0%
URL
TL;DR
- 本文是上手训练大模型系列的第二篇,透过
LlamaFactory 视角审视大模型微调全流程,包括:SFT、RLHF、DPO。
LlamaFactory 是目前社区内最受欢迎的开源的大模型全流程微调工具,用低代码的方式支持 100+ 大模型微调任务。LlamaFactory 集成了 Pytorch、transformers、TRL、PEFT 等主流框架。
分层看待大模型微调
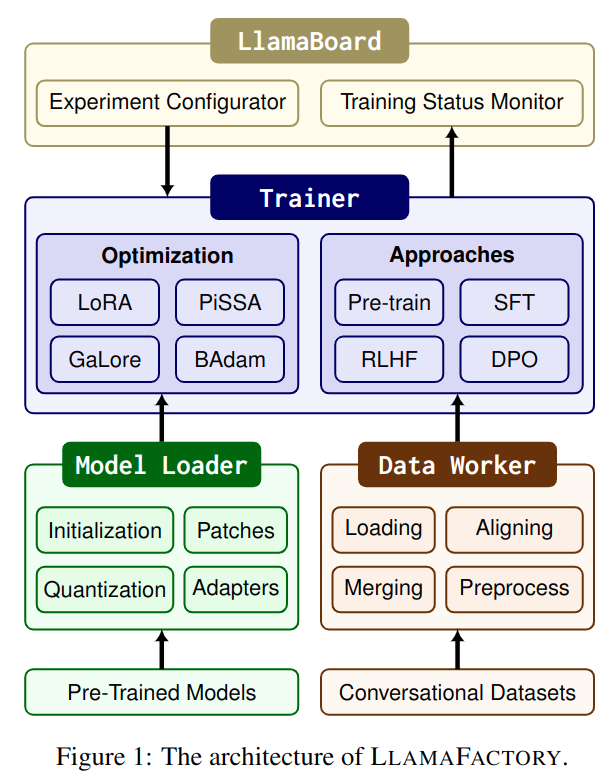
LlamaFactory 认为,大模型微调框架主要由三部分组成:
Model loader:负责操纵大模型完成微调任务,模型结构包括 Large Language Model、Vision Language Model 等。Data worker:通过精心设计的数据处理流程,处理不同任务的数据,并支持单轮、多轮对话。Trainer:实施不同的训练/微调策略和方法。
Model loader
Model loader 主要分为五个部分:
- 模型初始化:用
transformers 库加载预训练模型,具体来说:
- 用
AutoModelForVision2Seq 加载 VLM 模型
- 用
AutoModelForCausalLM 加载其他类型的模型
- 用
AutoTokenizer 加载 tokenizer
- 对于词表大小超过
embedding 层尺寸的模型,需要对 embedding 层进行 resize,并填充噪声
- 处理
RoPE 的 scaling factor
- 模型修补:适配不同代码结构,包括:
- S2
attention:用 Monkey Patching 方式实现
flash attention:用 transformers 库实现MoE:为了防止 DeepSpeed ZeRO stage-3 过度分配动态层,将 MoE 层设置为叶子模块
- 模型量化:
- 用
LLM.int8() 动态量化到 4 / 8 bits 可以由 bitsandbytes 库实现
- 对于
4bits 量化,用 QLoRA 中的 NF4 数据类型 + 两次量化
- 支持由
GPTQ / AWQ / AQLM 等量化方法 PTQ 量化后的模型的微调,但只支持 Adapter-base 的微调而不是 weight 直接微调
- 附加适配器:
PEFT 库提供了非常方便的适配器添加方法,例如 LoRA / rsLoRA / DoRA / PiSSA 等,只需要替换后端为 Unsloth 库做训练加速即可- 为了做
RLHF,需要在模型 head 层添加一个 value head,将每一个 token 映射为一个标量值
- 精度自适应:为不同的设备选择不同的精度类型,例如:
- 对于
NVIDIA 设备,如果计算能力大于 8.0,可以选择 BF16 (Brain Float 16) 精度(这里的计算能力是 NVIDIA 标记 GPU 硬件功能的指标,A100 GPU 计算能力是 8,H100 GPU 计算能力是 8.9),否则选择 FP16 精度
- 对于
NPU 或 AMD GPU 设备,可以选择 FP16 精度
- 对于没有
CUDA 的设备,需选择 FP32 精度
- 对于混合精度训练,强制所有可训练参数类型为
FP32,目的是为了训练的稳定性
- 对于半精度训练,则设置所有可训练参数类型为
BF16 (Brain Float 16)
Data worker
Data worker 主要由四部分组成:
- 数据加载:用
HuggingFace 开源的 Datasets 库加载数据集,这个库支持远程数据读取或本地数据读取,并采用 Arrow 格式存储数据,大幅降低数据的存储开销
- 数据对齐:将不同数据集类型(例如:
Plain text,Alpaca-like data,ShareGPT-like data)对齐到标准格式(LLAMAFACTORY 定义)

- 数据合并:数据合并是将不同的数据集合并到一起,由于数据已经对齐,所以合并相对容易
- 对于非流式数据,可以直接在
shuffle 之前合并
- 对于流式数据,需要在不同数据集之间交替读取
- 数据预处理:
- 目前大模型的主要应用方向是
Chat,因此 LLAMAFACTORY 提供了许多 Chat template,可自动化根据模型类型匹配对应的模板。
- 默认只对生成内容监督,不监督
prompt (典型 SFT 模式)
- 可选用
Squence packing 技术,将多组训练数据打包成一个 batch,提高训练效率
Trainer
- 高效训练:
- 支持多种微调方法,包括:
LoRA / LoRA+ / Galore / BAdam 等
- 使用
transformers 库做 pre-train 和 SFT
- 使用
TRL 库做 RLHF 和 DPO,以及高级表现优化方法(例如:KTO / ORPO 等),并为这些算法提供了特殊的数据整理流程(通常需要 2n 个样本,其中 n 个 chosen examples 和 n 个 reject examples)
- 模型共享的 RLHF
- 传统
RLHF 过程非常复杂,因为需要四个模型:
Policy model / Base model:用于生成 action,是待优化的模型Reward model:用于评估 action 的好坏,由人类偏好数据训练,输入是策略模型的回答或一对 chosen / reject 回答,输出是一个分数或更优回答的类别Reference model / Frozen model:基准模型,是 Policy model 的冻结副本,用于计算策略模型的优势,即奖励信号需要减去基准奖励,以减少训练的不稳定性Value model / Critic model:评估策略模型的预期回报,输入是环境状态(即用户输入)和策略模型的回答,输出是预期的回报,可以和策略模型共享参数也可以是单独的模型
- 本文提出一种四合一的
RLHF 架构,具体步骤如下:
- 在
SFT 模型基础上添加要给 Adapter 得到 Policy model
- 在
SFT 模型上添加一个 Adapter,并将自带的 Vocab head 替换为输出标量的 Value head,在人类偏好数据上训练,得到 Reward model
- 在
Policy model 的基础上替换替换 Vocab head 为一个输出标量的 Value head 其他参数和 Policy model 共享,得到 Value model
- 再结合冻结的
SFT 模型作为 Reference model
- 即:
- 策略模型:
SFT model + Adapter 1
- 价值模型:
SFT model + Adapter 1 + Value head 1 (除了 head 之外都和策略模型完全共享)
- 奖励模型:
SFT model + Adapter 2 + Value head 2
- 基准模型:
SFT model
- 这里提到的
Adapter 可理解为 LoRA 等适配器训练得到的一组参数,附加在原始模型参数上,在 PEFT 库中可用 set_adapter / disable_adapter 等方法灵活控制
- 分布式训练:主要借助
DeepSpeed 库实现
其他部分
- 模型推理:用
transformers 和 vLLM 库实现
- 模型评估:支持多选任务(例如:
MMLU / CMMLU / C-Eval)和计算文本相似度分数任务(例如:BLEU-4 / ROUGE)
Thoughts
LLAMAFACTORY 主要面向大模型微调而不是预训练,确实做了很多工程化的工作,使得不同预训练模型 + 不同数据集 + 不同微调方法的组合变得更加容易,github 上恐怖的 star 数也是有目共睹- 虽然是基于多个基础库的封装,但想要做到如此必须有及其广阔的大模型知识面以及对其进行抽象的能力,这一点是难得可贵的
- 不过随着大模型范式的不断更新,维护一套这样的工程是非常有挑战性的