0%
URL
TL;DR
- 本文提出一种和
Gpipe 类似的 pipeline parallelism 并行训练机制 PipeDream,和 Gpipe 可以任意划分模型不同,PipeDream 自动化划分网络,以实现负载均衡和最小通信开销。
- 与
Gpipe 的同步更新机制不同,PipeDream 采用异步参数更新机制。
Algorithm
backward 的过程实际同时包含了 参数更新
- 与
Gpipe 使用的 Micro-Batch + 同步参数更新机制不同,PipeDream 使用异步更新机制,异步更新主要包含以下几点:
weigt stashing
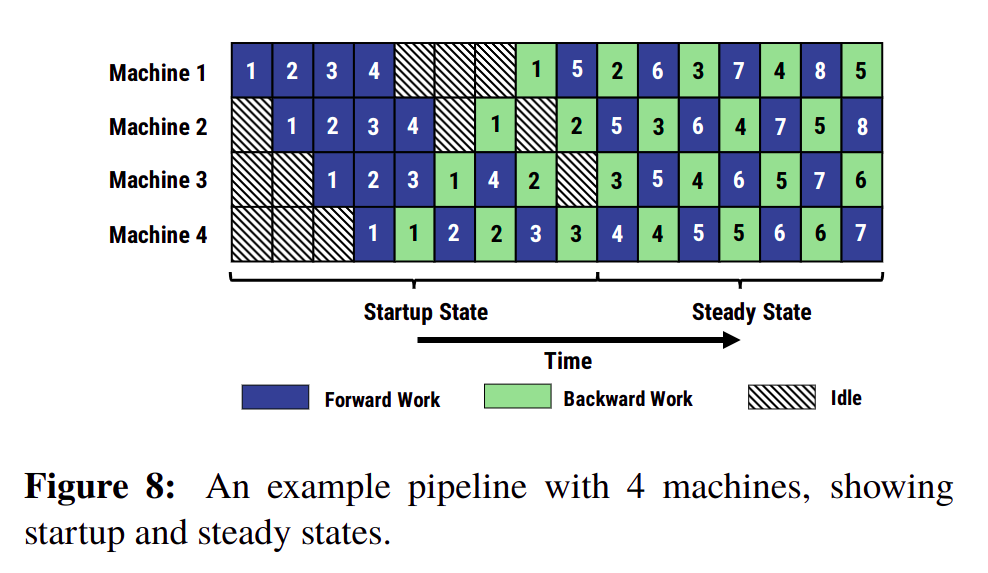
- 从上图可以看出
Machine 1 在 forward 5 时,使用的是更新过 1 次的参数(forward 5 之前只做了 backward 1);但当 backward 5 时,参数已经被更新了 4 次,如果直接使用会出现 forward 和 backward 参数不一致问题
- 因此,
PipeDream 提出了 weight stashing (权重存储),即保存多组 weights,每次 forward 过程使用最新版本的 weights,当 backward 时,使用 forward 时刻对应的 weights
- 使用
weight stashing 之前,w(t+1)=w(t)+γ⋅△f(w1(t),w2(t),...,wn(t)),其中:
- γ 表示
learning rate
- n 表示
stage 的数量,即 GPU 数量
- wi(t) 表示
weights of stage i after t mini-batch,即当运行了 t 个 mini-batch 之后的 stage i 的权重
- △f 表示梯度
- 使用
weight stashing 之后,w(t+1)=w(t)+γ⋅△f(w1(t−n+1),w2(t−n+2),...,wn(t))
vertical sync
weight stashing 解决了 forward 和 backward 使用的 weight 版本不一致问题,但依然存在另外一个问题:同一个 mini-batch 在不同 stage 上 forward 使用的 weight 版本不一致- 例如,对于
mini-batch 4,在 Machine 2 上 forward 使用的参数版本是未更新版本,在 Machine 3 上 forward 使用的版本是更新过一次的版本
- 为解决这个问题,作者提出
vertical sync 概念,即:对于一个 mini-batch 在每个 stage 上 forward 都使用最旧版本的参数,stage forward and backward 结束后统一更新参数
vertical sync 应用之后,w(t+1)=w(t)+γ△f(w1(t−n+1),w2(t−n+1),...,wn(t−n+1))- 事实上实验证明,
weight stashing 对训练精度提升明显,vertical sync 提升较小
Thought
- 感觉
PipeDream 为了充分排流水,减小 bubble,没有等 forward 全部结束就开始 backward,然后发现和单 GPU 更新机制不等价,然后用了 weight stashing 和 vertical sync 去找补,做到等价
- 和
Gpipe 相比,灵活性更差,实现难度更高(需要缓存各个版本的 weights,听上去也是几倍的存储开销以及吞吐量)