0%
URL
TL;DR
- 大模型预训练后,在很多任务上已有非常强的能力,但输出的结果可能是不可信、有害或无帮助的。
- 本文提出
InstructGPT 算法和微调流程,旨在让大模型通过人类反馈的微调方式,在大量任务上对齐人类意图。
- 目标是做到
3H:
Algorithm
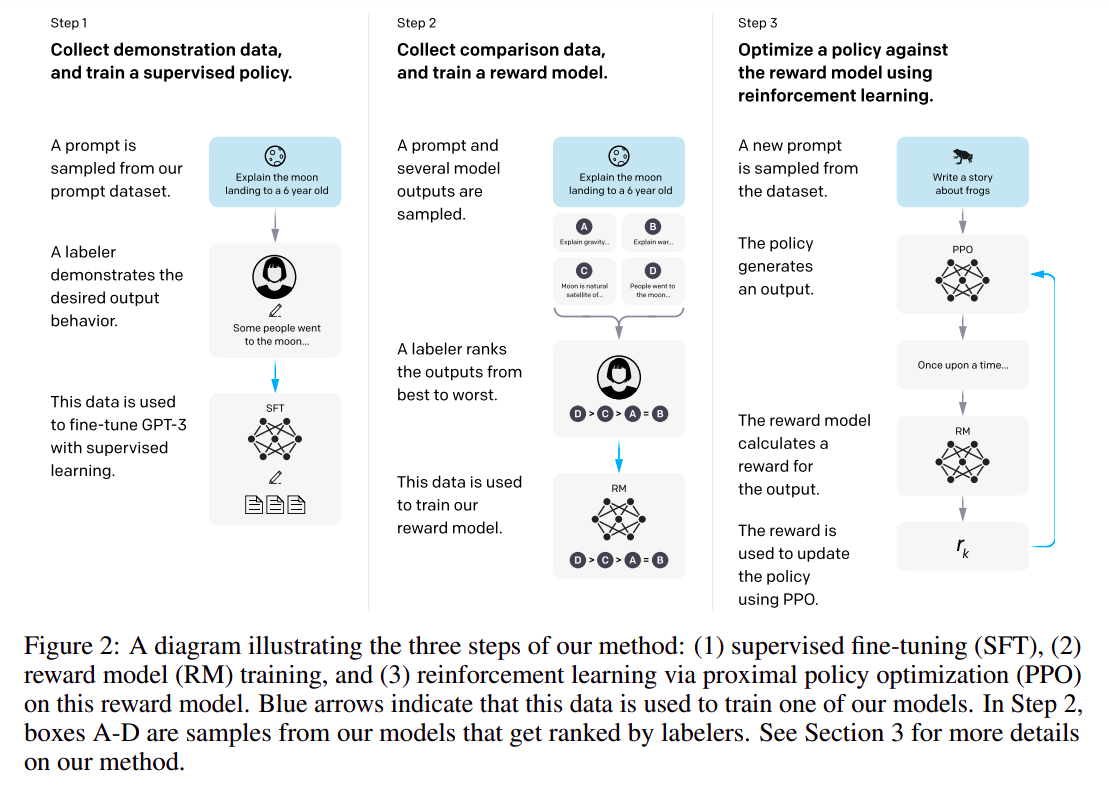
- 具体来说,
InstructGPT 微调分为三步:
- 根据采集的
SFT (Supervised FineTune) 数据集对 GPT-3 进行有监督的微调;
- 收集人工标注的 对比数据,训练奖励模型
RM (Reword Model);
- 使用
RM 作为强化学习的优化目标,利用 PPO 算法(Proximal Policy Optimization 最近策略优化)微调 SFT 模型。
数据集
1. SFT 数据集
SFT 数据一部分来自使用 OpenAI 的 PlayGround 的用户,另一部分来自 OpenAI 雇佣的 40 名标注工。- 在这个数据集中,标注工的工作是根据内容自己编写指示,并且要求编写的指示满足下面三点:
- 简单任务:
labeler 给出任意一个简单的任务,同时要确保任务的多样性;
Few-shot 任务:labeler 给出一个指示,以及该指示的多个查询-响应对;- 用户相关的:从接口中获取用例,然后让
labeler 根据这些用例编写指示。
2. RM 数据集
RM 数据集是对比数据类型,用于训练一个奖励模型(Reward Model)。InstructGPT/ChatGPT 的做法是先让模型生成一批候选文本,让后通过 labeler 根据生成数据的质量对这些生成内容进行排序。- 具体做法是对于每一个
Prompt,模型给出 K 个候选输出(4≤K≤9),然后将 K 个输出中挑选 2 个样本给 labeler,labeler 给出哪个更好,一个 Prompt 一共需要 labeler 标注 CK2 次,最终得到 K 个候选输出的排序结果。
3. PPO 数据集
InstructGPT 的 PPO 数据没有进行标注,它均来自 GPT-3 的 API 用户。- 有不同用户提供的不同种类的生成任务,其中占比最高的包括生成任务(
45.6%),QA(12.4%),头脑风暴(11.2%),对话(8.4%)等。
微调过程
1. SFT 有监督微调过程
- 和
GPT-3 的预训练过程保持一致,只是监督信号从监督一段文本中下一个 token 变成监督模型对 prompt 输出和 ground truth 之间的差异。
2. Reward Model 训练过程
Reward Model 的输入是 Prompt + Response,输出是对应的奖励值,是个回归模型,其中 Response 是 RM 数据集中的排序的模型候选输出。Reward Model 实际上是原始 LLM 模型将最后一层的分类层改成回归层,用来回归奖励值。- 损失函数是:loss(θ)=−CK21E(x,yw,yl)∼D[log(σ(rθ(x,yw),rθ(x,yl)))],使用对比学习的方式训练。
- 其中:
- rθ 表示参数为 θ 的
Reward Model
x 表示 Prompt- yw ,yl 分别表示对
Prompt x,labeler 喜欢和不喜欢的一对 Response
3. 使用近端策略优化强化学习算法(PPO) + Reward Model 继续优化 SFT 模型
InstructGPT/ChatGPT 的分析和计划
1. 收益
- 效果比
GPT-3 更加真实
- 在模型的无害性上比
GPT-3 效果要有些许提升
- 具有很强的
Coding 能力
2. 损失
- 会降低模型在通用
NLP 任务上的效果
- 有时候会给出一些荒谬的输出
- 模型对指示非常敏感
- 模型对简单概念的过分解读
- 对有害的指示可能会输出有害的答复
3. 未来计划
- 人工标注的降本增效:将人类表现和模型表现有机和巧妙的结合起来是非常重要的
- 模型对指示的泛化/纠错等能力:这不仅可以让模型能够拥有更广泛的应用场景,还可以让模型变得更“智能”
- 避免通用任务性能下降:需要方案来让生成结果的
3H 和通用 NLP 任务的性能达到平衡
Thought
- 在
ChatGPT 爆发之前,Open-AI 多年来一直在默默研究这个领域,包括 GPT 系列、RLHF、PPO 等,这些东西的有机结合就成了 InstructGPT,放大就变成了 ChatGPT(InstructGPT 是基于 GPT-3 对齐的,ChatGPT 是基于 GPT-3.5 对齐的)
- 想在一个领域做到断崖式的领先,小聪明是没用的,需要长期积累 + 修炼内功