URL
TL;DR
- 传统的
DDP训练大模型有个很大的问题是:由于DDP训练中每个GPU上都需要存储模型状态信息和其他状态信息:- 模型状态信息包括:
Prameter+Gradient+Optimizer states - 其他状态信息包括:激活值(
Activation)、各种临时缓冲区(buffer)以及无法使用的显存碎片(fragmentation)
所以显存占用较大,使得不能通过DDP训练较大的模型。
- 模型状态信息包括:
- 本文提出来
Zero-DP和Zero-R两种大模型训练优化策略,分别解决模型状态信息过大和其他状态信息过大的问题。 Zero-DP全称是Zero Redundancy Optimizer Data Parallelism,主要优化点是将GPU间冗余存储的模型状态信息(Parmeter + Gradient + Optimizer states)删除,每个GPU只保留一小部分信息,所有GPU上的信息汇聚之后才是完整模型。Zero-R的目的是解决Tensor Parallelism训练时,Activation信息占用过大的问题。
Algorithm
ZeRO-DP
ZeRO-DP 想要解决什么问题?
- 解决
DDP训练过程中,Parmeter + Gradient + Optimizer states对显存的占用过大,导致无法训练很大的模型的问题。
没有其他方法可以降低显存占用吗?
- 有的,比如混合精度训练 (https://arxiv.org/pdf/1710.03740) 就是一个常用的有效的手段
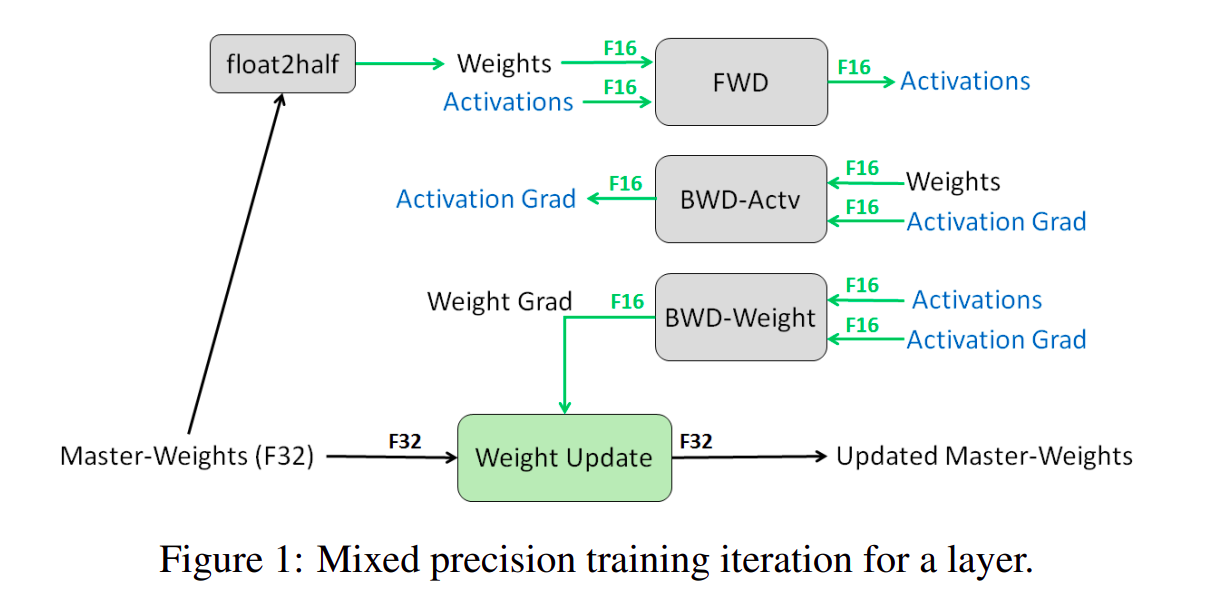
- 已知
LLM通常使用Adam / AdamW优化器进行优化,假设模型参数量为 ,那么用混合精度训练过程中,模型状态信息实际的显存占用是:Parameter占用 字节(fp16类型存储)Gradient占用 字节(fp16类型存储)Adam Optimizer state占用:fp32 parameter备份占用 字节fp32 momentum一阶动量占用 字节fp32 variance二阶动量占用 字节
- 共计 字节,其中
Optimizer states占用75%,因此Optimizer states是本文主要想解决的问题
ZeRO-DP 是如何解决模型状态信息占用过大问题的?
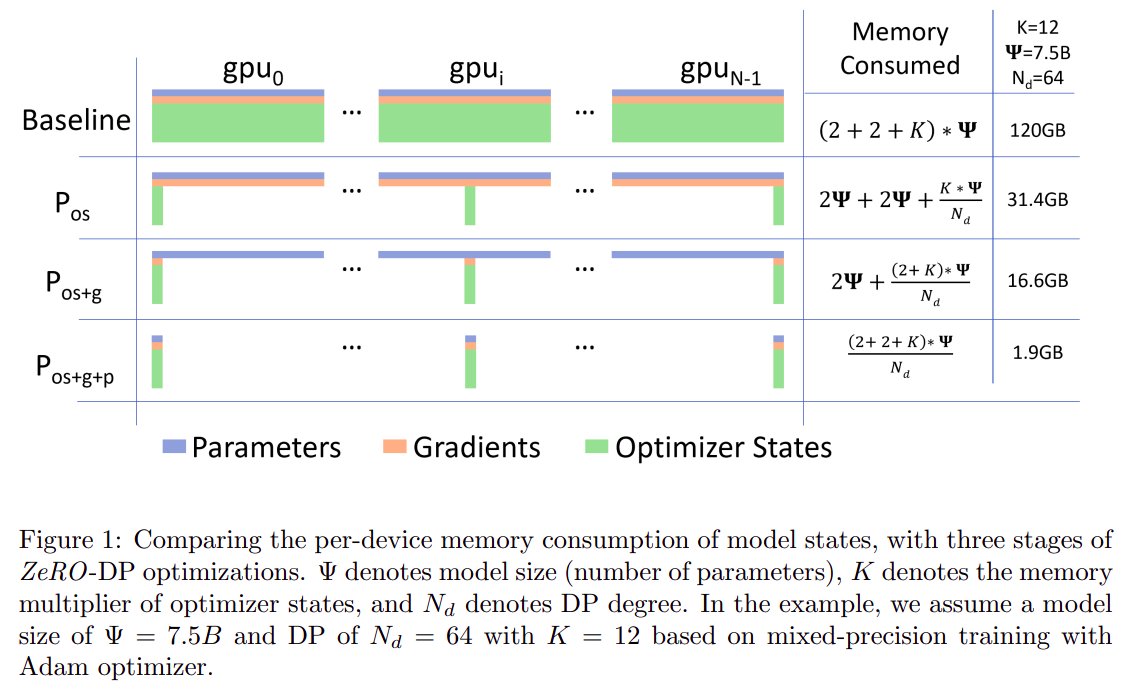
ZeRO-DP的核心思想是Data Parallelism时,每个模型只保留 的模型状态信息,N表示GPU数量,在需要信息聚合时使用Ring Reduce来聚合。- 有三种程度的优化:
- 只删除冗余的优化器状态,所有优化器的信息加起来才是完整优化器状态。
- 删除冗余的优化器状态和梯度。
- 删除冗余优化器状态、梯度和权重。
分块存储 + Ring Reduce 会带来额外的通信代价吗?
All Reduce运算来计算设备间梯度均值(求和)
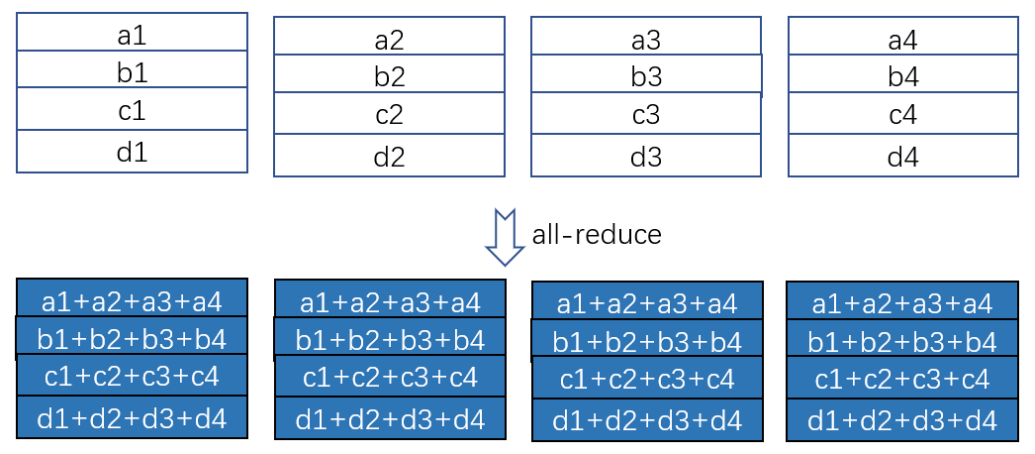
Reduce Scatter来求和,All Gather做broadcast同步到所有设备上
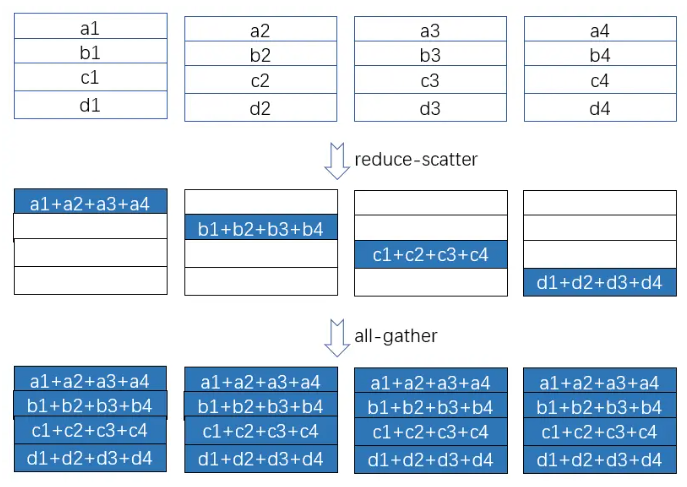
- 使用
Ring Reduce实现Reduce Scatter
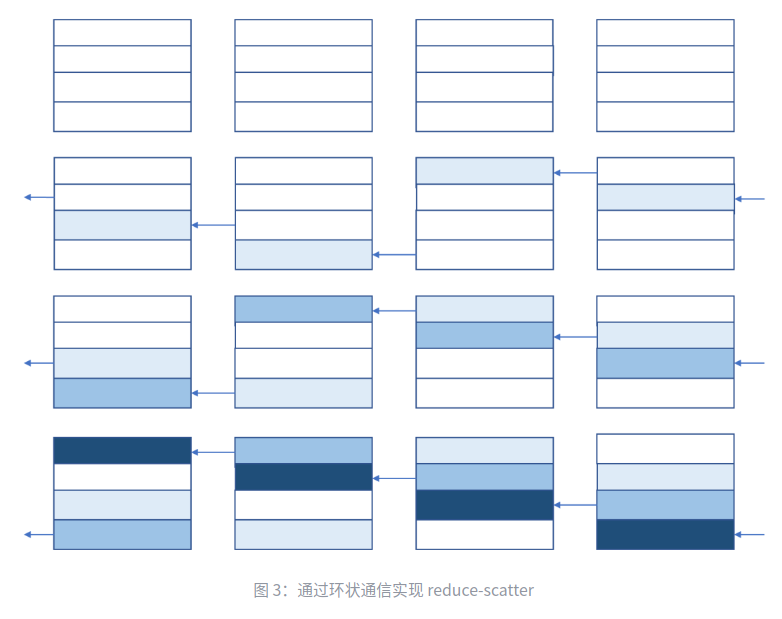
颜色逐渐累积代表梯度累加
- 使用
Ring Reduce实现All Gather做broadcast

深色逐渐蔓延到所有设备,代表
broadcast
- 和 不会带来额外的通信代价, 会
- 证明:
- 传统
Data Parallelism在计算梯度后,需要进行一次All Reduce来计算设备间的梯度均值,All Reduce可分为Reduce Scatter和All Gather两步,每一步实际上都是一次Ring ReduceReduce Scatter如图三所示,把所有设备梯度累加,分散到各个设备上All Gather如图四所示,把分散到各个设备上的梯度累加值同步到所有设备上Ring Reduce是一种理论最优通信算法,每个周期内每个设备的发送和接收都被占用,因此梯度总字节数为 (fp16),由于做了两次Ring Reduce,所以每个设备的通信总字节数为 (发送和接收算一次)
ZeRO-DP也需要通过All Reduce计算设备间梯度均值,也需要Reduce Scatter和All Gather两个步骤,也是通过两次Ring Reduce实现,具体做法和传统Data Parallelism没有什么区别,因此每个设备的通信总字节数也是ZeRO-DP在前向传播时,也需要用All Reduce计算得到全量Parameter,这一步在传统Data Parallelism中并不需要,因此会有额外通信量
- 传统
ZeRO-R
ZeRO-R 想要解决哪些问题?
Tensor Parallelism中Activation冗余存储问题- 临时缓冲区占用问题
- 显存碎片导致无法使用的问题
ZeRO-R 如何解决 Tensor Parallelism 中 Activation 冗余存储问题?
- 是通过激活值检查点分片存储(
Partitioned Activation Checkpointing,简称 )来解决Tensor Parallelism中Activation冗余存储问题。 - 其中的 分片 思想和
ZeRO-DP是一样的,N个设备每个设备只存储 的信息,通过All Reduce进行信息聚合 - 激活值检查点 思想是来自 https://arxiv.org/pdf/1604.06174 这篇论文,实际上是传统前向反向传播过程和
ReCompute前向反向传播过程的折衷,也是空间和时间的折衷。 - 传统前向反向传播过程:存储每个中间算子的前向传播计算结果,用于反向传播计算梯度
ReCompute前向反向传播过程:不存储任何中间算子的前向计算结果,反向传播需要用时重新计算
Activation Checkpointing前向反向传播过程:存储部分中间算子前向计算结果,反向传播需要用时,从拓扑上游最近的检查点开始重新计算
ZeRO-R 如何解决临时缓存区空间占用问题?
- 通常情况下,临时缓存区是用来做数据聚合的,例如
All Reduce操作,模型越大,需要的临时缓存区也越大。 ZeRO-R用了一个非常简单的策略:在模型大到一定程度后,使用固定尺寸的融合缓存区,即常数尺寸缓存区(Constant Size Buffers,简称 )
ZeRO-R 如何解决显存碎片化问题?
- 问:为什么会产生显存碎片化问题?
- 答:因为
Activation Checkpointing的存在,不同的Activation有不同的生命周期,非checkpoint的Activation用完即弃,checkpoint的Activation需要反向传播之后才可以丢弃,不同生命周期的存储空间交织就会出现显存碎片 - 问:显存碎片化会带来什么问题?
- 答:显存碎片化通常会有两个问题:
- 大量的碎片无法使用,使得实际空间占用不多,但出现
OOM - 大量存储碎片会导致系统在分配内存时需要大量的搜索来找到合适的空间,会带来额外耗时
- 大量的碎片无法使用,使得实际空间占用不多,但出现
- 问:那
ZeRO-R如何解决显存碎片化问题? - 答:预先给不同生命周期的
Activation划分不同的存储空间,避免产生交织。例如:把显存划分成两段连续的存储空间,其中一段存储Checkpoint Activation另外一段存储Temporary Activation。
Thought
- 当大模型时代到来,算力和存储不够用了,大家也开始审视之前做的东西是不是时间/空间低效的,是不是还能榨点油水。