0%
URL
TL;DR
- 本文提出一种
Prompt Tuning 的方法 P-Tuning
- 和
Prefix Tuning 与 Prompt Tuning 这种连续词嵌入作为前缀的方法不同, P-Tuning 把连续词嵌入分段插入到 输入 和 标签 之间
Algorithm
提出问题
- 模型对人工设计的
Prompt 很敏感(指预训练模型,非大模型),同一个模型同一个数据集,只要稍微改变问题的问法,评测指标就差非常多,如图:
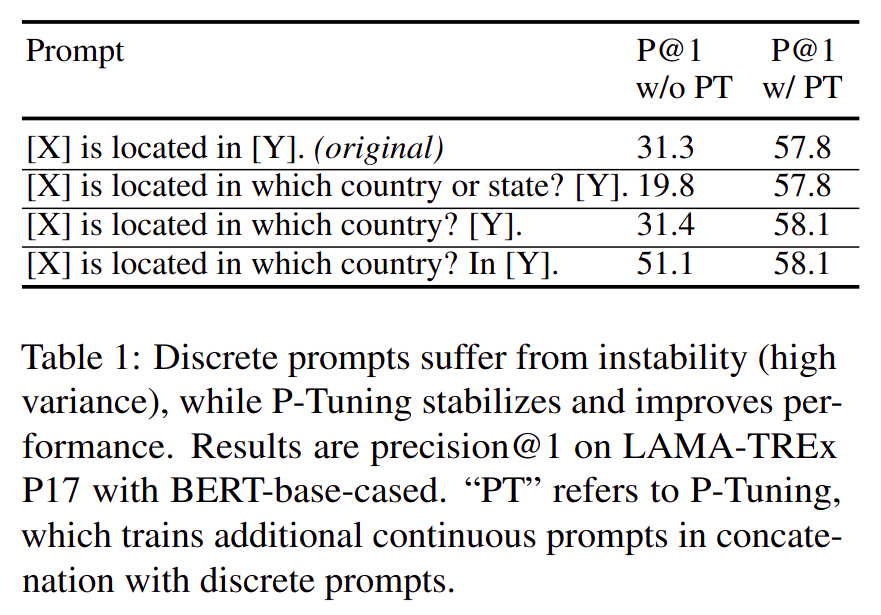
- 用
P-Tuning 可解决此类问题
解决问题
- 使用连续词嵌入(可训练)和离散词嵌入(不可训练)相结合的方法,做
Prompt Tuning 微调
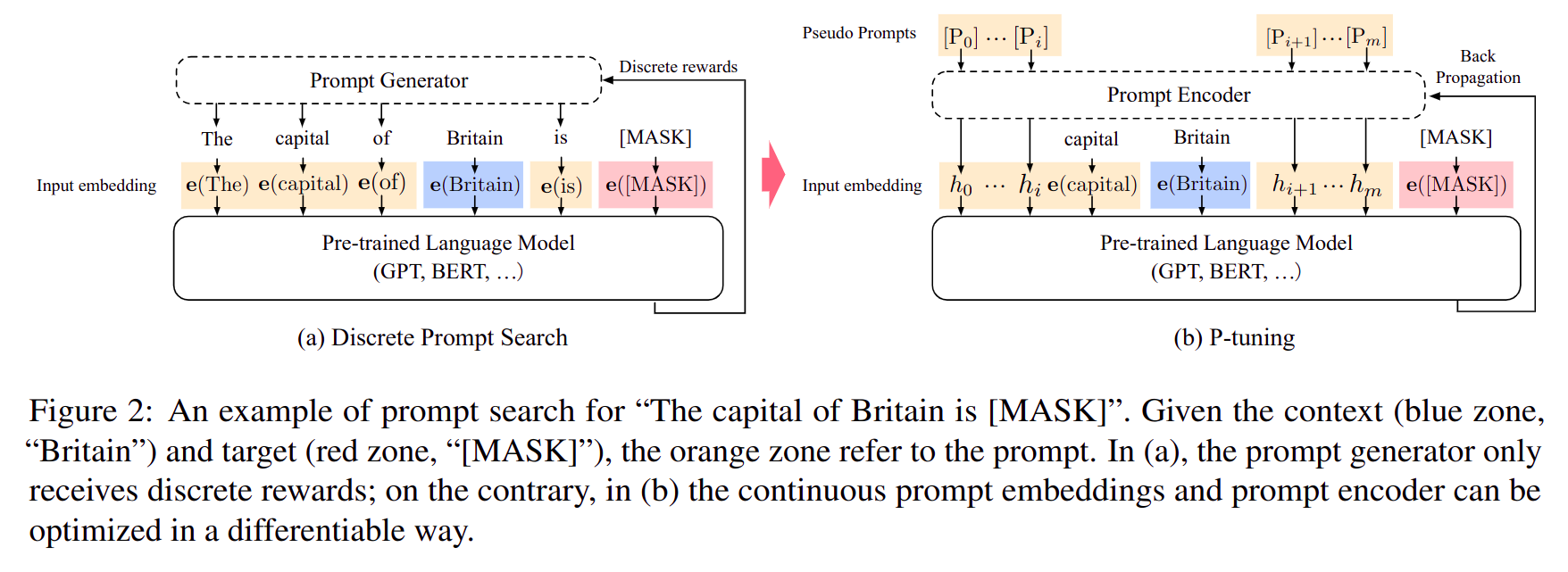
- 上图左侧是传统全部用离散词嵌入
Prompt 过程
- 上图右侧是离散词嵌入和连续词嵌入相结合的方法,其中
captical 和 Britain 两个问题中最关键的词使用离散词嵌入(来自于词表,固定不可训练),并在离散词嵌入周围插入若干连续词嵌入(可通过反向传播梯度下降训练)
数学表述
P-Tuning 中输入序列为 T={[P0:i],x,[P(i+1):j],y,[P(j+1),k]},其中:
x 表示原始输入的离散词文本(还没有变成词向量)y 表示原始的 label 文本- [P] 表示连续词向量
- 输入序列
T 需要通过一种特殊的 Prompt Encoder 变成真实的词嵌入输入 {h0,...,hi,e(x),hi+1,...,hj,e(y),hj+1,...,hk},其中:
- e(x),e(y) 是通过查词表得到的离散词嵌入
- h 是通过
MLP/LSTM 等方法得到的连续向量的词嵌入,向量的长度和离散词嵌入一致
Thought
- 比
Prefix Tuning 插入连续词嵌入的自由度更高,因此理应效果更好,但总感觉解决问题的方法不优雅,因为离散和连续嵌入结合的模板是人为规定的,包含了较多先验知识在里面