URL
TL;DR
- 本文提出一种跨模态开放集目标检测算法,即:输入一张图片 和 需要检测内容的文本描述,给出框
- 其中文本描述可以是开放的(任意内容的文本)
- 本文最重要的部分是模型结构中图文多模态内容的融合
Algorithm
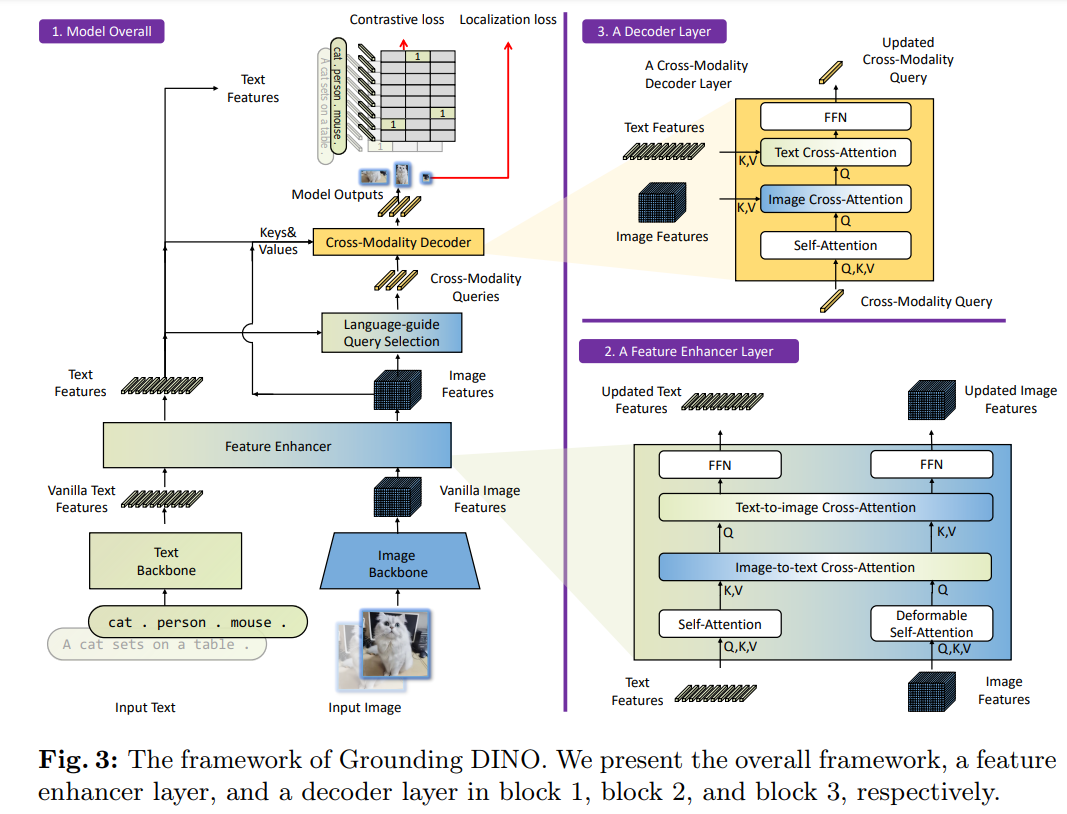
- 本质是通过多次
Cross-Attention来做多模态信息融合 text backbone实际是BERTimage backbone实际是SwinTransformer- 其中的
Language-guide Query Selection是根据文本特征,找到图像特征中最匹配的部分初始化跨模态解码器
Thought
- 这篇论文想要解决的任务时开放集目标检测,但其多模态信息融合方式让其出圈,成了多模态领域的经典