0%
URL
TL;DR
DINO(Distillation with No Labels) 是一种自监督学习方法,主要用于 Vision Transformer (ViT) 的训练- 在无标签的图片数据上训练模型,让模型学习图像的表示意义
- 利用
MoCo 提出的 Momentum Teacher 算法做蒸馏
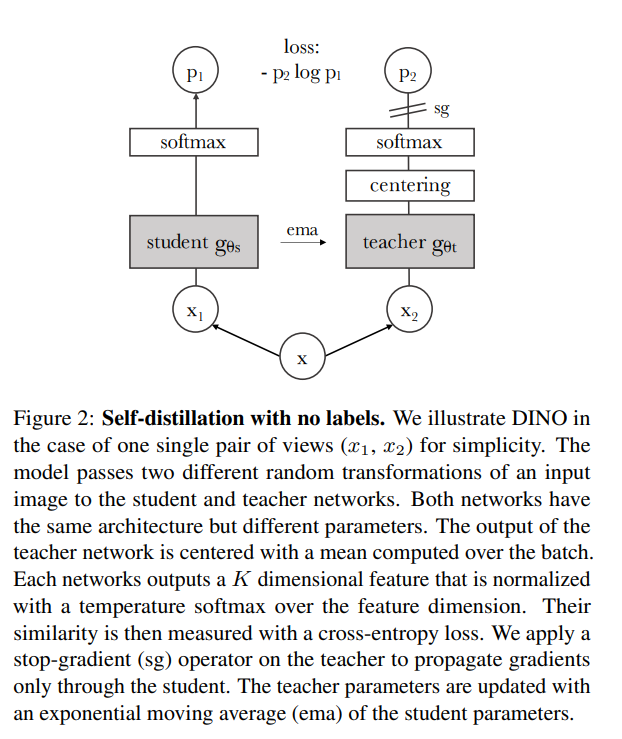
Algorithm

训练流程
- 创建两个完全一样的网络,命名为教师
teacher 网络和学生 student 网络
- 对同一个输入
x,进行不同的数据增强,得到 x1 和 x2
- 交叉计算对比损失,再求均值得到
loss for student
- 只对
student 网络进行反向传播和梯度更新
- 基于
student 网络的参数更新 teacher 的参数,更新方式是 EMA (exponential moving average),即:θt=λθt+(1−λ)θs
- 更新
teacher 网络输出的中心点:C=m∗C+(1−m)∗mean(t1,t2)
中心化和锐化
中心化(centering)
- 中心化的目的是防止特征向量的某个维度占主导地位,从而导致模型输出分布过于集中
- 本质就是一种均值为
0 的归一化,可以提高模型训练的稳定性
锐化(Sharpening)
- 锐化操作的目的是增加教师网络输出的概率分布的锐度,使得输出的概率更加集中在少数几个维度上
- 实现上,锐化通过修改蒸馏温度系数实现
模型效果
- 比一众视觉自监督模型效果都好,比如:
MoCo v1/v2,SimCLR v1/v2 等
Thought
- 感觉是
MoCo 系列的升级,框架本身不变,加了数据,稳定了训练过程,增加了些许 trick