0%
URL
TL;DR
CLIP 是 OpenAI 提出的一种图文多模态对齐算法,在收集到的 4 亿对图片文本数据对上,将文本和图像编码在同一表达空间下,实现了图文模态的对齐- 可以
zero-shot 迁移到其他计算机视觉任务上
Algorithm
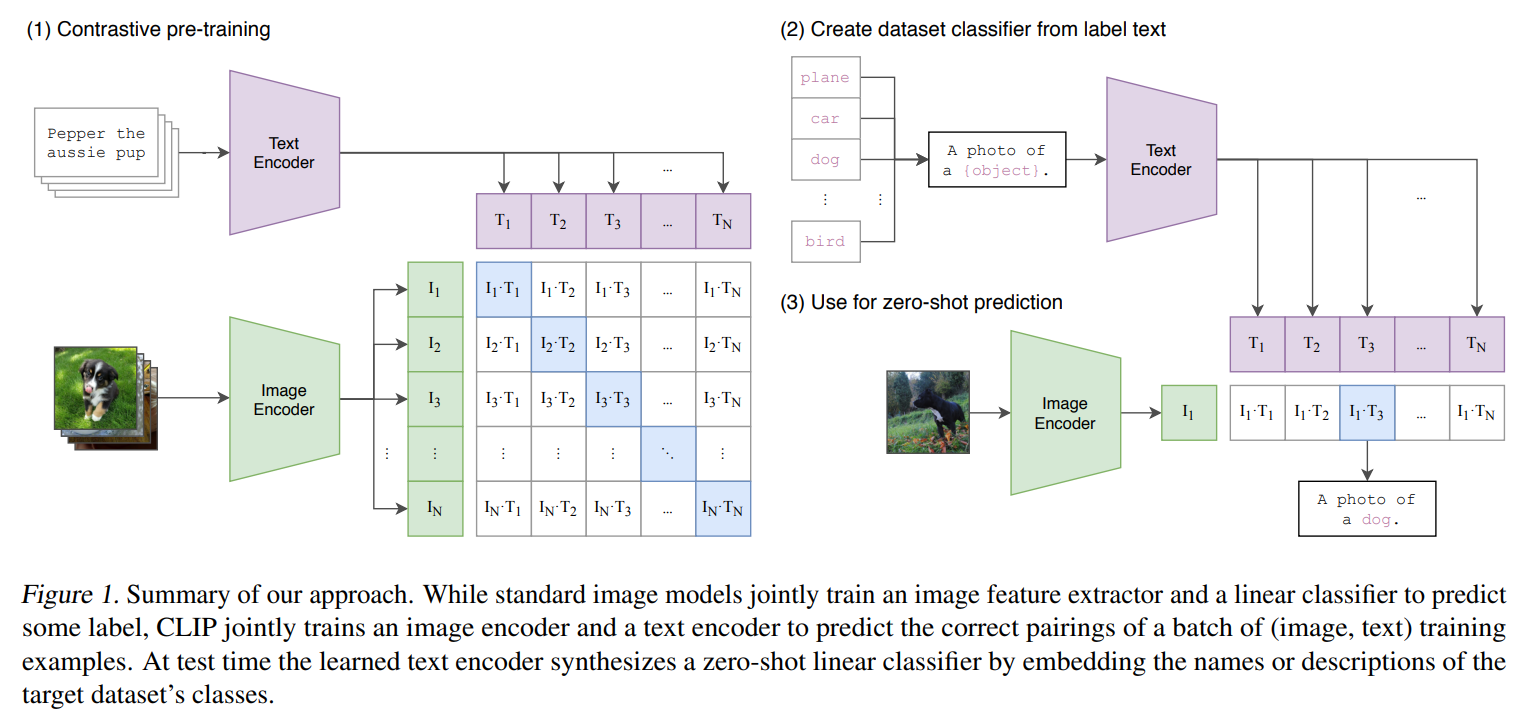
训练时
N 对图片和文本各自编码- 计算得到不同模态之间两两编码的 余弦相似度 ∈RN×N
- 使用对比学习的方式,提高
N 个正样本的相似度,降低剩余的 N2−N 个样本的相似度
推理时(以 ImageNet 分类任务为例)
- 将
ImageNet-1k 的所有 1000 种类别标签,通过训练好的文本编码器,转换到特征空间中
- 将需要分类的图片,通过训练好的图片编码器,转换到特征空间中
- 图像编码找到余弦相似度最高的文本编码,对应的类别就是图片类别
模型选型
- 图像编码器:
Vision Transformer (ViT)ResNet-50
- 文本编码器:
Transformer
63M 参数12 层512 宽49152 词表大小BPE 文本编码方式
Thought
- 简洁高效,像
OpenAI 固有的风格
- 有没有可能在
GPT-4 的多模态中用到呢?