URL
TL;DR
- 本文是英伟达
Megatron-LM大模型分布式并行训练框架的一篇简介,大概阐述了Megatron-LM的机制和效果,对于实现细节着墨不多。 - 从代码实现角度看,
Megatron-LM是对PyTorch进行了二次封装。 - 基本思想是
Tensor Parallelism,拆分一层的权重到不同GPU上并行运算。
Algorithm
Tensor Parallelism
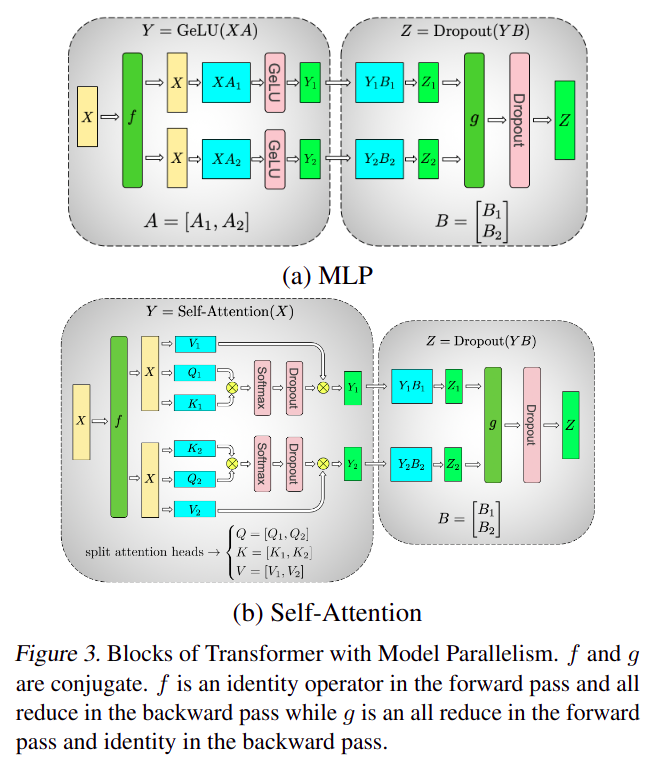
- 重点是这里的
f和g函数,下面是其实现:
1 | class f(torch.autograd.Function): |
- 在本例子中
All-reduce实际上是ReduceSum,实际上聚合运算(包括forward and backward)需要GPU间同步,存在通信代价 Self-Attention可以tensor parallelism的一个重要原因是softmax是逐行做的而不是全局做的
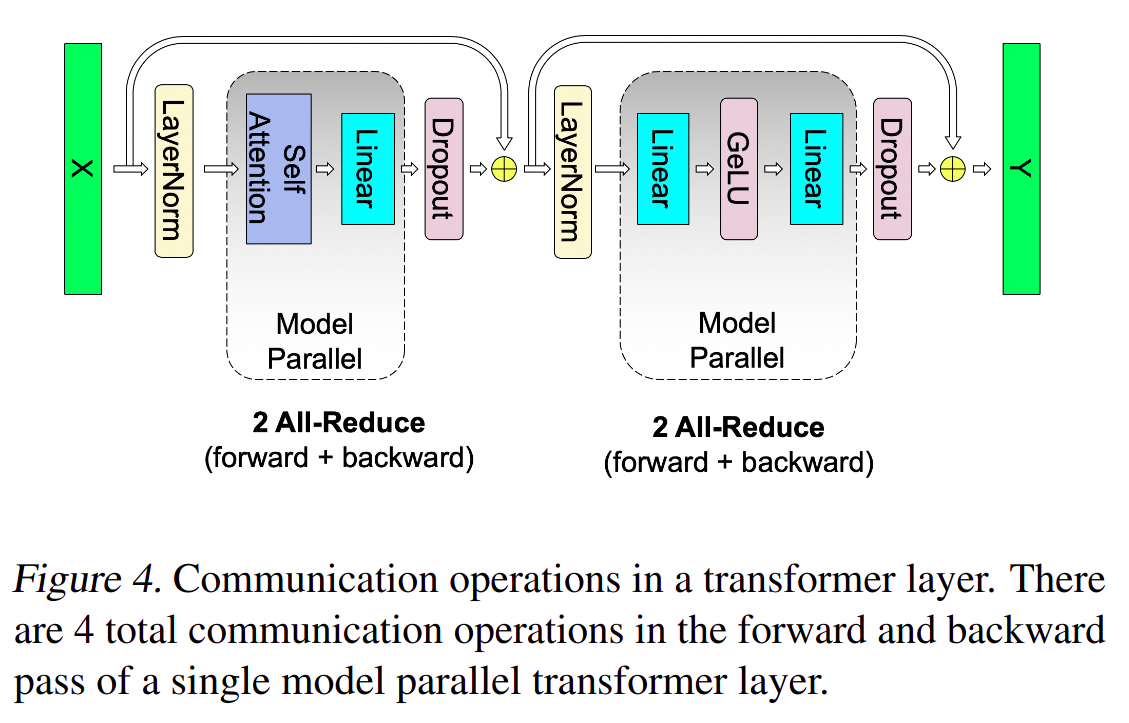
- 由图
3可以得出结论,一个transformer layer只有4个同步算子(两个LayerNorm和两个Dropout),其他算子都可以被分解为并行算子
Thought
- 给我的感觉有点类似
MLC或者机器学习编译中的Tiling(只是升级为训练及推理全流程tiling) tensor parallelism这种策略很考验对计算流程的抽象,除非有大量人力把框架搭建好且把所有算子实现写好,否则会很难用起来(当然对于Nvidia这些都不是事),突然想起了Neuwizard,一声叹息…