URL
- paper: https://link.springer.com/article/10.1007/BF00992696
- code: https://gymnasium.farama.org/tutorials/training_agents/reinforce_invpend_gym_v26/
- doc: https://gymnasium.farama.org/environments/mujoco/inverted_pendulum/
TL;DR
- 本博客是从零开始学习强化学习系列的第一篇,重点在于介绍强化学习的基础概念。主要介绍了
REINFORCE算法的基本原理,并用REINFORCE算法训练Agent玩倒立摆游戏 REINFORCE算法是一种基于梯度的策略优化算法,提出时间是1992年,算是强化学习的基础算法之一- 倒立摆游戏是一个非常简单的强化学习环境,但是可以很好地展示
REINFORCE算法的效果
Algorithm
1. 强化学习基础
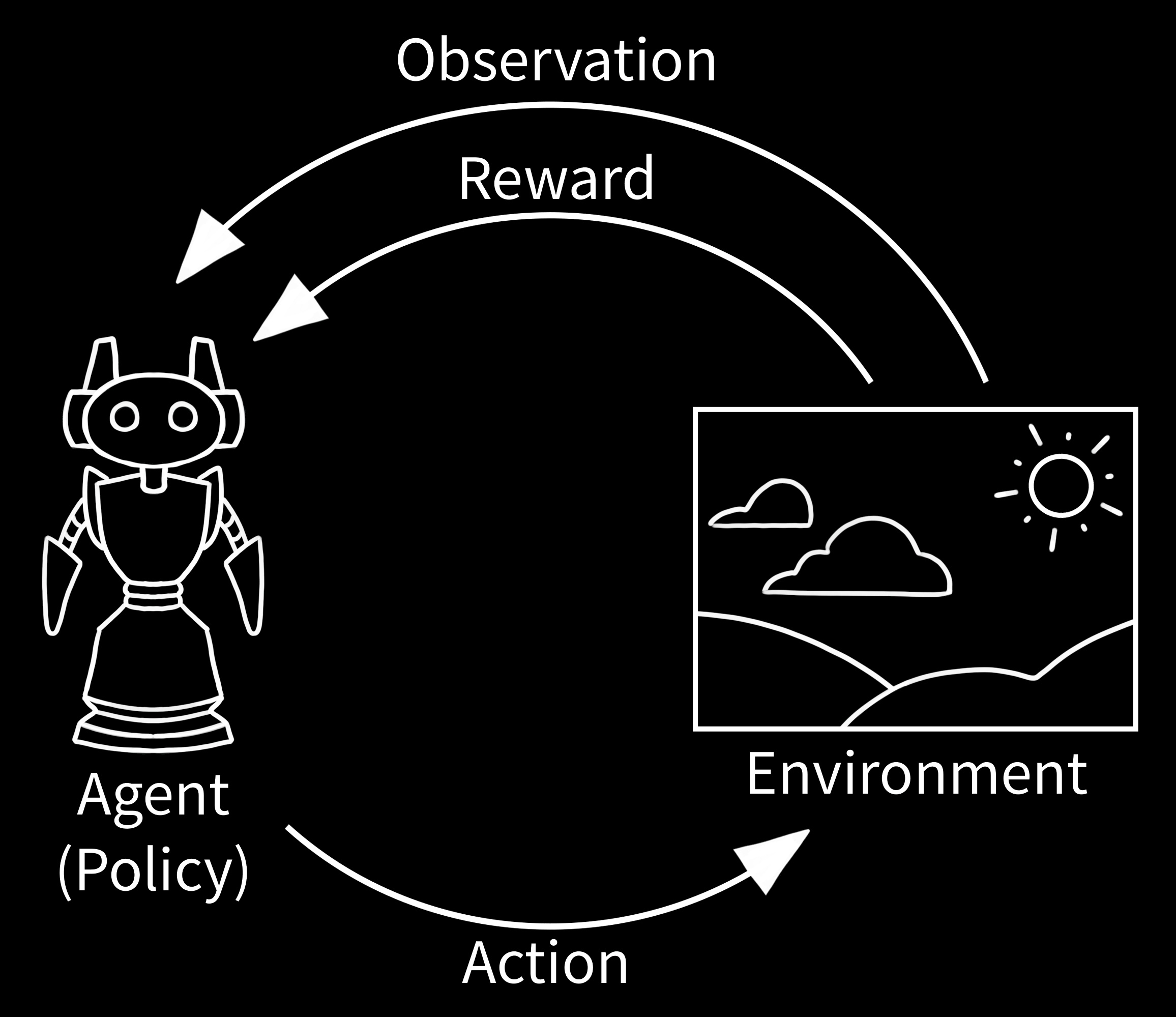
- 强化学习的基本流程如上图所示,主要包括:
Agent:智能体,即我们要训练的模型Environment:环境,即智能体需要与之交互的环境,比如倒立摆游戏State:状态,也被称为Observation(观测) 即环境的状态,比如倒立摆的角度Action:动作,即智能体在某个状态下可以采取的动作,比如向左或向右Reward:奖励,即智能体在某个状态下采取某个动作后得到的奖励,比如倒立摆保持平衡时给予正奖励Policy:策略,是智能体的核心部分,即智能体在某个状态下采取某个动作的概率分布,智能体需要根据策略来选择动作
2. 倒立摆游戏

- 上图是用强化学习实际学习得到的倒立摆游戏效果,目标推动小车让杆尽可能竖直,这个游戏在
Gymnasium库中,被定义为:- Observation Space:
Box(-inf, inf, (4,), float64),观测状态用一个长度为4的向量表示,每个元素的取值范围为任意实数,其中每个维度数值的含义如下:- 小车的位置
- 小车上杆子的垂直角度
- 小车的速度
- 小车上杆子的角速度
Action Space:Box(-3.0, 3.0, (1,), float32),动作空间为[-3, 3]之间的一个浮点数,表示智能体推小车的力(带方向)Reward:目标是使倒立摆尽可能长时间直立(在一定角度限制内),因此,当杆直立的每个时间步都会获得+1的奖励Starting State:起始状态为(0, 0, 0, 0),然后随机施加[-0.01, 0.01]的均匀随机噪声Episode End:一次游戏结束,判定条件为:Truncation:游戏累积1000个时间步Termination:状态空间中元素出现无穷 或 立杆的垂直角度大于0.2弧度(约11.5度)
- Observation Space:
3. REINFORCE算法
REINFORCE算法是一种基于策略梯度的强化学习算法,其核心思想是通过采样得到的轨迹来估计策略梯度,并通过梯度上升的方法来优化策略
3.1 从公式角度讲
- 具体步骤如下:
- 初始化策略:随机初始化策略参数
- 采样轨迹:在当前策略 下采样一条轨迹(状态、动作、奖励在时间维度上组成的序列)
- 计算累积回报:对于轨迹中的每个时间步 ,计算从时间步 开始的累积回报 ,其中 是折扣因子
- 计算累积回报期望:计算轨迹中每个时间步的累积回报期望
- 更新策略参数:根据轨迹中的状态、动作和回报,计算策略梯度 ,并使用梯度上升法更新策略参数 ,其中 是学习率
- 通过不断重复上述步骤,策略会逐渐优化,使得智能体在环境中的表现越来越好
REINFORCE算法的优点是简单易实现,但缺点是方差较大,收敛速度较慢- 代码实现可以参考 Gymnasium 教程
3.2 从实现代码角度讲
- 构建
Policy:- 构成:
Policy是一个MLP网络 - 输入:
State(一个长度为4的浮点数向量) - 输出:两个标量,分别表示正态分布的均值和标准差
- 构成:
- 构建
Agent:- 构成:一个
Agent包含一个Policy以及对此Policy的使用和更新方法 - 使用:即如何使用
Agent根据当前状态选择动作 - 更新:即如何根据环境的反馈(奖励)更新
Policy的参数
- 构成:一个
- 训练
Agent(Agent和Env交互):- 初始化
Agent和环境 - 采样轨迹:在当前策略下采样动作,形成一条轨迹
- 计算回报:计算轨迹中每个时间步的回报
- 更新策略:根据策略梯度更新策略参数
- 重复上述步骤直到策略收敛
代码实现:
- 初始化
1 | import random |
重点代码分析:
Policy预测采样动作的均值和标准差:1
2
3
4
5shared_features = self.shared_net(x.float())
action_means = self.policy_mean_net(shared_features) # 直接预测采样动作的均值
action_stddevs = torch.log(
1 + torch.exp(self.policy_stddev_net(shared_features))
) # 预测采样动作的标准差,保证标准差为正- 采样动作:
1
2
3distrib = Normal(action_means[0] + self.eps, action_stddevs[0] + self.eps) # 根据 Policy 预测的均值和标准差构建正态分布
action = distrib.sample() # 从正态分布中采样动作
prob = distrib.log_prob(action) # 同时计算采样动作的概率,用于后续计算策略梯度来更新策略 - 更新策略:
1
2
3
4
5
6
7
8running_g = 0
gs = []
for R in self.rewards[::-1]:
running_g = R + self.gamma * running_g
gs.insert(0, running_g)
deltas = torch.tensor(gs) # 计算折扣累积回报
log_probs = torch.stack(self.probs)
loss = -torch.sum(log_probs * deltas) # 根据策略累积折扣回报和策略概率计算期望策略累积折扣期望,目标是最大化期望
最终效果:
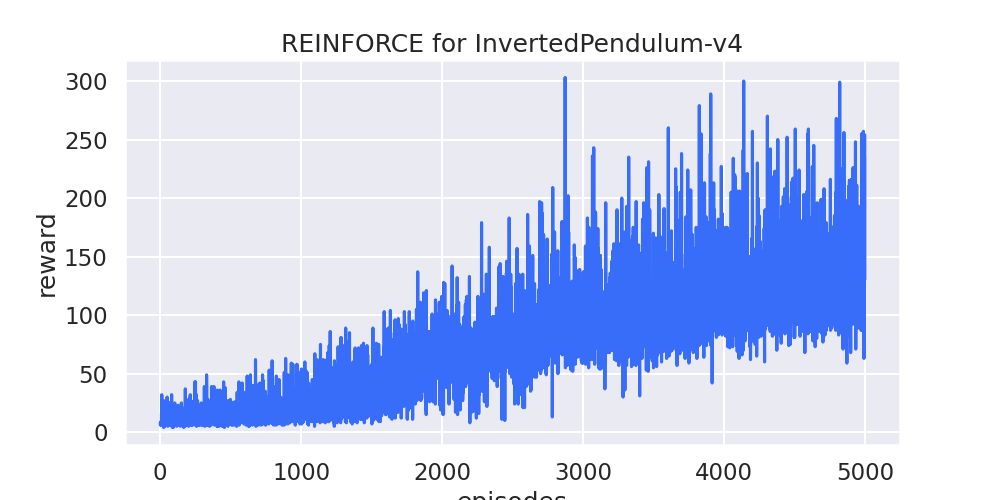
可以看出,
Agent在训练过程中逐渐学会了如何控制小车,使得倒立摆尽可能直立,训练5000步就可以将倒立摆稳定保持200时间步
4. 思考和尝试
- 由于长期做有监督深度学习项目,所以会思考:如果使用深度有监督学习模型来解决倒立摆问题,会有什么不同?
- 但直接使用深度有监督学习模型来解决倒立摆问题是不现实的,因为不管是用奖励计算损失还是用观测状态计算损失,都无法通过梯度反向传播来优化模型,因为环境并不可微
- 环境不可微 是强化学习和深度学习的根本区别之一,那么如何解决 “深度有监督学习无法解决倒立摆问题” 呢?
- 一个简单有效的方法是使用两个阶段的模型:
- 第一阶段:训练一个深度有监督学习模型,作为环境仿真器
- 输入:状态(观测)+ 随机动作
- 输出:预测的下一个状态 + 预测的奖励
- 监督:真实环境下,输入随机动作后的新状态和奖励
- 第二阶段:训练一个深度有监督学习模型,作为智能体
- 输入:状态(观测)
- 输出:动作
- 监督:环境仿真器(冻结)预测的下一个状态和奖励(目标是奖励尽可能高 且 立杆尽可能竖直 且 小车速度尽可能小 且 立杆线速度尽可能小)
- 第一阶段:训练一个深度有监督学习模型,作为环境仿真器
- 通过两个阶段的模型训练,可以将环境的不可微性质转化为可微性质,从而使用深度有监督学习模型来解决倒立摆问题
- 实现代码:
- 训练环境仿真器
1 | import random |
- 训练智能体
1 | import random |
- 最终效果:可以正常训练,也可以正常收敛,但效果远不如
REINFORCE算法
5. 总结
- 通过结合 REINFORCE 算法和倒立摆任务,本文展示了强化学习的基本原理和具体实现。
- 同时,提出了针对环境不可微问题的创新方法,即通过建立环境仿真器来将不可微问题转化为可微问题,从而使得深度学习能够在强化学习任务中发挥作用。
- 有监督学习和强化学习的对比:
- 二阶段有监督学习适合在已知环境模型的基础上,快速训练并优化策略,特别是离线学习和仿真场景。
- 强化学习则适用于更为复杂、不确定的环境,尤其是无法精确建模的动态场景,并且可以在实时交互中自我改进。