URL
- paper: https://arxiv.org/pdf/1707.06347
- code: https://github.com/ikostrikov/pytorch-a2c-ppo-acktr-gail (民间实现)
TL;DR
- 本文提出一种强化学习算法
PPO(Proximal Policy Optimization,近端策略优化),旨在解决传统策略梯度方法中存在的数据效率低、鲁棒性差等问题。 PPO对TRPO(Trust Region Policy Optimization,信任域策略优化)进行了简化。
Algorithm
1. 算法核心思想
策略梯度方法
PPO基于策略梯度方法,通过估计策略的梯度并使用随机梯度上升来优化策略。
裁剪概率比
PPO引入了裁剪概率比(clipped probability ratio)的概念,通过对概率比进行裁剪,限制策略更新的幅度,从而避免过大的策略更新导致的性能下降。
近端目标函数
PPO使用近端目标函数(surrogate objective function),它是一个关于策略参数的函数,用于在策略更新时进行优化。- 这个目标函数考虑了策略更新前后的概率比和优势函数(
advantage function)的乘积,并通过裁剪概率比来调整这个乘积,使得策略更新更加稳健。
多轮更新
- 与传统的策略梯度方法每次只使用一个数据样本进行一次梯度更新不同,
PPO允许对每个数据样本进行多轮(epochs)的梯度更新,提高了数据的使用效率。
简化实现
- 相比于
TRPO等算法,PPO的实现更加简单直观,易于与其他算法和框架集成。
2. 伪代码实现

- 在每次迭代中,多个
actor并行地在环境中运行旧策略 ,收集数据并计算优势估计。 - 然后,使用这些数据来优化近端目标函数,通常使用
K epochs(重复使用收集到的数据更新K次) 和SGD或Adam优化器来进行优化。 - 优化完成后,更新策略参数 ,并在下一次迭代中使用新的策略。
3. 公式分析
PPO的目标函数公式分为三部分:- 裁剪的目标函数(
CLIP),在时间步t的裁剪目标函数,用于优化策略参数 - 价值函数损失(
VF, value function) - 策略熵(
S, entropy bouns),用于鼓励探索。
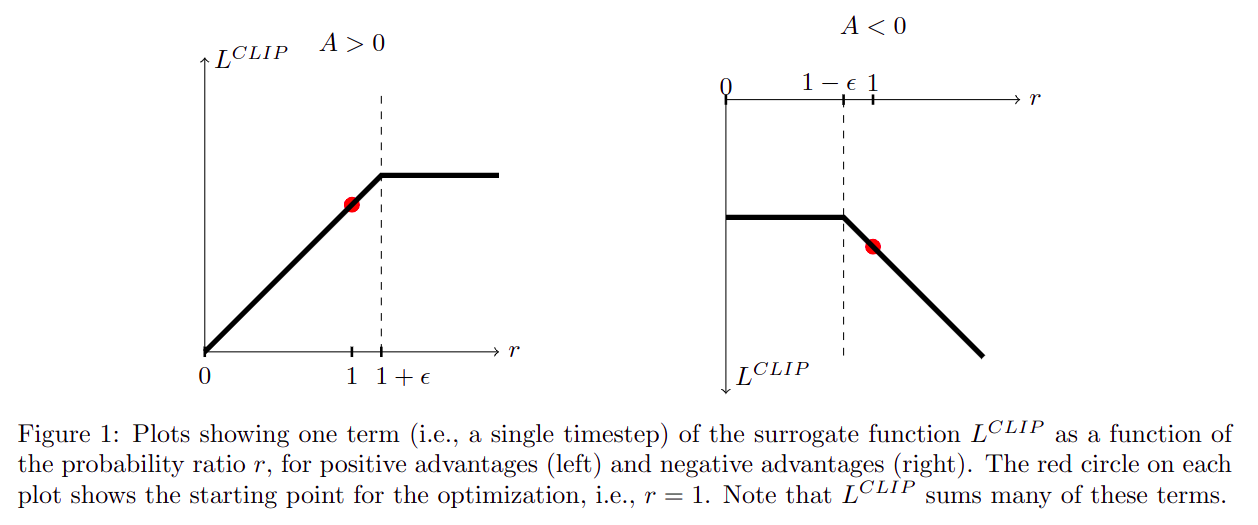
- 裁剪的目标函数(
裁剪概率比的优势
-
- ,
- :概率比率表示新旧策略在状态
s下采取动作a的概率之比 - :在状态
s下采取动作a的概率,有策略参数 决定的随机策略 - :在策略更新前,状态
s下采取动作a的概率 - :超参数,用于控制裁剪的严格程度
- :优势函数(
advantage function)的估计值,它估计了采取行动a相比于平均状况能带来多少额外回报
- :概率比率表示新旧策略在状态
-
- :策略参数 下,状态
s的期望回报,V表示价值函数 - :折扣回报的估计
- 价值函数损失有助于确保价值函数的预测尽可能接近真实回报,从而为策略提供准确的价值估计
- :策略参数 下,状态
-
- 表示在状态
s下,根据策略 采取动作的熵 - 熵是衡量随机性的一个指标,策略的熵越高,表示策略在选择动作时越随机,这有助于算法探索更多的状态-动作空间
- 表示在状态
- ,
Thought
- 对强化学习了解不够深,无法完全
get到PPO的精髓 InstructGPT / ChatGPT使用了PPO强化学习策略,所以做LLM需要掌握此技能