0%
URL
TL;DR
- 本文提出一种提示词微调的方法,是对
P-Tuning 的升级
P-Tuning v2 要解决的问题是:对于所有(或大多数)任务类型和模型参数规模,将提示词微调的精度达到和整体参数微调同样的效果,这也是这篇论文的题目
Algorithm
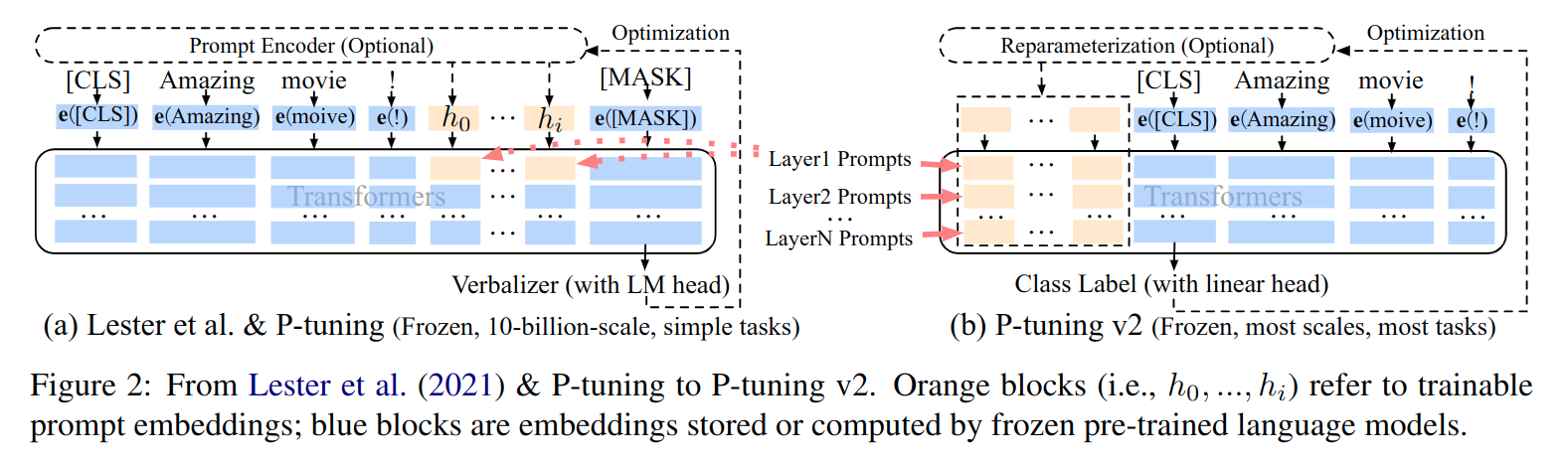
对 P-Tuning 的优化
1. P-Tuning 只在模型输入层添加可学习的连续嵌入,P-Tuning v2 在模型的每一层都添加
Prefix Tuning / Prompt Tuning / P-Tuning 三种方法都是在模型输入中加入连续嵌入
- 添加方式可能是前缀,也可能是其他
Concat Pattern
- 通过
Self-Attention 的 embedding 间信息融合机制让虚拟连续嵌入影响整个模型
P-Tuning V2 的做法则完全不同,是对模型的 每一层 都添加了可学习的虚拟连续嵌入
- 具体来说是通过初始化虚拟
past_key_values 来实现的
- 用
GPT2-small 来举例(12 层 transformer,每层 12 个头,每个头的 dim = 64)
- 假设
virtual_prompt_seq_len=3,input_prompt_seq_len=10
- 那么需要先初始化
past_key_values,shape = [12, 2, 12, 3, 64],分别表示:
num_layerskey and valuenum_headsvirtual_prompt_seq_lendimshape = [12, 2, 12, 3, 64] 以及修改后的输出层参数是可训练的所有参数
- 然后将序列长度为
10 的 input token embeddings 输入模型,第一层输出长度还是 10
- 第二层以及之后的每一层都将上一层输出的长度为
10 的序列和长度为 3 的 virtual_prompt_key_values 合并计算,并输出长度为 10 的序列
2. 不再使用 Verbalizer,而是使用 class head
- 什么是
Verbalizer ?
- 传统的预训练语言模型(例如
Bert)的输入是一个 token 序列,输出是一个 token,也就是说词表中每个词都有可能输出
- 现在有个下游任务需要用
Bert 做情感分类,输入是一段话,输出是:{正面,负面,中性} 中的一种,而且用 P-Tuning 方法微调,那么直接把输入附加上一些虚拟连续提示嵌入,输出的结果还是整个词表,不是三分类
- 这时候就需要
Verbalizer 的存在了,它的作用是将 Bert 模型的输出从词表空间映射到三分类空间,它的实现形式可以是规则,也可以是深度学习模型
P-Tuning V2 如何抛弃 Verbalizer?
- 抛弃
Verbalizer 的方式很简单,就是打破 Prompt Tuning 模型时不应修改模型参数和结构 的限制
- 直接删除预训练模型输出层,改成任务相关的层并随机初始化,然后微调
Thought
- 看起来比
P-Tuning v2 更优雅,和 kv cache attention 结合起来,推理耗时增加较小
- 据说对大模型来讲,这种方法和
Prompt Tuning 相比并没有显著精度优势(模型参数量小时,设计很重要;模型参数量大时,参数量几乎可以弥补一切设计上的非最优)