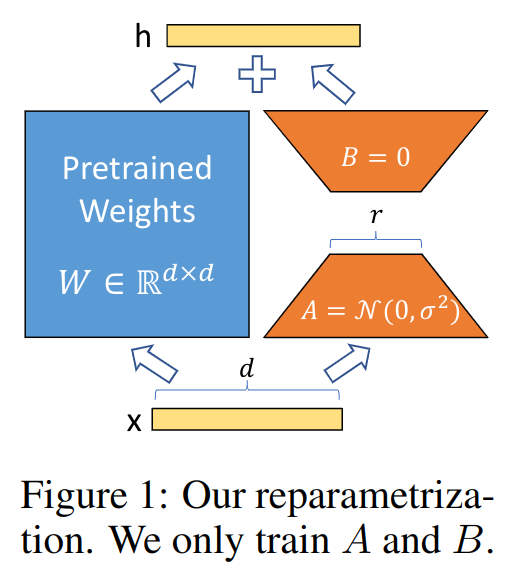
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
| import torch
import torch.nn as nn
class LoRALinear(nn.Module):
def __init__(self, in_features, out_features, r):
super(LoRALinear, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.r = r
self.weight = nn.Parameter(torch.randn(out_features, in_features))
self.bias = nn.Parameter(torch.zeros(out_features))
self.A = nn.Parameter(torch.randn(r, out_features))
self.B = nn.Parameter(torch.zeros(in_features, r))
def forward(self, x):
output = torch.matmul(x, self.weight) + self.bias
output = output + torch.matmul(x, torch.matmul(self.B, self.A))
return output
def convert_to_standard_linear(self):
self.weight = nn.Parameter(self.weight + torch.matmul(self.B, self.A))
del self.A
del self.B
return self
class LoRATransformerLayer(nn.Module):
def __init__(self, d_model, r):
super(LoRATransformerLayer, self).__init__()
self.d_model = d_model
self.r = r
self.Wq = LoRALinear(d_model, d_model, r)
self.Wk = LoRALinear(d_model, d_model, r)
self.Wv = LoRALinear(d_model, d_model, r)
self.Wo = nn.Linear(d_model, d_model)
def forward(self, x):
q = self.Wq(x)
k = self.Wk(x)
v = self.Wv(x)
attn_scores = torch.matmul(q, k.transpose(-2, -1)) / (self.d_model**0.5)
attn_weights = torch.softmax(attn_scores, dim=-1)
attn_output = torch.matmul(attn_weights, v)
output = self.Wo(attn_output)
return output
def convert_to_standard_transformer(self):
self.Wq = self.Wq.convert_to_standard_linear()
self.Wk = self.Wk.convert_to_standard_linear()
self.Wv = self.Wv.convert_to_standard_linear()
return self
d_model = 512
r = 8
layer = LoRATransformerLayer(d_model, r)
input_tensor = torch.randn(10, 32, d_model)
output_tensor = layer(input_tensor)
print(output_tensor.shape)
standard_layer = layer.convert_to_standard_transformer()
print(standard_layer)
|