URL
- paper: https://arxiv.org/pdf/1811.06965
- code: https://github.com/tensorflow/lingvo/blob/master/lingvo/core/gpipe.py
TL;DR
- 随着模型和数据量的增长,单
GPU已经无法满足需求,所以需要多GPU并行 Data parallelism是最常用的,即将数据划分到多个GPU上,每个GPU单独前向反向传播,仅在梯度更新时聚合,例如pytorch ddp- 本论文提出一种新的并行方式
Pipeline parallelism,这种方式是将模型划分为多段子图,每个设备上加载一段,各个子图直接串联 - 直接实现的
Pipeline parallelism的GPU利用率较低,本文通过一些方法可大幅提高GPU利用率
Algorithm
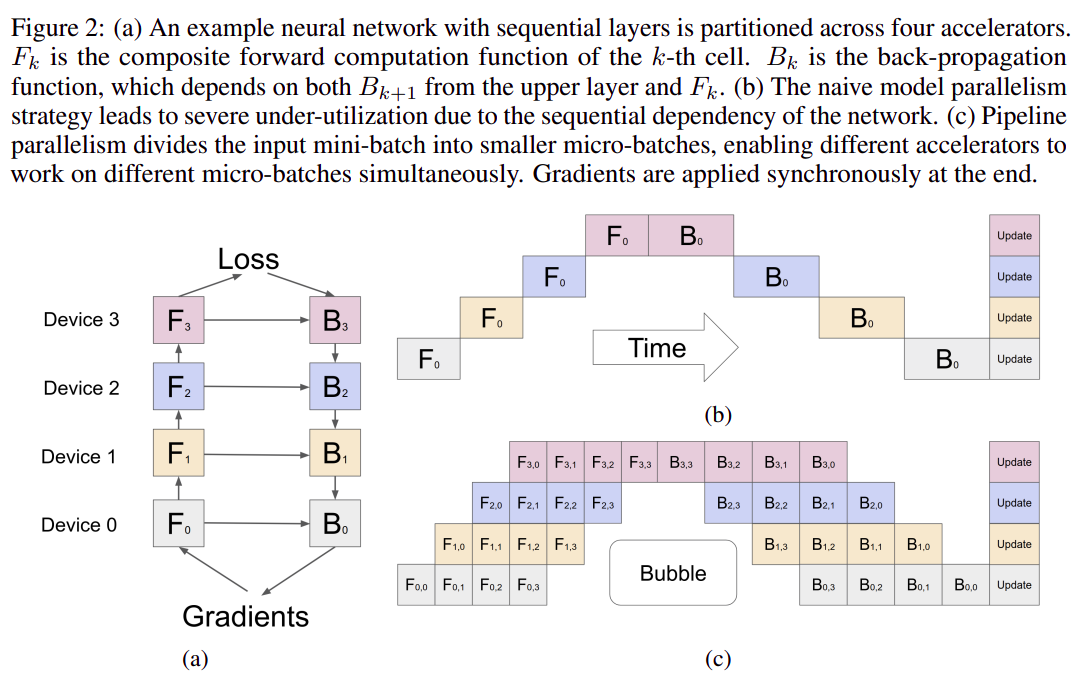
Gpipe 方案主要包含三个部分
划分 Stage
- 模型切成若干
stage,每个GPU只加载一段 - 每个
stage串起来形成一个pipeline
划分 Micro-Batch
- 传统模型训练过程中使用
Mini-Batch,Mini-Batch在pipeline parallelism中会出现大量气泡,因此Gpipe提出Micro-Batch概念 Micro-Batch是将Mini-Batch再划分成多份,用于排计算流水,Micro-Batch变成最小计算单元,有利于减小气泡,上图2.c中横向就是一个Mini-Batch划分得到的一组Micro-Batch- 为了保证梯度更新和
Mini-Batch的一致性,Gpipe会将Micro-Batch梯度累积,在一个Mini-Batch的全部Micro-Batch计算结束后再更新(图2.c中一行只有一次update)
重计算
- 传统模型训练过程中,计算的中间结果都需要保存,用于反向传播计算梯度,非常消耗显存,同时会导致
pipeline parallelism的数据依赖问题,上图2.a中的横向连接 - 重计算是一种用计算换空间的操作,在前向传播过程中,丢弃
stage内所有中间结果,只保留stage间中间结果;在反向传播时,stage内中间结果会再做一次前向传播计算得到 - 重计算可大幅降低显存占用,使得可以放更大的
batch size和更大的模型,且可以改善数据依赖问题
Thought
- 这种方案前瞻性比较强,提出时还没有
LLM,且拥有和传统非并行训练在数学上一致的参数更新机制 - 给并行训练提供了一种新思路,非常灵活