0%
URL
TL;DR
- 和
DINO 一样,都是做自监督视觉预训练的,对于 DINO 的主要升级是构建了一个大规模自动化数据处理管线,构建了 LVD-142M 高质量数据集
- 用这些数据集预训练了一个
1B 参数的 ViT 模型,通过无监督蒸馏的方式,得到用于不同任务的小模型
Algorithm
自动化数据处理管线
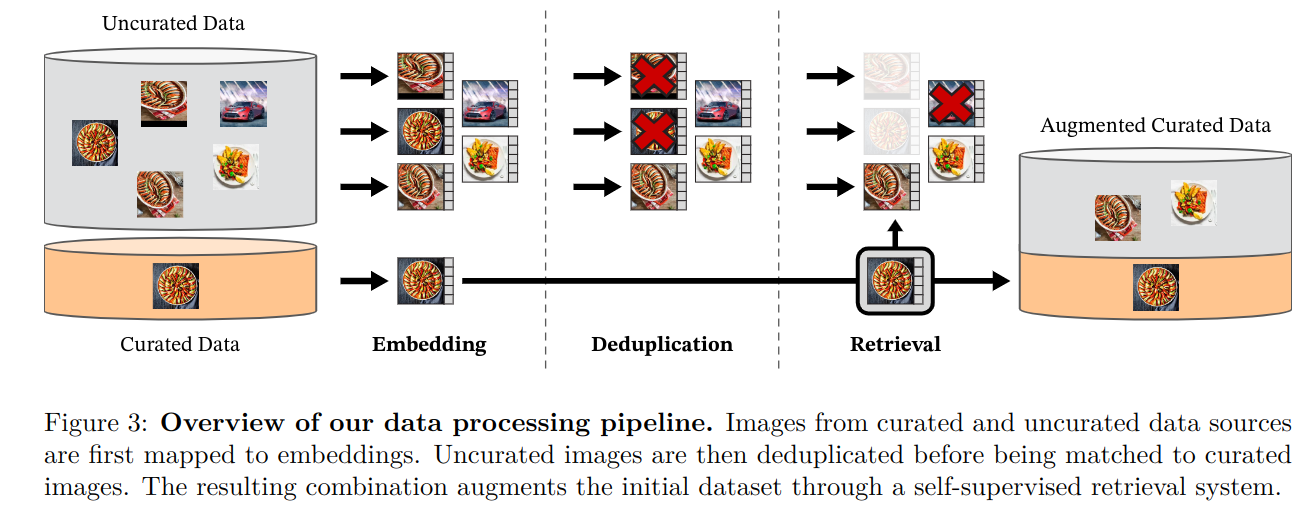
1. 数据收集
DINOv2 的数据源包括一个大型的未筛选图像数据集和一个较小的经过筛选的图像数据集- 未筛选数据集来自网络爬取
- 筛选数据集来自
ImageNet-22k / Google Landmarks 等
2. 图像嵌入
- 对于未筛选数据集,用一个训练好的
ViT-H/16 计算得到图像 embedding vector
3. 图像去重
4. 图像检索
- 在特征空间下聚类,得到与筛选数据集类似的未筛选数据样本
5. 数据增强
- 让这些聚类得到的类似的未筛选样本作为筛选样本,不断扩大筛选样本的数量和场景丰富度
模型架构
- 和
DINO v1 中教师和学生使用动量更新的方式不同,DINO v2 使用了常见的 “大老师,小学生” 架构
- 先训练一个
1B 参数的 ViT 模型作为老师模型
- 然后再在各个不同任务数据上蒸馏得到小模型
训练策略优化
- 由于老师模型很大(
1B 参数量),所以需要 LM 常用的训练加速方法,包括:
FlashAttentionFully-shared Data Parallel (FSDP) 等
Thought
- 这套数据处理管线是本文重点,所有的自监督任务,自动化数据处理流程都是必不可少的