
tree / sequence两种候选token的组织形式
贪心验证
- 表示当前节点,从根节点开始广度优先遍历
- 表示 是 的子节点
- 表示大模型和投机模型预测结果一致
随机验证
- 表示当前节点,从根节点开始广度优先遍历
- 当在
[0, 1]之间随机均匀采样得到的随机数 时,接受这个节点,否则拒绝
Thought
- 这篇论文站在
speculate decoding的肩膀上,加入了树结构的候选列表,算是speculate decoding的超集 topology-aware mask和decoder attention mask结合的方法还是挺巧妙的- 由于是树结构存储候选词,那么多个
SSM是天然适配的,算是个工程角度很好用的trick