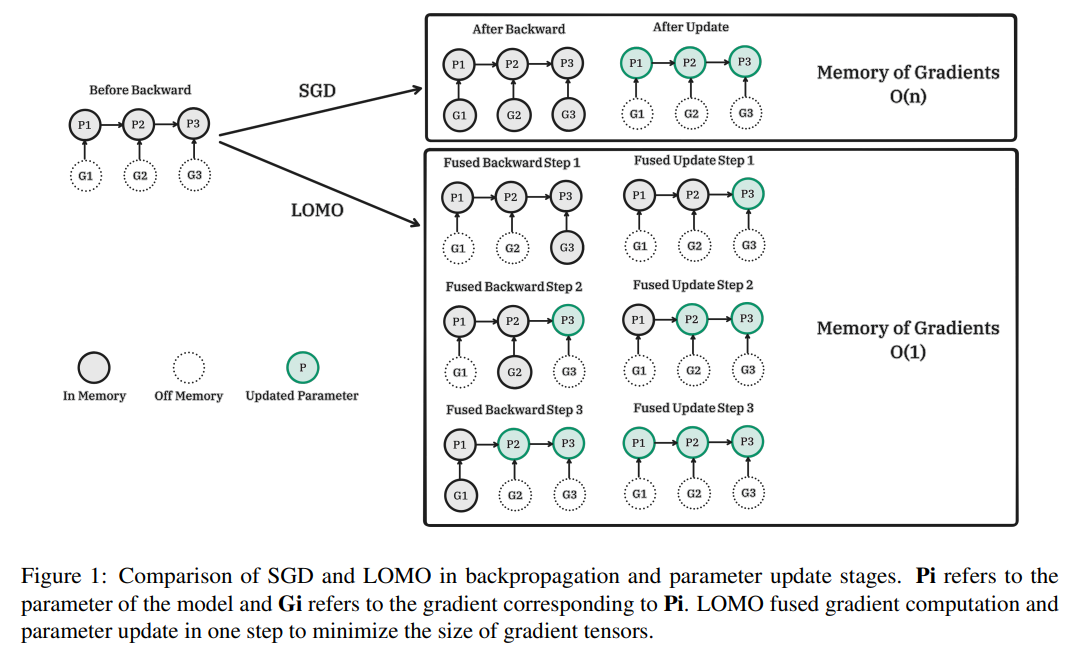
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
| class LOMO(Optimizer):
"""
一个自定义的优化器类LOMO,用于在分布式训练中的梯度更新。
该类实现两个梯度更新函数 :meth:`fuse_update` 和 :meth:`fuse_update_zero3`,分别用于非ZeRO和ZeRO模式下的梯度更新。
:param model: 待优化的模型
:param lr: 学习率,默认值为1e-3
:param clip_grad_norm: 梯度裁剪的范数阈值
.. note::
clip_grad_norm须为正数
:param clip_grad_value: 梯度裁剪的值域阈值
"""
def __init__(self, model, lr=1e-3, clip_grad_norm=None, clip_grad_value=None):
self.model = model
self.lr = lr
self.local_rank = int(os.environ["LOCAL_RANK"])
self.world_size = dist.get_world_size()
self.clip_grad_norm = clip_grad_norm
self.clip_grad_value = clip_grad_value
if self.clip_grad_norm is not None and self.clip_grad_norm <= 0:
raise ValueError(
f"clip_grad_norm should be positive, got {self.clip_grad_norm}."
)
self.gather_norm = False
self.grad_norms = []
self.clip_coef = None
p0 = list(self.model.parameters())[0]
if hasattr(p0, "ds_tensor"):
self.grad_func = self.fuse_update_zero3()
else:
self.grad_func = self.fuse_update()
if p0.dtype == torch.float16:
self.loss_scaler = DynamicLossScaler(
init_scale=2 ** 16,
)
if self.clip_grad_norm is None:
raise ValueError(
"Loss scaling is recommended to be used with grad norm to get better performance."
)
else:
self.loss_scaler = None
for n, p in self.model.named_parameters():
if p.requires_grad:
p.register_hook(self.grad_func)
defaults = dict(
lr=lr, clip_grad_norm=clip_grad_norm, clip_grad_value=clip_grad_value
)
super(LOMO, self).__init__(self.model.parameters(), defaults)
def fuse_update(self):
"""
在非ZeRO模式下更新模型参数的梯度。
:return: func,一个闭包函数,用于更新模型参数的梯度
"""
def func(x):
"""
闭包函数,用于更新模型参数的梯度。
"""
with torch.no_grad():
for n, p in self.model.named_parameters():
if p.requires_grad and p.grad is not None:
if self.loss_scaler:
if (
self.loss_scaler.has_overflow_serial
or self.loss_scaler._has_inf_or_nan(p.grad)
):
p.grad = None
self.loss_scaler.has_overflow_serial = True
break
grad_fp32 = p.grad.to(torch.float32)
p.grad = None
if self.loss_scaler:
grad_fp32.div_(self.loss_scaler.loss_scale)
if self.gather_norm:
self.grad_norms.append(torch.norm(grad_fp32, 2.0))
else:
if (
self.clip_grad_value is not None
and self.clip_grad_value > 0
):
grad_fp32.clamp_(
min=-self.clip_grad_value, max=self.clip_grad_value
)
if (
self.clip_grad_norm is not None
and self.clip_grad_norm > 0
and self.clip_coef is not None
):
grad_fp32.mul_(self.clip_coef)
p_fp32 = p.data.to(torch.float32)
p_fp32.add_(grad_fp32, alpha=-self.lr)
p.data.copy_(p_fp32)
return x
return func
def fuse_update_zero3(self):
"""
在ZeRO模式下更新模型参数的梯度。
:return: func,一个闭包函数,用于更新模型参数的梯度。
"""
def func(x):
with torch.no_grad():
for n, p in self.model.named_parameters():
if p.grad is not None:
torch.distributed.all_reduce(
p.grad, op=torch.distributed.ReduceOp.AVG, async_op=False
)
if self.loss_scaler:
if (
self.loss_scaler.has_overflow_serial
or self.loss_scaler._has_inf_or_nan(p.grad)
):
p.grad = None
self.loss_scaler.has_overflow_serial = True
break
grad_fp32 = p.grad.to(torch.float32)
p.grad = None
param_fp32 = p.ds_tensor.to(torch.float32)
if self.loss_scaler:
grad_fp32.div_(self.loss_scaler.loss_scale)
if self.gather_norm:
self.grad_norms.append(torch.norm(grad_fp32, 2.0))
else:
one_dim_grad_fp32 = grad_fp32.view(-1)
partition_size = p.ds_tensor.numel()
start = partition_size * self.local_rank
end = min(start + partition_size, grad_fp32.numel())
partitioned_grad_fp32 = one_dim_grad_fp32.narrow(
0, start, end - start
)
if self.clip_grad_value is not None:
partitioned_grad_fp32.clamp_(
min=-self.clip_grad_value, max=self.clip_grad_value
)
if (
self.clip_grad_norm is not None
and self.clip_grad_norm > 0
and self.clip_coef is not None
):
partitioned_grad_fp32.mul_(self.clip_coef)
partitioned_p = param_fp32.narrow(0, 0, end - start)
partitioned_p.add_(partitioned_grad_fp32, alpha=-self.lr)
p.ds_tensor[: end - start] = partitioned_p
return x
return func
def fused_backward(self, loss, lr):
"""
执行一步反向传播并更新模型的梯度(真正计算梯度和更新参数)。
:param loss: 模型的loss值
:param lr: 学习率
"""
self.lr = lr
if (
self.clip_grad_norm is not None
and self.clip_grad_norm > 0
and self.clip_coef is None
):
raise ValueError(
"clip_grad_norm is not None, but clip_coef is None. "
"Please call optimizer.grad_norm() before optimizer.fused_backward()."
)
if self.loss_scaler:
loss = loss * self.loss_scaler.loss_scale
loss.backward()
self.grad_func(0)
def grad_norm(self, loss):
"""
计算梯度的范数(虽然做了一次 forward + backward,但实际上只是用于计算梯度的范数,后续做 clip grad norm 用)。
:param loss: 模型的loss值
"""
self.gather_norm = True
self.grad_norms = []
if self.loss_scaler:
self.loss_scaler.has_overflow_serial = False
loss = loss * self.loss_scaler.loss_scale
loss.backward(retain_graph=True)
self.grad_func(0)
if self.loss_scaler and self.loss_scaler.has_overflow_serial:
self.loss_scaler.update_scale(overflow=True)
with torch.no_grad():
for n, p in self.model.named_parameters():
p.grad = None
return
with torch.no_grad():
self.grad_norms = torch.stack(self.grad_norms)
total_norm = torch.norm(self.grad_norms, 2.0)
self.clip_coef = float(self.clip_grad_norm) / (total_norm + 1e-6)
self.clip_coef = torch.clamp(self.clip_coef, max=1.0)
self.gather_norm = False
|